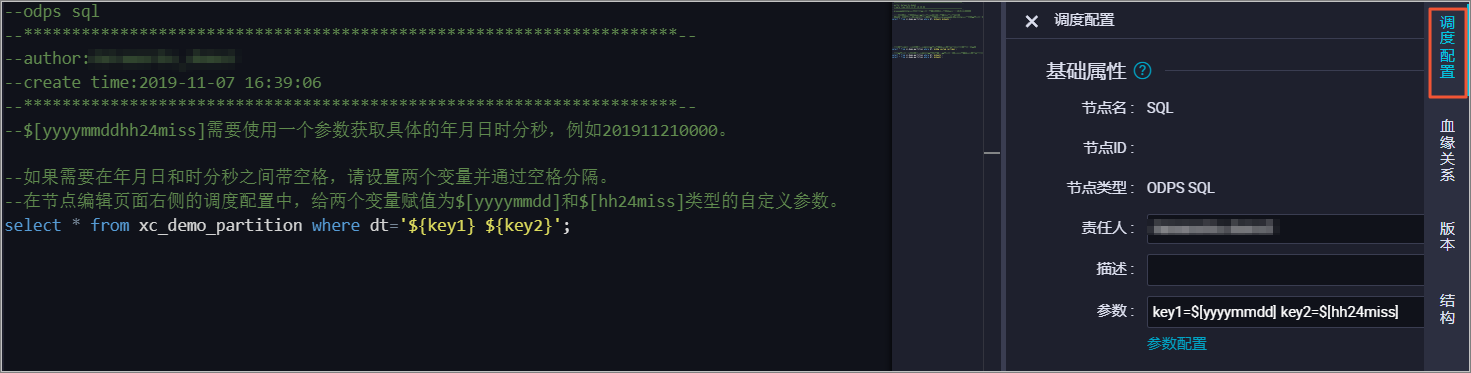
DataWorks产品使用合集之DataWorks maxcompute的自定义资源增加如何解决
问题一:DataWorks中maxcompute自定义函数jar包创建? DataWorks中maxcompute自定义函数jar包创建? 参考回答: 点击以下链接下载依赖JAR包:alisa-wrapper-face-1.0.0.jar。 https://help.aliyun.com/docum...

DataWorks产品使用合集之DataWorks maxcompute的自定义资源增加如何解决
问题一:DataWorks如果数据量太大,id又比较分散,我觉得这个按照时间切分功能是可以做的? DataWorks如果数据量太大,id又比较分散,我同步昨天一天的数据不能按照修改时间自动切分,我还得根据修改时间手动建24个任务? 我觉得这个按照时间切分功能是可以做的? 参考回答: 或者可以配置成小...

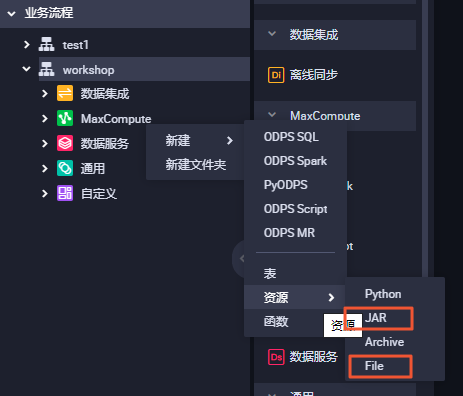
MaxCompute产品使用合集之要增加MaxCompute的自定义资源,该怎么操作
问题一:大数据计算MaxCompu使用pyodps 和 odpssql对mc表数据进行清洗处理 哪个效率高? "1大数据计算MaxCompute使用pyodps 和 odpssql对mc表数据进行清洗处理 哪个效率会高一些呢? 大数据计算MaxCompute的cte 产生的临时结果集 的生命周期有多...
[帮助文档] 资源观测
资源观测功能提供了对工作空间及队列的计算单元(CU)消耗的直观监控,并支持按照时间维度进行筛选与分析。
[帮助文档] 管理资源队列
每个工作空间都会默认包含dev_queue和root_queue两个队列,用于承载作业的运行。如果您有资源隔离和管理的需求,可以通过添加队列的方式实现。本文为您介绍队列的基本操作。
[帮助文档] 上传资源文件
在执行任务前,必须先将所需的文件或JAR包等资源上传至EMR Serverless Spark,以确保任务运行时可以无缝地访问和使用所有必要资源。
[帮助文档] ECS资源复用版
ECS资源复用版是MaxCompute按量付费类型中的一种实例规格,旨在将ECS闲置实例转换为可用的MaxCompute计算资源,该方式可以充分利用已有的计算资源,而不需要额外购买新的MaxCompute计算资源,从而在满足大数据处理需求的同时,提高资源利用率并降低总体资源成本。本文为您介绍MaxC...
[帮助文档] 在EMR控制台配置资源队列
资源队列用于管理和调度集群资源,旨在实现资源的灵活分配和优化。通过阿里云EMR控制台,您可以方便地管理资源队列,并关联不同的分区。
DataWorks如何增加maxcompute的自定义资源?
DataWorks如何增加maxcompute的自定义资源?
MaxCompute自定义UDF中使用了fastjson的代码,但是MaxCompute中没有该库,如何自己加入fastjson的jar到odps资源中并且可以在自定义udf中使用?
MaxCompute自定义UDF中使用了fastjson的代码,但是MaxCompute中没有该库,如何自己加入fastjson的jar到odps资源中并且可以在自定义udf中使用?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









云原生大数据计算服务 MaxCompute资源相关内容
- 云原生大数据计算服务 MaxCompute包年包月资源
- 云原生大数据计算服务 MaxCompute资源组资源
- 云原生大数据计算服务 MaxCompute独享资源
- 云原生大数据计算服务 MaxCompute资源资源组
- 数据计算云原生大数据计算服务 MaxCompute udf资源
- 云原生大数据计算服务 MaxCompute文件资源
- 云原生大数据计算服务 MaxCompute资源信息
- 云原生大数据计算服务 MaxCompute jar资源
- 云原生大数据计算服务 MaxCompute mc资源
- 云原生大数据计算服务 MaxCompute运行资源
- 云原生大数据计算服务 MaxCompute实例资源
- 数据计算云原生大数据计算服务 MaxCompute运行资源
- 云原生大数据计算服务 MaxCompute包资源
- 云原生大数据计算服务 MaxCompute资源按量付费
- 云原生大数据计算服务 MaxCompute logview资源
- 云原生大数据计算服务 MaxCompute调度资源组资源
- 数据计算云原生大数据计算服务 MaxCompute调度资源
- 云原生大数据计算服务 MaxCompute环境资源
- 云原生大数据计算服务 MaxCompute资源配置
- 云原生大数据计算服务 MaxCompute机器学习资源
- 数据计算云原生大数据计算服务 MaxCompute datawork资源
- 大数据云原生大数据计算服务 MaxCompute任务资源
- 云原生大数据计算服务 MaxCompute工具资源
- 云原生大数据计算服务 MaxCompute作业资源
- 云原生大数据计算服务 MaxCompute资源数据源如何解决
- 云原生大数据计算服务 MaxCompute资源如何解决
- 云原生大数据计算服务 MaxCompute资源调度
- 云原生大数据计算服务 MaxCompute资源计算资源
- 云原生大数据计算服务 MaxCompute dw资源
- 云原生大数据计算服务 MaxCompute table资源
- 云原生大数据计算服务 MaxCompute资源模式
- 资源云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute资源库
- 数据计算云原生大数据计算服务 MaxCompute资源库
- 云原生大数据计算服务 MaxCompute quota资源
- 云原生大数据计算服务 MaxCompute资源概念
- 云原生大数据计算服务 MaxCompute分配资源
- 云原生大数据计算服务 MaxCompute cu资源
- 云原生大数据计算服务 MaxCompute服务资源
- 云原生大数据计算服务 MaxCompute资源消耗
- 云原生大数据计算服务 MaxCompute资源脚本
- 云原生大数据计算服务 MaxCompute资源列表
- 云原生大数据计算服务 MaxCompute开发资源
- 云原生大数据计算服务 MaxCompute申请资源
- 云原生大数据计算服务 MaxCompute图片所说资源怎么配置
- 云原生大数据计算服务 MaxCompute访问资源
- 云原生大数据计算服务 MaxCompute资源jar
- 云原生大数据计算服务 MaxCompute项目资源
云原生大数据计算服务 MaxCompute更多资源相关
- 云原生大数据计算服务 MaxCompute资源管理资源
- 云原生大数据计算服务 MaxCompute用户指南资源
- 云原生大数据计算服务 MaxCompute预付费资源
- 一站式云原生大数据计算服务 MaxCompute开发者资源
- 云原生大数据计算服务 MaxCompute spark executor资源参数调优
- 云原生大数据计算服务 MaxCompute用户指南mapreduce资源
- 云原生大数据计算服务 MaxCompute资源文档
- 云原生大数据计算服务 MaxCompute消耗资源
- 云原生大数据计算服务 MaxCompute资源争夺战此起彼伏
- 云原生大数据计算服务 MaxCompute自定义函数mapreduce资源
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute实例id
- 云原生大数据计算服务 MaxCompute日期格式
- 云原生大数据计算服务 MaxCompute在建
- 云原生大数据计算服务 MaxCompute client
- 云原生大数据计算服务 MaxCompute openapi
- 云原生大数据计算服务 MaxCompute quickbi
- 云原生大数据计算服务 MaxCompute区分
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute字符
- 云原生大数据计算服务 MaxCompute工单
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute产品