K-means聚类算法是如何实现的?
K-means聚类算法的实现步骤如下: 初始化:选择K个初始质心(centroid),可以随机选择数据集中的K个数据点作为初始质心,或者使用其他方法进行初始化。分配数据点到最近的质心:计算每个数据点到各个质心的距离,将数据点分配到距离最近的质心所在的簇。更新质心:对于每个...
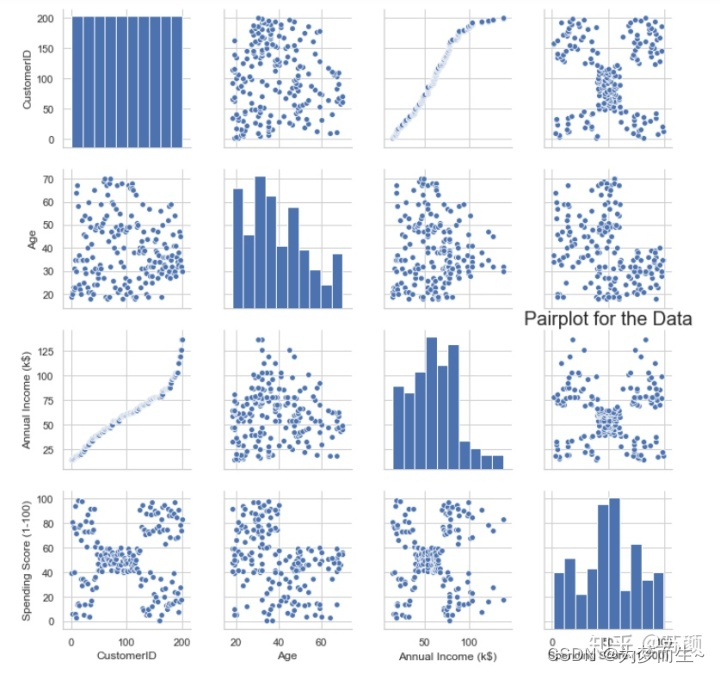
请解释Python中的K-means聚类算法以及如何使用Sklearn库实现它。
K-means聚类是一种无监督学习算法,用于将数据点划分为K个不同的簇(cluster)。每个簇内的数据点彼此相似,而不同簇之间的数据点则具有较大的差异。K-means算法的目标是最小化每个簇内数据点与其质心(centroid)之间的距离之和。 在Python中,可以使用Sklearn库来实现K-m...

使用phyon实现K-means聚类算法
K-means聚类算法是一种常见的无监督学习算法,用于将数据集分成K个簇。以下是K-means聚类算法的原理: ### K-means聚类算法原理: 1. **初始化**:随机选择K个点作为初始质心(centroid)。 2. **分配数据点**:对于每个数...
从K-means到高斯混合模型:常用聚类算法的优缺点和使用范围?
一、引言 聚类算法是一种无监督学习方法,旨在将相似的数据点分组成为若干个簇,使得同一簇内的数据点相似度高,不同簇之间的相似度低。聚类算法在数据挖掘、模式识别、图像分析等领域具有重要应用。 聚类算法的作用在于发现数据的内在结构和规律,将数据进行分组,从而帮助我们理解数据的特征和相互关系。聚类可以用于数...
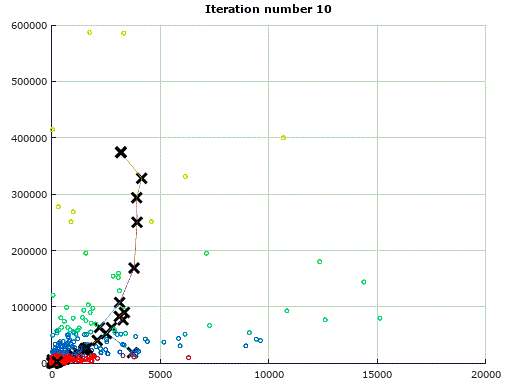
基于K-means Clustering聚类算法对电商商户进行级别划分(含Octave仿真)
在从事电商做频道运营时,每到关键时间节点,大促前,季度末等等,我们要做的一件事情就是品牌池打分,更新所有店铺的等级。例如,所以的商户分入SKA,KA,普通店铺,新店铺这4个级别,对于不同级别的商户,会给予不同程度的流量扶持或广告策略。通常来讲,在一定时间段内,...

K-means聚类算法
聚类属于无监督学习,以往的回归、朴素贝叶斯、SVM等都是有类别标签y的,也就是说样例中已经给出了样例的分类。而聚类的样本中却没有给定y,只有特征x,比如假设宇宙中的星星可以表示成三维空间中的点集。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个...
【机器学习基础】K-Means聚类算法
1 聚类算法分析概述近几年,随着网络的发展,越来越多的人开始习惯于在网上找信息,而网络也逐渐地走进了人们的日常生活。从人们每天都会接触到大量的数据,比如文字、音乐、图像、视频等等。随着信息的增多,人工智能应运而生。而在人工智能这个概念中,机器学习尤为重要,是实现人工智能的基础。机器学习,...

【图像聚类】基于K-means聚类算法路标识别与提取附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,matlab项目合作可私信。🍎个人主页:Matlab科研工作室🍊个人信条:格物致知。更多Matlab仿真内容点击👇智能优化算法 神经网络预测 雷...

K-Means(K-均值)聚类算法理论和实战
K-Means 算法对于 n 个样本点来说,根据距离公式(如欧式距离)去计 算它们的远近,距离越近越相似。按照这样的规则,我们把它们划分到 K 个类别中,让每个类别中的样本点都是最相似的。优点:属于无监督学习,无须准备训练集原理简单,实现起来较为容易结果可解释性较好缺点:需手动设置k值.....

k-means聚类算法
1 聚类算法说明 1.1 1. 引入聚类算法一种无监督的(unsupervised)经典机器学习算法。先从感性上认识一下什么是聚类。聚 类的核心思想就是将具有相似特征的事物给 “聚” 在一起,也就是说 “聚” 是一个动词。俗话说 人以群分,物以类聚说得就是这个道理。如图所示为三种类型的数据...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









