【大数据技术Spark】Spark SQL操作Dataframe、读写MySQL、Hive数据库实战(附源码)
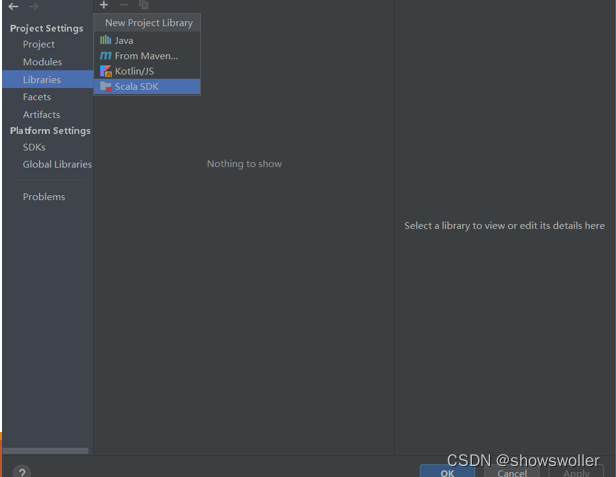
需要源码和依赖请点赞关注收藏后评论区留言私信~~~一、Dataframe操作步骤如下1)利用IntelliJ IDEA新建一个maven工程,界面如下2)修改pom.XML添加相关依赖包3)在工程名处点右键,选择Open Module Settings4)配置Scala Sdk,界面如下5)新建文件...
【大数据技术Hadoop+Spark】Hive基础SQL语法DDL、DML、DQL讲解及演示(附SQL语句)
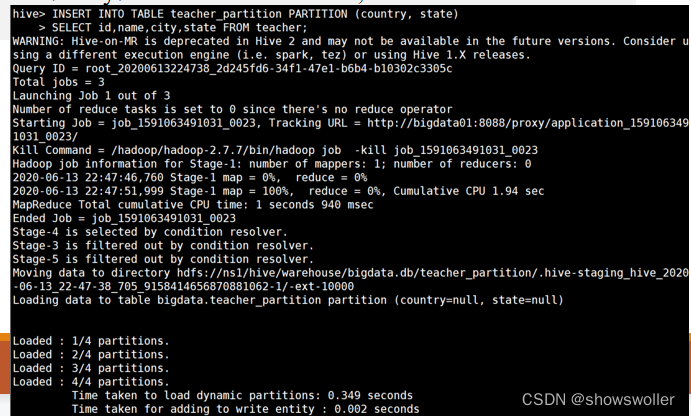
Hive基础SQL语法1:DDL操作DDL是数据定义语言,与关系数据库操作相似,创建数据库CREATE DATABASE|SCHEMA [IF NOT EXISTS] database_name显示数据库SHOW databases;查看数据库详情DESC DATABASE|SCHEMA datab...

【大数据技术Hadoop+Spark】Hive数据仓库架构、优缺点、数据模型介绍(图文解释 超详细)
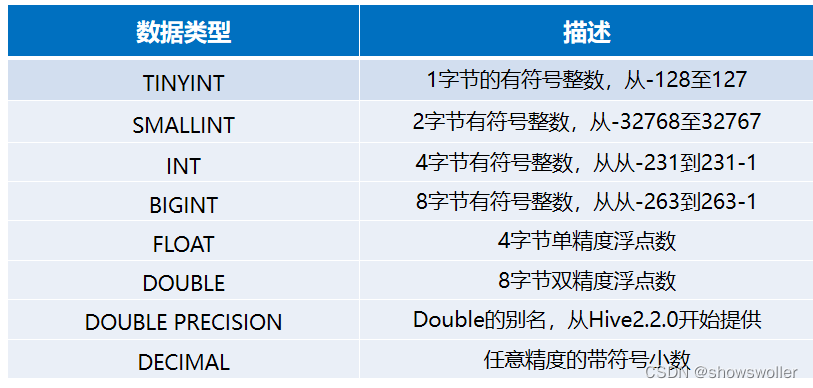
一、Hive简介Hive起源于Facebook,Facebook公司有着大量的日志数据,而Hadoop是实现了MapReduce模式开源的分布式并行计算的框架,可轻松处理大规模数据。然而MapReduce程序对熟悉Java语言的工程师来说容易开发,但对于其他语言使用者则难度较大。因此Facebook...
大数据技术的对决——Spark对Impala对Hive对Presto
在大数据浪潮全面来袭的历史背景下,我们一直面临着同一类难题的困扰——该选择哪款工具解决相关问题?这项挑战在大数据SQL引擎领域同样存在。作为大数据报告工具开发商,AtScale公司通过基准测试为我们带来了如下答案: 1. Spark 2.0在大规模查询性能方面可达1.6版本的2.4倍。二者的小规模查...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








云原生大数据计算服务 MaxCompute技术相关内容
- 云原生大数据计算服务 MaxCompute工程技术入选
- 云原生大数据计算服务 MaxCompute技术团队
- 云原生大数据计算服务 MaxCompute实战技术
- 云原生大数据计算服务 MaxCompute技术spark
- 技术云原生大数据计算服务 MaxCompute
- 数据库技术云原生大数据计算服务 MaxCompute应用
- 云原生技术云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute技术工具
- 云原生大数据计算服务 MaxCompute技术apache
- 数仓云原生大数据计算服务 MaxCompute技术dolphinscheduler
- 云原生大数据计算服务 MaxCompute技术概述
- 云原生大数据计算服务 MaxCompute技术引擎
- 云原生大数据计算服务 MaxCompute技术运行原理
- 云原生大数据计算服务 MaxCompute技术原理
- 云原生大数据计算服务 MaxCompute技术数据采集
- 云原生大数据计算服务 MaxCompute技术基石
- 云原生大数据计算服务 MaxCompute技术机器学习
- 云原生大数据计算服务 MaxCompute技术方法
- 云原生大数据计算服务 MaxCompute技术spark hbase
- 云原生大数据计算服务 MaxCompute技术spark原理
- 云原生大数据计算服务 MaxCompute技术组件
- 云原生大数据计算服务 MaxCompute技术命令
- 云原生大数据计算服务 MaxCompute技术实战源码
- 云原生大数据计算服务 MaxCompute技术数据类型
- 云原生大数据计算服务 MaxCompute技术安装
- 云原生大数据计算服务 MaxCompute技术dstream
- 云原生大数据计算服务 MaxCompute技术读写
- 云原生大数据计算服务 MaxCompute技术优缺点
- 云原生大数据计算服务 MaxCompute技术mapreduce
- 云原生大数据计算服务 MaxCompute技术调度模型
- 云计算云原生大数据计算服务 MaxCompute技术模型
- 云计算云原生大数据计算服务 MaxCompute技术spark
- 云原生大数据计算服务 MaxCompute技术zookeeper
- 云计算云原生大数据计算服务 MaxCompute技术集群
- 云原生大数据计算服务 MaxCompute技术文件
- 云原生大数据计算服务 MaxCompute技术虚拟化
- 云原生大数据计算服务 MaxCompute云计算技术
- 云原生大数据计算服务 MaxCompute技术实验
- 云原生大数据计算服务 MaxCompute技术实验命令
- 开源云原生大数据计算服务 MaxCompute技术实践
- 云原生大数据计算服务 MaxCompute技术在线教育
- 云原生大数据计算服务 MaxCompute技术项目
- 云原生大数据计算服务 MaxCompute技术sqoop
- 产品云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute技术学习
- 云原生大数据计算服务 MaxCompute技术公开课
- 技术公开课云原生大数据计算服务 MaxCompute
- kubernetes云原生大数据计算服务 MaxCompute技术
云原生大数据计算服务 MaxCompute更多技术相关
- 阿里云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute技术工程
- 云原生大数据计算服务 MaxCompute产品技术特性
- 技术云原生大数据计算服务 MaxCompute公开课
- 技术云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute框架技术项目
- 云原生大数据计算服务 MaxCompute技术学习笔记
- 云原生大数据计算服务 MaxCompute大数据处理编程实践技术简介
- 云原生大数据计算服务 MaxCompute技术专业
- 阿里技术云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute技术融合
- 视频云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute技术共享
- 人工智能云原生大数据计算服务 MaxCompute技术
- it技术云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute系统技术
- 云原生大数据计算服务 MaxCompute入门技术
- 云原生大数据计算服务 MaxCompute存储技术
- spark云原生大数据计算服务 MaxCompute技术
- 问答云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute技术运营
- kafka云原生大数据计算服务 MaxCompute系统技术重构
- 云原生大数据计算服务 MaxCompute技术研究院
- nlpir云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute技术pdf
- 云原生大数据计算服务 MaxCompute技术技术公开课
- 云原生大数据计算服务 MaxCompute智能技术
- 云原生大数据计算服务 MaxCompute技术阿里
- 云原生大数据计算服务 MaxCompute方法技术
- 智能技术云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute技术框架
- 云原生大数据计算服务 MaxCompute技术接轨商业
- 云原生大数据计算服务 MaxCompute技术平台
- 云原生大数据计算服务 MaxCompute nosql技术
- 云原生大数据计算服务 MaxCompute入门实战技术
- 后端技术云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute技术信息
- 聚星运营云原生大数据计算服务 MaxCompute技术
- teradata革新云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute技术魅力
- 大数据管理概论云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute计算技术
- 云原生大数据计算服务 MaxCompute技术背后
- 技术阻碍云原生大数据计算服务 MaxCompute步伐
- 聚星客户运营云原生大数据计算服务 MaxCompute算法技术
- 云原生大数据计算服务 MaxCompute数据计算技术
- 技术公开课云原生大数据计算服务 MaxCompute实战
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute期末
- 云原生大数据计算服务 MaxCompute编程
- 云原生大数据计算服务 MaxCompute作业
- 云原生大数据计算服务 MaxCompute nosql
- 云原生大数据计算服务 MaxCompute数据库
- 云原生大数据计算服务 MaxCompute分布式
- 云原生大数据计算服务 MaxCompute hbase
- 云原生大数据计算服务 MaxCompute hdfs
- 云原生大数据计算服务 MaxCompute分布式文件系统
- 云原生大数据计算服务 MaxCompute adbmysql
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute项目