表格存储 Tablestore SQL 商业版介绍
表格存储(Tablestore)是阿里云自研的多模型结构化数据存储,提供海量结构化数据存储以及快速的查询和分析服务。表格存储的分布式存储和强大的索引引擎能够支持 PB 级存储、千万 TPS 以及毫秒级延迟的服务能力。使用表格存储你可以方便的存储和查询你的海量数据。表格存储在 21 年 9 月正式公测...
在一般数据检索需求上,Tablestore SQL和MySQL 的性能区别是什么?
在一般数据检索需求上,Tablestore SQL和MySQL 的性能区别是什么?

Tablestore 共有哪些方式支持SQL对于Tablestore中数据的读写?
Tablestore 共有哪些方式支持SQL对于Tablestore中数据的读写?
从哪里可以表明Tablestore SQL 性能远高于MySQL?
从哪里可以表明Tablestore SQL 性能远高于MySQL?

使用 Flink SQL 访问 Tablestore 源表
本文将介绍如何使用使用 Flink SQL 通过流处理的方式访问 Tablestore 源表。 在流计算场景下,用户可以基于通道服务,利用CDC(数据变更捕获)技术,通过 Flink 完成流式消费和计算。 Flink on Tablestore 可以提...
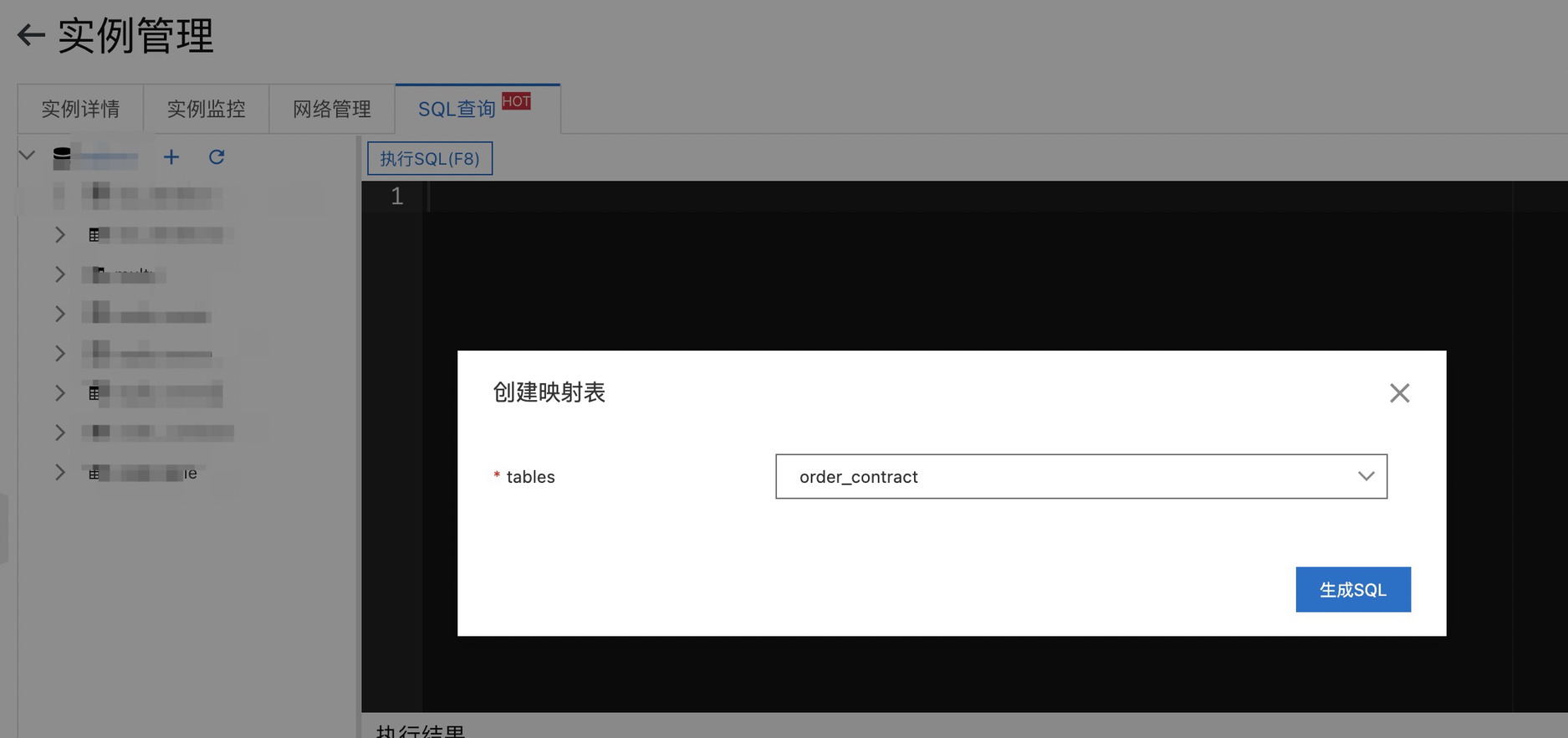
使用EMR SQL 批处理Tablestore
通过在E-MapReduce集群中使用Spark SQL访问表格存储。对于批计算,Tablestore on Spark提供索引选择、分区裁剪、Projection列和Filter下推、动态指定分区大小等功能,利用表格存储的全局二级索引或者多元索引可以加速查询。 前提条件 已创建E-MapReduc...
使用EMR SQL 流处理 Tablestore
通过在E-MapReduce集群中使用Spark SQL访问表格存储。对于流计算,基于通道服务,利用CDC(数据变更捕获)技术完成Spark的mini batch流式消费和计算,同时提供了at-least-once一致性语义。 前提条件 已创建E-MapReduce Hadoop集群。具体操作,请参...
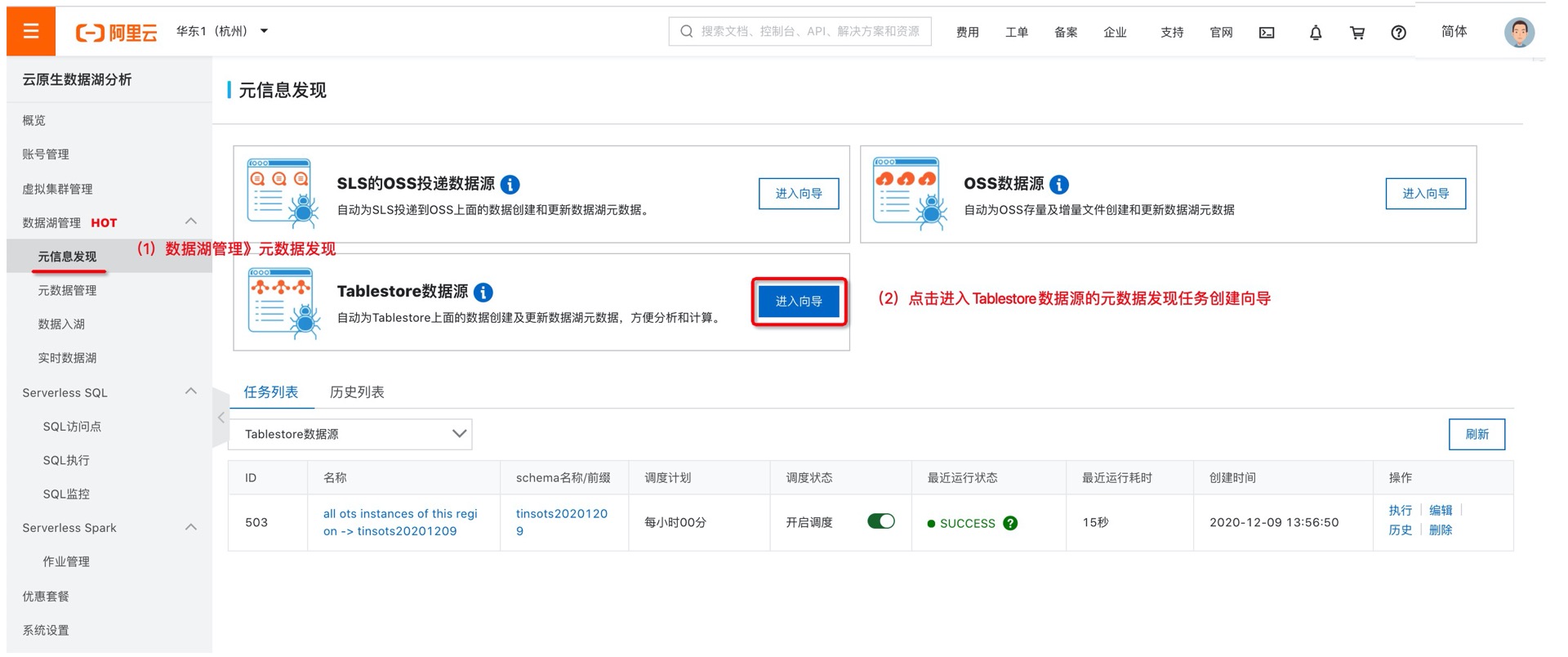
DLA一键发现Tablestore元数据,轻松开启数据湖SQL分析之旅
背景 为了使用DLA标准SQL分析Tablestore数据,往往需要很多步骤才能在DLA中创建相应元数据映射,进而使用SQL去分析Tablestore数据。繁琐复杂的SQL DDL编写,数据类型映射关系的一一对应,都需要较高的成本和门槛去编写维护,还容易出错。 现在,数据湖分析DLA发布了一个免费的...

Tablestore结合Spark的流批一体SQL实战
作者:王卓然 花名琸然 阿里云存储服务技术专家 背景介绍 电子商务模式是指在网络环境和大数据环境下基于一定技术基础的商务运作方式和盈利模式,对于数据的分析和可视化是电商运营中最重要的部分之一,而电商大屏提供了数据分析和可视化的完美结合。电商大屏包含有全量订单和实时订单的聚合,全量订单的聚合提供的是全...
Tablestore结合Spark的流批一体SQL实战
背景介绍 电子商务模式是指在网络环境和大数据环境下基于一定技术基础的商务运作方式和盈利模式,对于数据的分析和可视化是电商运营中最重要的部分之一,而电商大屏提供了数据分析和可视化的完美结合。电商大屏包含有全量订单和实时订单的聚合,全量订单的聚合提供的是全景的综合数据视图,而实时订单的聚合展示的是实时的...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子




最佳实践




