[帮助文档] 迁移Hadoop集群至DataLake集群
本文将详细阐述如何将您已有的旧版数据湖集群(Hadoop),高效地迁移至数据湖集群(DataLake),以下分别简称“旧集群”和“新集群”。迁移过程将充分考虑旧集群的版本、元数据类型以及存储方式,并针对这些因素,提供适应新集群的迁移策略与步骤。
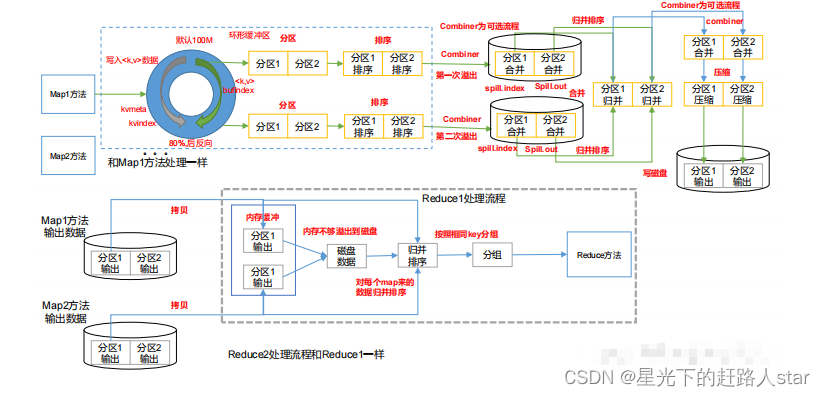
Hadoop基础学习---6、MapReduce框架原理(二)
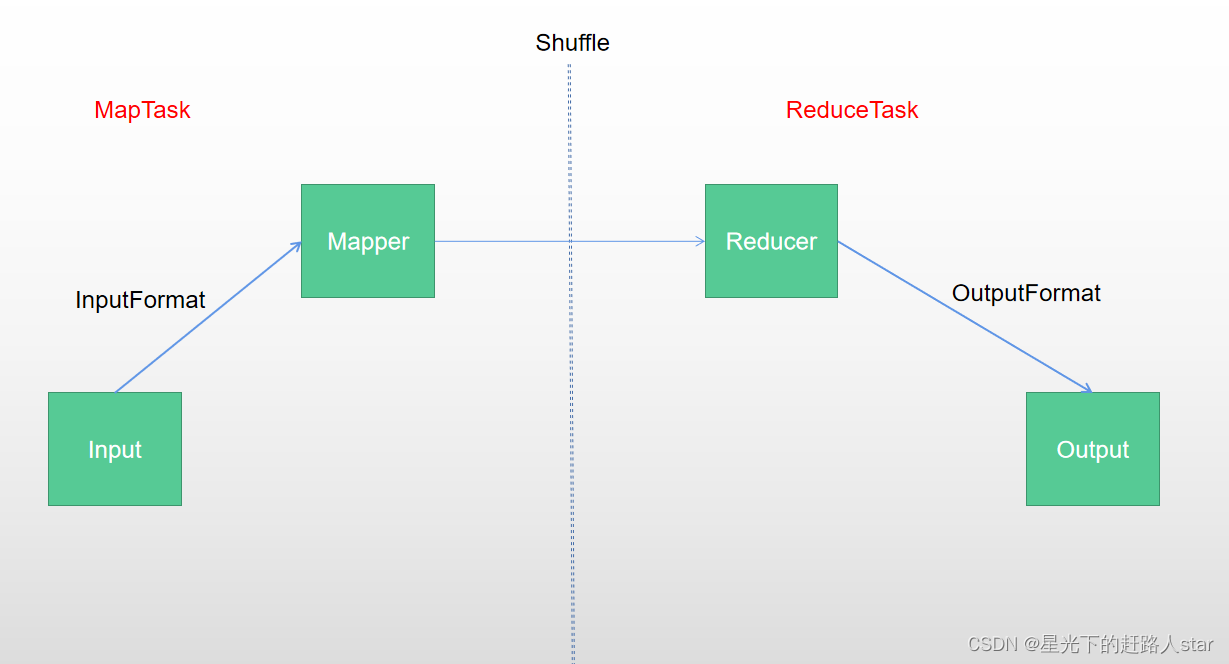
1.3 Shuffle机制1.3.1 Shuffle机制Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。1.3.2 Partition1、问题引出要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照收集归属地不同省份输出到不同文件中。2、默认Partition...

Hadoop基础学习---6、MapReduce框架原理(一)
1、MapReduce框架原理1.1 InputFormat数据输入1.1.1 切片与MapTask并行度决定机制1、问题引出MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个job的处理速度。2、MapTask并行度决定机制数据块:Block是HDFS物理上吧数据分成一块一块。数...
[帮助文档] 如何管理SmartDataHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。
[帮助文档] 如何管理HDFSHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。
[帮助文档] 如何管理OSS/OSS-HDFSHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。
[帮助文档] 如何通过HadoopShell命令访问OSS和OSS-HDFS
本文为您介绍如何通过Hadoop Shell命令访问OSS和OSS-HDFS。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









hadoop mapreduce相关内容
- hadoop mapreduce分析
- hadoop mapreduce概念
- hadoop mapreduce源码
- hadoop mapreduce编程
- 大数据技术hadoop mapreduce
- hadoop学习mapreduce
- hadoop学习笔记mapreduce
- hadoop mapreduce join
- hadoop mapreduce开发
- hadoop mapreduce框架
- hadoop mapreduce框架原理
- hadoop知识点mapreduce
- hadoop mapreduce shuffle
- hadoop框架mapreduce
- hadoop mapreduce wordcount
- hadoop mapreduce案例
- hadoop学习mapreduce合并
- hadoop mapreduce spark
- hadoop分布式计算框架mapreduce
- hadoop分布式mapreduce
- hadoop快速入门mapreduce案例字符统计
- hadoop mapreduce流程
- hadoop mapreduce partitioner
- hadoop mapreduce框架原理机制
- hadoop mapreduce设置
- hadoop mapreduce job
- hadoop mapreduce进程
- hadoop yarn mapreduce
- hadoop序列化mapreduce案例
- 云计算hadoop版本生态圈mapreduce模型
- hadoop mapreduce模型
- hadoop mapreduce编程模型
- hadoop mapreduce配置项
- hadoop mapreduce程序
- hadoop mapreduce程序代码
- hadoop运行mapreduce程序
- hadoop mapreduce概念学习
- hadoop mapreduce实践
- hadoop mapreduce实践文件
- hadoop mapreduce开发实践分发streaming
- hadoop mapreduce参数
- hadoop mapreduce map原理
- hadoop计算mapreduce
- hadoop算法原理mapreduce实现
- hadoop大数据分析实战mapreduce
- hadoop mapreduce性能优化
- hadoop mapreduce性能优化参数
- hadoop mapreduce实战手册