[帮助文档] PySpark任务开发入门
您可以自行编写并构建包含业务逻辑的Python脚本,上传该脚本后,即可便捷地创建和执行PySpark任务。本文通过一个示例,为您演示如何进行PySpark任务的开发与部署。

数据分享|Python、Spark SQL、MapReduce决策树、回归对车祸发生率影响因素可视化分析
相关视频 项目挑战 ...

[帮助文档] 创建工作空间
工作空间是Serverless Spark的基本单元,用于管理任务、成员、角色和权限。所有的任务开发都需要在具体的工作空间内进行。因此,在开始任务开发之前,您需要先创建工作空间。本文将为您介绍如何在EMR Serverless Spark页面快速创建工作空间。
[帮助文档] Spark SQL任务快速入门
EMR Serverless Spark支持通过SQL代码编辑和运行任务。本文带您快速体验Spark SQL任务的创建、启动和运维等操作。
[帮助文档] RAM用户授权
当RAM用户(子账号)进行EMR Serverless Spark操作,例如创建、查看或删除工作空间等操作时,必须具有相应的权限。本文为您介绍如何进行RAM授权。
[帮助文档] 阿里云账号角色授权
使用EMR Serverless Spark前,需要授予您的阿里云账号AliyunServiceRoleForEMRServerlessSpark和AliyunEMRSparkJobRunDefaultRole系统默认角色。本文为您介绍角色授权的基本操作。
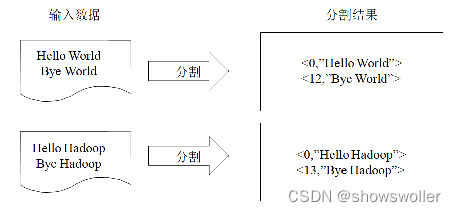
【大数据技术Hadoop+Spark】MapReduce之单词计数和倒排索引实战(附源码和数据集 超详细)
源码和数据集请点赞关注收藏后评论区留言私信~~~一、统计单词出现次数单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版“Hello World。其主要功能是统计一系列文本文件中每个单词出现的次数程序解析首先MapReduce将文件拆分成splits,由于测试用...
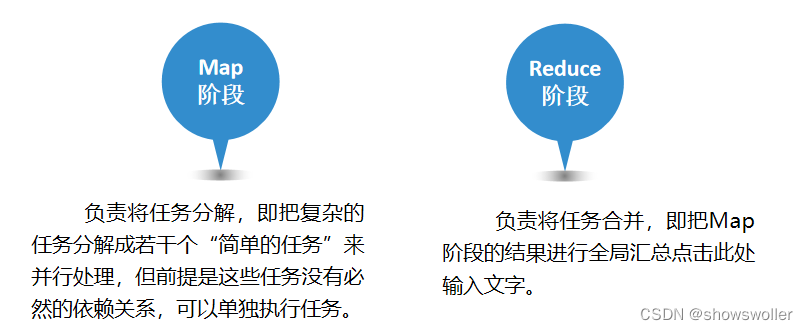
【大数据技术Hadoop+Spark】MapReduce概要、思想、编程模型组件、工作原理详解(超详细)
MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。一、MapReduce核心思想MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方...
Storm&Spark中MapReduce框架包括什么呢?
Storm&Spark中MapReduce框架包括什么呢?
Spark将Hadoop(主要是指MapReduce)的性能提升了一个量级,主要的得益于那两个方面?
Spark将Hadoop(主要是指MapReduce)的性能提升了一个量级,主要的得益于那两个方面?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
mapreduce您可能感兴趣
- mapreduce计算
- mapreduce框架
- mapreduce hadoop
- mapreduce实战
- mapreduce实践
- mapreduce案例
- mapreduce编程
- mapreduce大数据
- mapreduce分布式计算
- mapreduce starrocks
- mapreduce集群
- mapreduce数据
- mapreduce作业
- mapreduce hdfs
- mapreduce运行
- mapreduce maxcompute
- mapreduce任务
- mapreduce程序
- mapreduce配置
- mapreduce yarn
- mapreduce oss
- mapreduce优化
- mapreduce wordcount
- mapreduce map