
Hadoop【基础知识 02】【分布式计算框架MapReduce核心概念+编程模型+combiner&partitioner+词频统计案例解析与进阶+作业的生命周期】(图片来源于网络)
1. 概述 同 HDFS 一样,Hadoop MapReduce 也采用了 Master/Slave(M/S)架构,具体如图所示。它主要由以下几个组件组成:Client、JobTracker、TaskTracker 和 Task。 下面分别对这几个组件进行介绍。 Client 我们将编写的 MapR...
[帮助文档] 迁移Hadoop集群至DataLake集群
本文将详细阐述如何将您已有的旧版数据湖集群(Hadoop),高效地迁移至数据湖集群(DataLake),以下分别简称“旧集群”和“新集群”。迁移过程将充分考虑旧集群的版本、元数据类型以及存储方式,并针对这些因素,提供适应新集群的迁移策略与步骤。

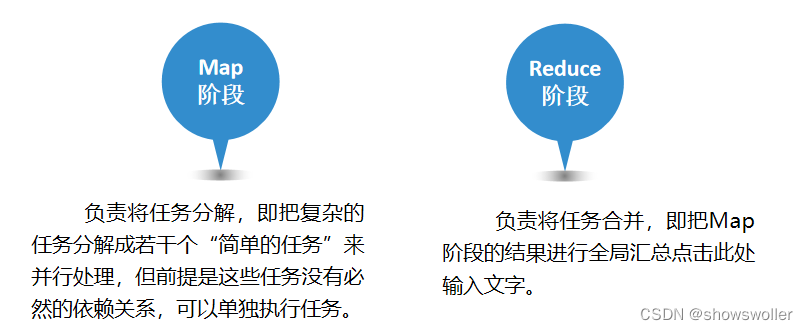
【大数据技术Hadoop+Spark】MapReduce概要、思想、编程模型组件、工作原理详解(超详细)
MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。一、MapReduce核心思想MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方...
[帮助文档] 如何管理SmartDataHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。
[帮助文档] 如何管理HDFSHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。
[帮助文档] 如何管理OSS/OSS-HDFSHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。
[帮助文档] 如何通过HadoopShell命令访问OSS和OSS-HDFS
本文为您介绍如何通过Hadoop Shell命令访问OSS和OSS-HDFS。
hadoop的mapreduce编程模型是什么?
hadoop的mapreduce编程模型是什么?
《深入理解Hadoop(原书第2版)》——2.2MapReduce编程模型简介
本节书摘来自华章计算机《深入理解Hadoop(原书第2版)》一书中的第2章,第2.2节,作者 [美]萨米尔·瓦德卡(Sameer Wadkar),马杜·西德林埃(Madhu Siddalingaiah),杰森·文纳(Jason Venner),译 于博,冯傲风,更多章节内容可以访问云栖社区“华章计算...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









hadoop mapreduce相关内容
- hadoop mapreduce作业
- hadoop分布式计算框架mapreduce
- hadoop mapreduce概念
- hadoop分布式mapreduce
- hadoop mapreduce partitioner
- hadoop mapreduce combiner
- hadoop mapreduce概念作业
- hadoop mapreduce词频统计
- hadoop mapreduce案例
- hadoop框架mapreduce
- hadoop mapreduce编程
- hadoop mapreduce模型
- hadoop mapreduce概念模型
- hadoop mapreduce分析
- hadoop mapreduce hive
- hadoop mapreduce源码
- 大数据技术hadoop mapreduce
- hadoop学习mapreduce
- hadoop学习笔记mapreduce
- hadoop mapreduce join
- hadoop mapreduce开发
- hadoop mapreduce框架
- hadoop mapreduce框架原理
- hadoop学习mapreduce框架原理
- hadoop知识点mapreduce
- hadoop mapreduce shuffle
- hadoop mapreduce wordcount
- hadoop mapreduce wordcount案例
- hadoop学习mapreduce合并
- hadoop mapreduce spark
- hadoop快速入门mapreduce案例字符统计
- hadoop mapreduce流程
- hadoop mapreduce框架原理机制
- hadoop mapreduce设置
- hadoop mapreduce job
- hadoop mapreduce进程
- hadoop mapreduce序列化案例实操
- hadoop yarn mapreduce
- hadoop序列化mapreduce案例
- 云计算hadoop版本生态圈mapreduce模型
- hadoop mapreduce配置项
- hadoop mapreduce程序
- hadoop mapreduce程序代码
- hadoop运行mapreduce程序
- mapreduce hadoop参数
- hadoop mapreduce概念学习
- hadoop mapreduce格式
- hadoop mapreduce学习作业
hadoop更多mapreduce相关
- hadoop mapreduce实战手册
- hadoop mapreduce性能优化
- hadoop mapreduce实践
- hadoop大数据分析实战mapreduce
- eclipse运行mapreduce hadoop
- hadoop mapreduce实战手册datanode
- hadoop计算mapreduce
- hadoop mapreduce性能优化参数
- hadoop mapreduce实战手册运行
- hadoop mapreduce map原理
- hadoop mapreduce实战手册设置
- hadoop mapreduce实践文件
- hadoop mapreduce实战手册分布式集群
- hadoop框架mapreduce模式中谈海量数据处理
- hadoop算法原理mapreduce实现
- hadoop mapreduce特性
- hadoop mapreduce参数
- hadoop mapreduce开发实践分发streaming
- hadoop mapreduce实战手册简介