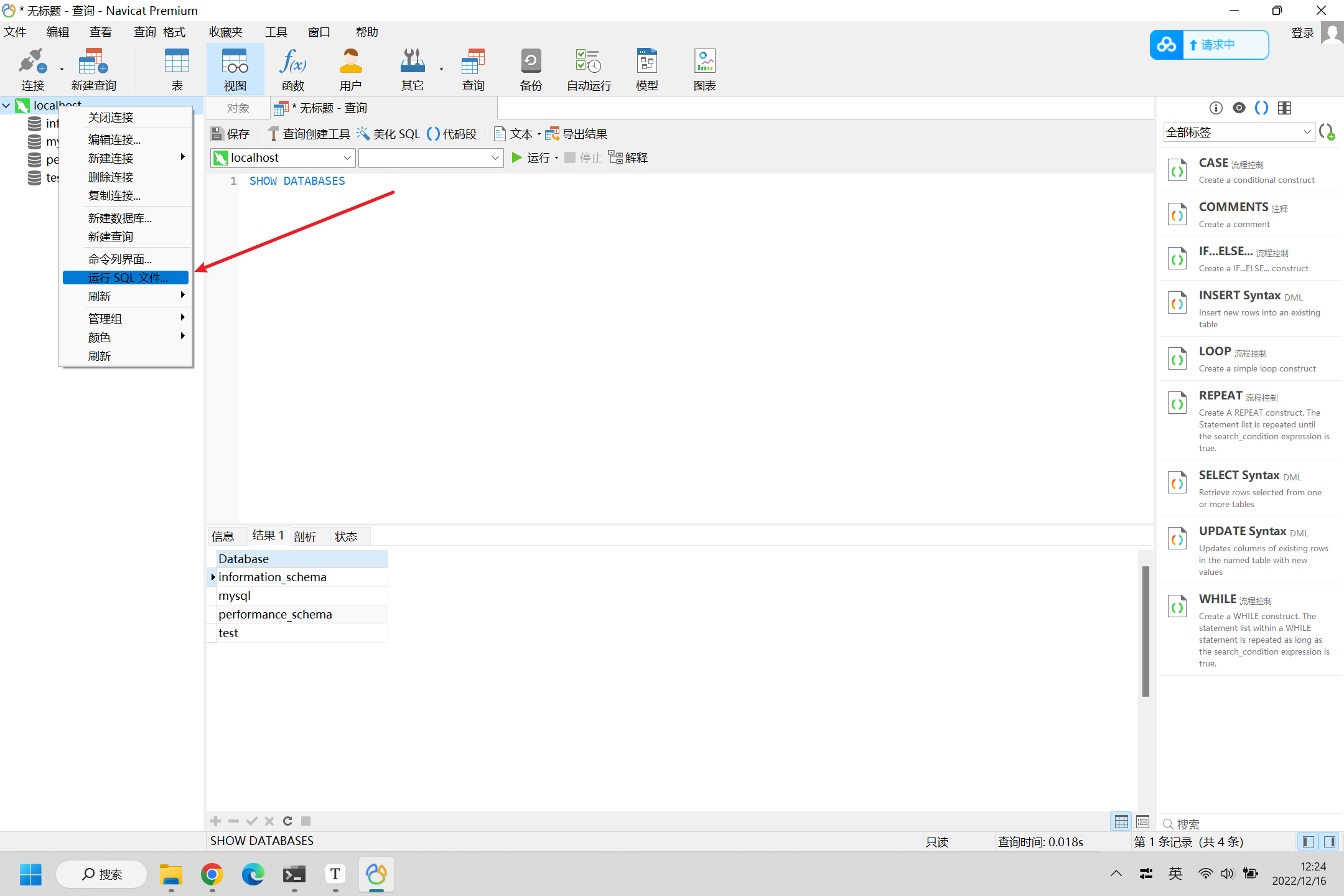
【大数据系列之MySQL】(十):使用Navicat运行本地sql文件
有时我们需要使用MySQL进行建库、建表等操作,如果使用手动方式这样会耗时耗力,这时我们可以使用执行sql文件的方式,如下:1.右键MySQL连接右键我们的数据库连接,会出现运行sql文件这个选项,点击它2.指定sql文件找到给定的sql文件,然后点击开始即可如果出现下图样式,即代表成...
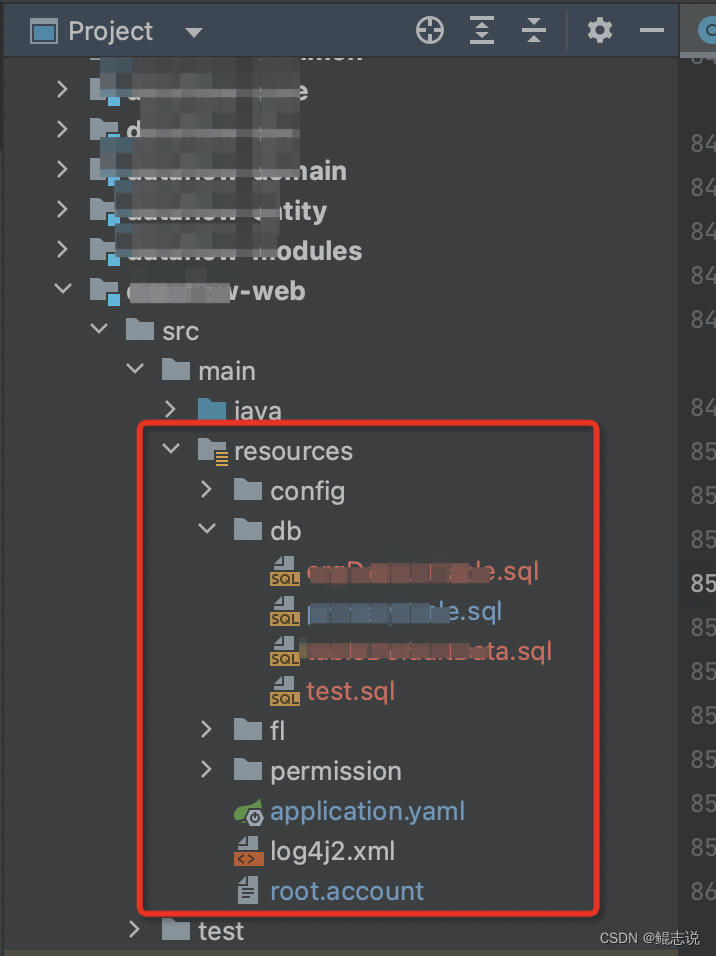
springboot-maven项目+jpa 运行过程中执行resources下sql脚本文件-ClassPathResource和ScriptUtils.executeSqlScript的使用
要完成上述需求,需要分两步操作获取resources目录下的sql脚本文件执行该文件获取resources目录下的sql脚本文件一般来说,项目的配置文件及静态资源都会放置在resources目录下。如下图当需要在java代码中使用resources目录下的文件时,就需要先获取该文件了以获取上图tes...

我用运行flink sql作业:flink kafka conector->hudi->hive,对
我用运行flink sql作业:flink kafka conector->hudi->hive,对于同一个topic里的数据,为何多次启动这个flink作业,最后hive count出来的数据条数每次都不一样(少于topic里的实际数据量)?
Dataworks中的shell节点如何运行SQL
Dataworks中的shell节点如何运行SQL
MaxCompute的SDK如何运行SQL字符串
MaxCompute的SDK如何运行SQL字符串
adb的这个后台查询正在运行的sql,这个查出来的完全是乱的咋回事?
adb的这个后台查询正在运行的sql,这个查出来的完全是乱的咋回事?
运行sql任务报错:{SqlTask=ODPS-0110061: Failed to run ddl
运行sql任务报错:{SqlTask=ODPS-0110061: Failed to run ddltask - Modify DDL meta encounter exception : ODPS-0123031:ODPS partition exception - maximum 60000 p...

Navicat Premium导出数据库中的结构及数据及运行SQL文件
@[TOC]0 写在前面最近跟小伙伴分享了一下数据库,所以记录一下当时的操作。利用Navicat Premium导出数据库中的结构及数据利用Navicat Premium执行数据库中的结构及数据本文以Navicat Premium15为例1 导出SQL文件打开Navicat Premium选择要导出...
使用flink1.14.0 使用mongo connector 2.3 运行sql语句报错提示,咋办
使用flink1.14.0 使用mongo connector 2.3 运行sql语句报错提示,咋办
Flink更改正在运行SQL作业逻辑重新运行对作业有影响吗
Flink更改正在运行SQL作业逻辑重新运行对作业有影响吗
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子




最佳实践




