Spark编程范例:Word Count示例解析
Apache Spark是一个强大的分布式计算框架,用于处理大规模数据。Word Count示例是Spark入门教程中的经典示例,旨在展示如何使用Spark来进行简单的文本处理和数据分析。本文将深入解析Word Count示例,以帮助大家更好地理解Spark的基本概念和编程模型。 什么是Word C...
DataWorks使用spark读取maxcomputer的表进行count的时候为什么报错?
DataWorks使用spark读取maxcomputer的表进行count的时候为什么报错,unsupported type?

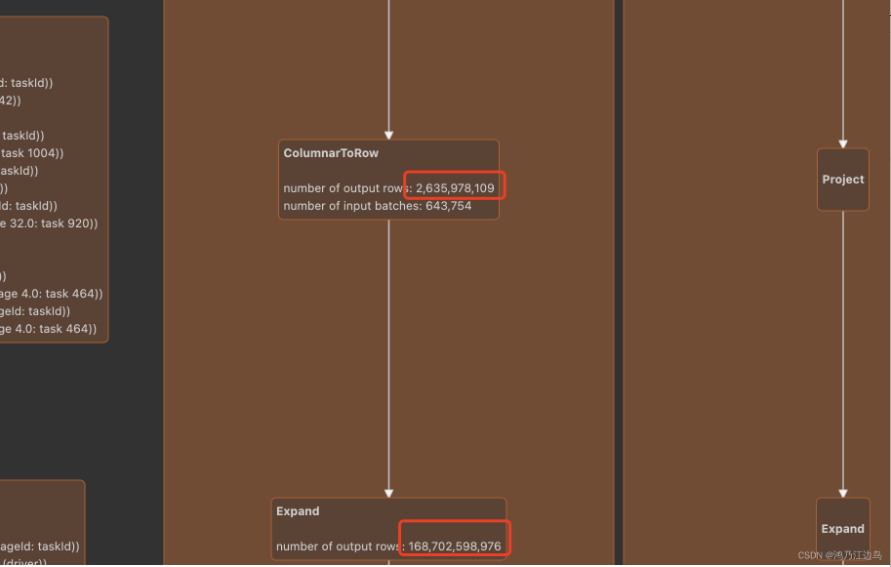
SPARK Expand问题的解决(由count distinct、group sets、cube、rollup引起的)
背景本文基于spark 3.1.2我们知道spark对于count(distinct)/group sets 以及cube、rollup的处理都是采用转换为Expand的方法处理,这样做的优点就是在数据量小的情况下,能有以空间换时间,从而达到加速的目的。但是弊端也是很明显,就是在数据量较大的情况下,...
Spark 系列教程(1)Word Count
基本概要Spark 是一种快速、通用、可扩展的大数据分析引擎,是基于内存计算的大数据并行计算框架。Spark 在 2009 年诞生于加州大学伯克利分校 AMP 实验室,2010 年开源,2014 年 2月成为 Apache 顶级项目。本文是 Spark 系列教程的第一篇,通过大数据领域中的 "Hel...
Spark RDD中的count()方法和first()方法分别的作用是什么?
Spark RDD中的count()方法和first()方法分别的作用是什么?
spark的action算子collect()和count()的功能是什么?
spark的action算子collect()和count()的功能是什么?
如何在Spark中实现Count Distinct重聚合
背景 Count Distinct是SQL查询中经常使用的聚合统计方式,用于计算非重复结果的数目。由于需要去除重复结果,Count Distinct的计算通常非常耗时。 以如下查询为例,Count Distinct的实现方式主要有两种: SELECT region, COUNT(DISTINCT u...
Spark Streaming和Flink的Word Count对比
准备: nccat for windows/linux 都可以 通过 TCP 套接字连接,从流数据中创建了一个 Spark DStream/ Flink DataSream, 然后进行处理, 时间窗口大小为10s 因为 示例需要, 所以 需要下载一个netcat, 来构造流的输入...
Spark sc.textFile(...).map(...).count() 执行完整流程
引子 今天正好有人在群里问到相关的问题,不过他的原始问题是: 我在RDD里面看到很多 new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF)),但是我找不到context是从哪里来的 另外还...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark更多count相关
apache spark您可能感兴趣
- apache spark分析
- apache spark数据
- apache spark数据库
- apache spark可视化分析
- apache spark决策
- apache spark可视化
- apache spark Mapreduce
- apache spark SQL
- apache spark Python
- apache spark决策树
- apache spark streaming
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark任务
- apache spark程序