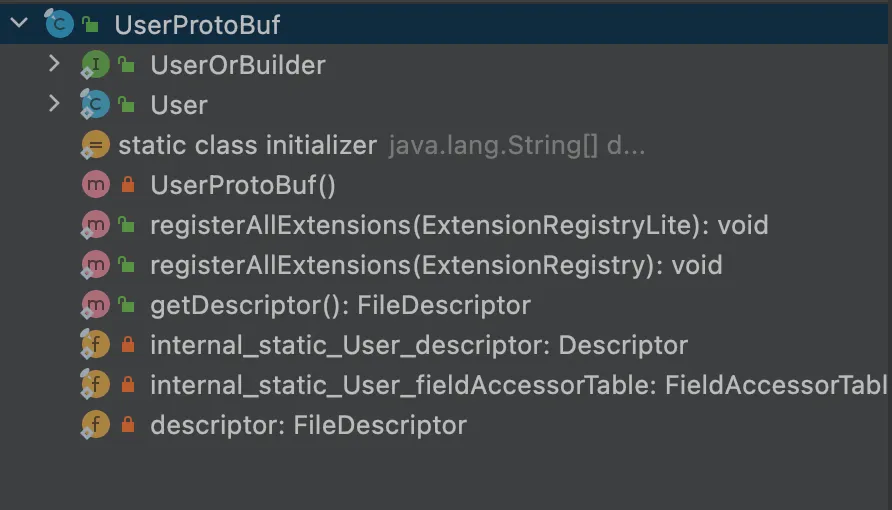
阿里云Flink-自定义kafka format实践及踩坑记录(以protobuf为例)
1. protobuf简介 Protocol Buffers(简称:ProtoBuf)是一种开源跨平台的序列化数据结构的协议。其对于存储资料或在网络上进行通信的程序是很有用的。这个方法包含一个接口描述语言,描述一些数据结构,并提供程序工具根据这些描述产生代码,这些代码将用来生成或解析代表这些数据结构...
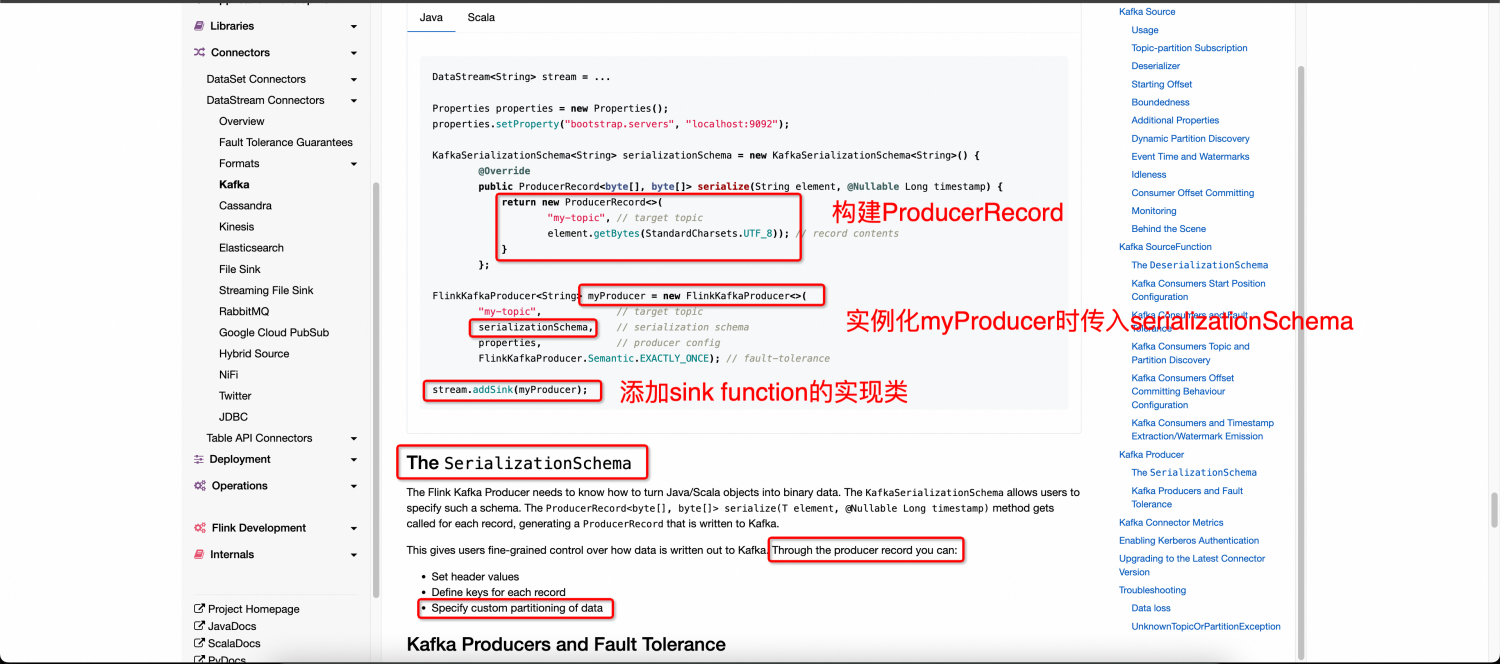
阿里云Flink-自定义kafka sink partitioner实践及相关踩坑记录
1. 背景及需求链路:Flink -> sink kafka需求:客户需求根据数据的特征,以自定义的逻辑,将不同的数据写到kafka不同的分区中阿里云官方文档链接:https://help.aliyun.com/zh/flink/developer-reference/kafka-connec...

全托管flink-vvp 自定义mongodb-cdc-connector实践
全托管flink-vvp 自定义mongodb-cdc-connector实践
[帮助文档] 如何实现Flink+DLF数据入湖与分析
数据湖构建(DLF)可以结合阿里云实时计算Flink版(Flink VVP),以及Flink CDC相关技术,实现灵活定制化的数据入湖。并利用DLF统一元数据管理、权限管理等能力,实现数据湖多引擎分析、数据湖管理等功能。本文为您介绍Flink+DLF数据湖方案具体步骤。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子



最佳实践
更多




实时计算 Flink版实践相关内容
- 实时计算 Flink版优化实践
- 实时计算 Flink版数据集成实践
- 实时计算 Flink版集成实践
- 实时计算 Flink版环境实践
- 实时计算 Flink版产品实践
- 实时计算 Flink版hudi实践
- 实时计算 Flink版hologres实践
- 实时计算 Flink版数据湖实践
- 实时计算 Flink版实时数据湖实践
- 小米实时计算 Flink版实践
- 实时计算 Flink版字节跳动实践
- 实时计算 Flink版数仓实践
- smartnews实时计算 Flink版实践
- 实时计算 Flink版k8s实践
- 全托管实时计算 Flink版实践
- 实时计算 Flink版平台实践
- 实时计算 Flink版大规模实践
- 迁移实时计算 Flink版实践
- apacheflink案例集(2022版)数据集成实时计算 Flink版实践
- 实时计算 Flink版湖仓一体实践
- 实时计算 Flink版数据分析实践
- 实时计算 Flink版快手扩展实践
- apacheflink案例集(2022版)实时计算 Flink版实践
- 实时计算 Flink版实时风控实践
- 实时计算 Flink版机器学习实践
- apacheflink案例集(2022版)机器学习实时计算 Flink版实践
- 实时计算 Flink版native实践
- 云原生实时计算 Flink版实践
- apacheflink案例集(2022版)数字化转型实时计算 Flink版实践
- 实时计算 Flink版移动云实践
- 实时计算 Flink版catalog实践
- 实时计算 Flink版平台应用实践
- 引擎实时计算 Flink版实践
- 实时计算 Flink版原理实践
- 实时计算 Flink版k8s原理实践
- 网易实时计算flink版支付环境实践
- 实时计算flink版流批一体实践
- 实时计算flink版小米实践
- bigo实时计算 Flink版平台实践
- 实时计算 Flink版美团实践
- 实时计算 Flink版meetup实践
- 实时计算 Flink版技术实践
- 实时计算 Flink版探索实践
实时计算 Flink版您可能感兴趣
- 实时计算 Flink版cp
- 实时计算 Flink版设置
- 实时计算 Flink版HDFS
- 实时计算 Flink版SQL
- 实时计算 Flink版版本
- 实时计算 Flink版任务
- 实时计算 Flink版sp
- 实时计算 Flink版oracle
- 实时计算 Flink版消耗
- 实时计算 Flink版迁移
- 实时计算 Flink版CDC
- 实时计算 Flink版数据
- 实时计算 Flink版mysql
- 实时计算 Flink版同步
- 实时计算 Flink版报错
- 实时计算 Flink版kafka
- 实时计算 Flink版表
- 实时计算 Flink版Apache
- 实时计算 Flink版配置
- 实时计算 Flink版实时计算
- 实时计算 Flink版flink
- 实时计算 Flink版 CDC
- 实时计算 Flink版模式
- 实时计算 Flink版运行
- 实时计算 Flink版数据库