[帮助文档] 迁移Hadoop集群至DataLake集群
本文将详细阐述如何将您已有的旧版数据湖集群(Hadoop),高效地迁移至数据湖集群(DataLake),以下分别简称“旧集群”和“新集群”。迁移过程将充分考虑旧集群的版本、元数据类型以及存储方式,并针对这些因素,提供适应新集群的迁移策略与步骤。
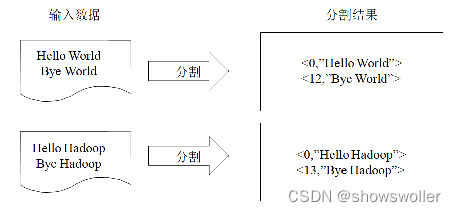
【大数据技术Hadoop+Spark】MapReduce之单词计数和倒排索引实战(附源码和数据集 超详细)
源码和数据集请点赞关注收藏后评论区留言私信~~~一、统计单词出现次数单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版“Hello World。其主要功能是统计一系列文本文件中每个单词出现的次数程序解析首先MapReduce将文件拆分成splits,由于测试用...

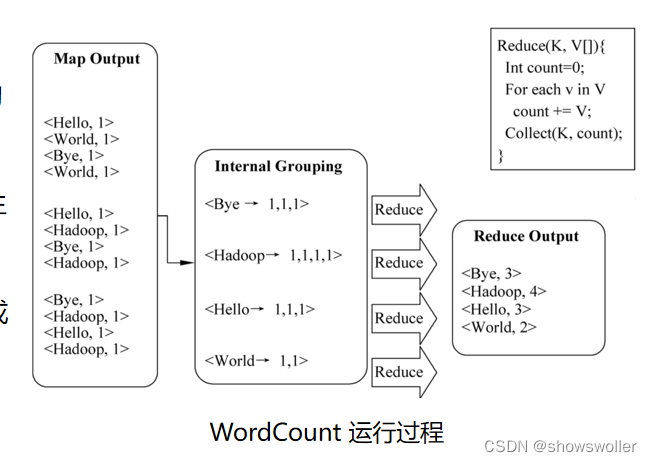
【云计算与大数据计算】Hadoop MapReduce实战之统计每个单词出现次数、单词平均长度、Grep(附源码 )
需要全部代码请点赞关注收藏后评论区留言私信~~~下面通过WordCount,WordMean等几个例子讲解MapReduce的实际应用,编程环境都是以Hadoop MapReduce为基础一、WordCountWordCount用于计算文件中每个单词出现的次数,非常适合采用MapReduce进行处理...
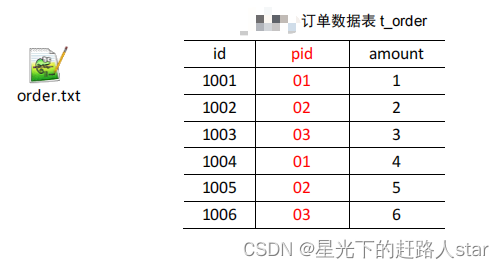
Hadoop学习---7、OutputFormat数据输出、MapReduce内核源码解析、Join应用、数据清洗、MapReduce开发总结(二)
3、Join应用3.1 Reduce Join(1)Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。(2)Reduce端的主要工作:在Reduce端以连接...
Hadoop学习---7、OutputFormat数据输出、MapReduce内核源码解析、Join应用、数据清洗、MapReduce开发总结(一)
1、OutputFormat数据输出1.1 OutputFormat接口实现类OutputFormat是MapReduce输出的基类,所以实现MapReduce输出都实现了OutputFormat接口。1、MapReduce默认的输出格式是TextOutputFormat2、也可以自定义Output...
[帮助文档] 如何管理SmartDataHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。
[帮助文档] 如何管理HDFSHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。
[帮助文档] 如何管理OSS/OSS-HDFSHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。
[帮助文档] 如何通过HadoopShell命令访问OSS和OSS-HDFS
本文为您介绍如何通过Hadoop Shell命令访问OSS和OSS-HDFS。

Hadoop中的MapReduce框架原理、切片源码断点在哪断并且介绍相关源码、FileInputFormat切片源码解析、总结,那些可以证明你看过切片的源码
@[toc]13.MapReduce框架原理13.1InputFormat数据输入13.1.3FileInputFormat切片源码解析13.1.3.1切片源码断点在哪断并且介绍相关源码:断点在https://blog.csdn.net/Redamancy06/article/details/126...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









hadoop mapreduce相关内容
- hadoop mapreduce分析
- hadoop mapreduce概念
- hadoop mapreduce编程
- 大数据技术hadoop mapreduce
- hadoop学习mapreduce
- hadoop学习笔记mapreduce
- hadoop mapreduce join
- hadoop mapreduce开发
- hadoop mapreduce框架
- hadoop学习mapreduce框架原理
- hadoop mapreduce框架原理
- hadoop知识点mapreduce
- hadoop mapreduce shuffle
- hadoop框架mapreduce
- hadoop mapreduce wordcount
- hadoop mapreduce案例
- hadoop学习mapreduce合并
- hadoop mapreduce spark
- hadoop分布式计算框架mapreduce
- hadoop分布式mapreduce
- hadoop快速入门mapreduce案例字符统计
- hadoop mapreduce流程
- hadoop mapreduce partitioner
- hadoop mapreduce框架原理机制
- hadoop mapreduce设置
- hadoop mapreduce job
- hadoop mapreduce进程
- hadoop yarn mapreduce
- hadoop序列化mapreduce案例
- 云计算hadoop版本生态圈mapreduce模型
- hadoop mapreduce模型
- hadoop mapreduce编程模型
- hadoop mapreduce配置项
- hadoop mapreduce程序
- hadoop mapreduce程序代码
- hadoop运行mapreduce程序
- hadoop mapreduce概念学习
- hadoop mapreduce实践
- hadoop mapreduce实践文件
- hadoop mapreduce开发实践分发streaming
- hadoop mapreduce参数
- hadoop mapreduce map原理
- hadoop计算mapreduce
- hadoop算法原理mapreduce实现
- hadoop大数据分析实战mapreduce
- hadoop mapreduce性能优化
- hadoop mapreduce性能优化参数
- hadoop mapreduce实战手册