R语言K-Means(K均值聚类)和层次聚类算法对微博用户特征数据研究
全文链接:https://tecdat.cn/?p=32955 本文就将采用K-means算法和层次聚类对基于用户特征的微博数据帮助客户进行聚类分析(点击文末“阅读原文”获取完整代码数据)。 首先对聚类分析作系统介绍。其次对聚类算法进行文献回顾,对其概况、基本思想、算法进行详细介绍,再是通过对微博数...

数据分享|R语言改进的K-MEANS(K-均值)聚类算法分析股票盈利能力和可视化
全文链接:http://tecdat.cn/?p=32418 大量数据中具有"相似"特征的数据点或样本划分为一个类别。聚类分析提供了样本集在非监督模式下的类别划分(点击文末“阅读原文”获取完整代码数据)。 人们在投资时总期望以最小的风险获取最大的利益,面对庞大的股票市场和繁杂的股票数据,要想对股票进...

R语言聚类算法的应用实例
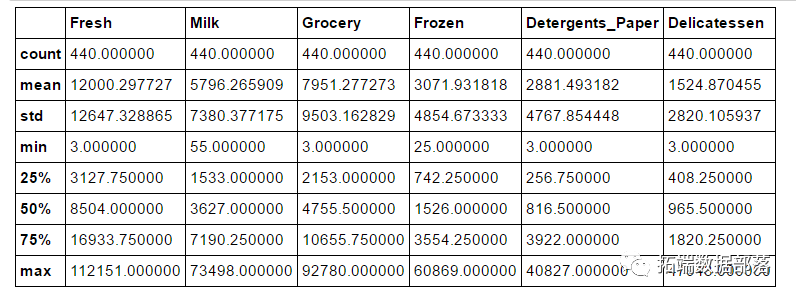
一家批发经销商想将发货方式从每周五次减少到每周三次,简称成本,但是造成一些客户的不满意,取消了提货,带来更大亏损,项目要求是通过分析客户类别,选择合适的发货方式,达到技能降低成本又能降低客户不满意度的目的。 什么是聚类 聚类将相似的对象归到同一个簇中,几乎可以应用于所有对象,聚类的对象越相似,聚类效...
R语言最优聚类数目k改进kmean聚类算法
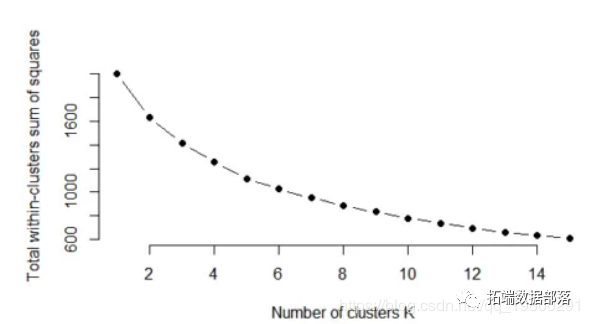
在本文中,我们将探讨应用聚类算法(例如k均值和期望最大化)来确定集群的最佳数量时所遇到的问题之一。从数据集本身来看,确定集群数量的最佳值的问题通常不是很清楚。在本文中,我们将介绍几种技术,可用于帮助确定给定数据集的最佳k值。 我们将在当前的R Studio环境中下载数据集: ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









