【spark系列4】spark 3.0.1集成delta 0.7.0原理解析--delta自定义sql
前提本文基于 spark 3.0.1delta 0.7.0我们都知道delta.io是一个给数据湖提供可靠性的开源存储层的软件,关于他的用处,可以参考Delta Lake,让你从复杂的Lambda架构中解放出来,于此类似的产品有hudi,Iceberg,因为delta无缝集成spark,所以我们来分...
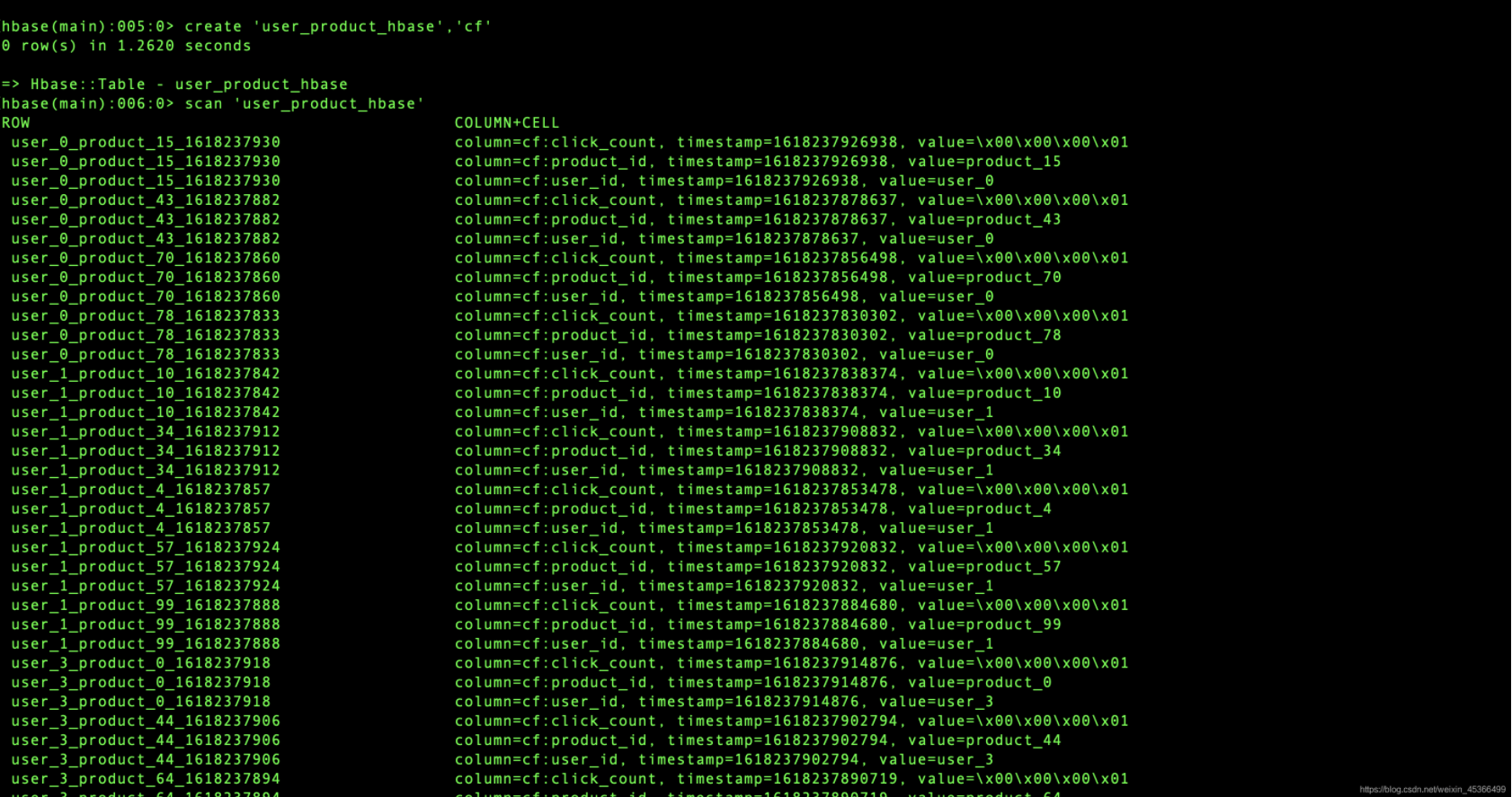
Flink SQL与HBase的集成
版本说明:flink-1.12.1hbase-1.4.13目录(1)Flink SQL与HBase的集成配置(2)测试Flink SQL与HBase集成代码(3)测试kafka数据源与HBase写入数据(1)Flink SQL与HBase的集成配置第一步:M...

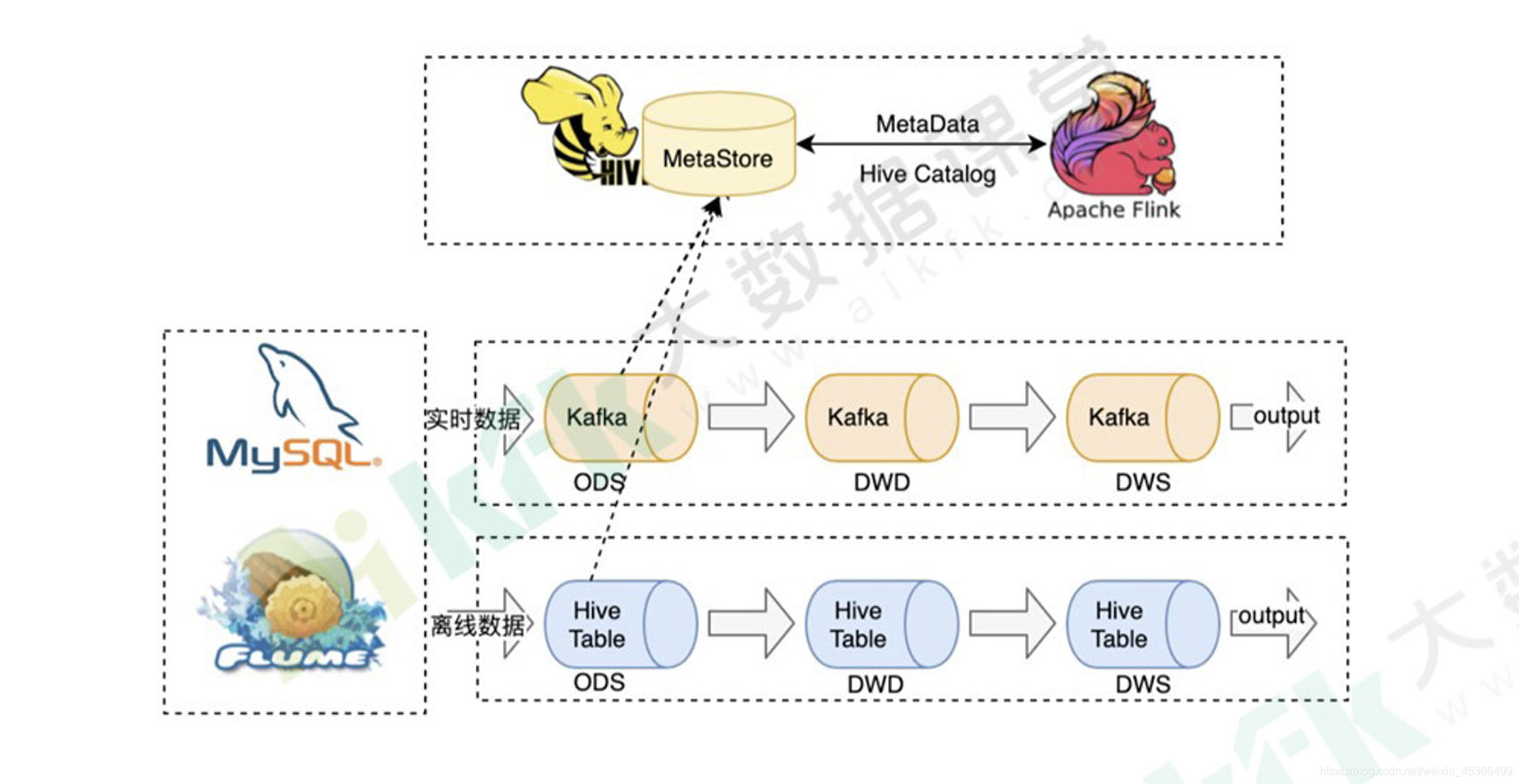
Flink SQL与Hive的集成
(1)Flink SQL与Hive集成的架构图(2)Flink 与 Hive 的集成包含两个层面一是利用了 Hive 的 MetaStore 作为持久化的 Catalog用户可通过HiveCatalog将不同会话中的 Flink 元数据存储到 Hive Metastore 中。 例如,用户可以使用H...
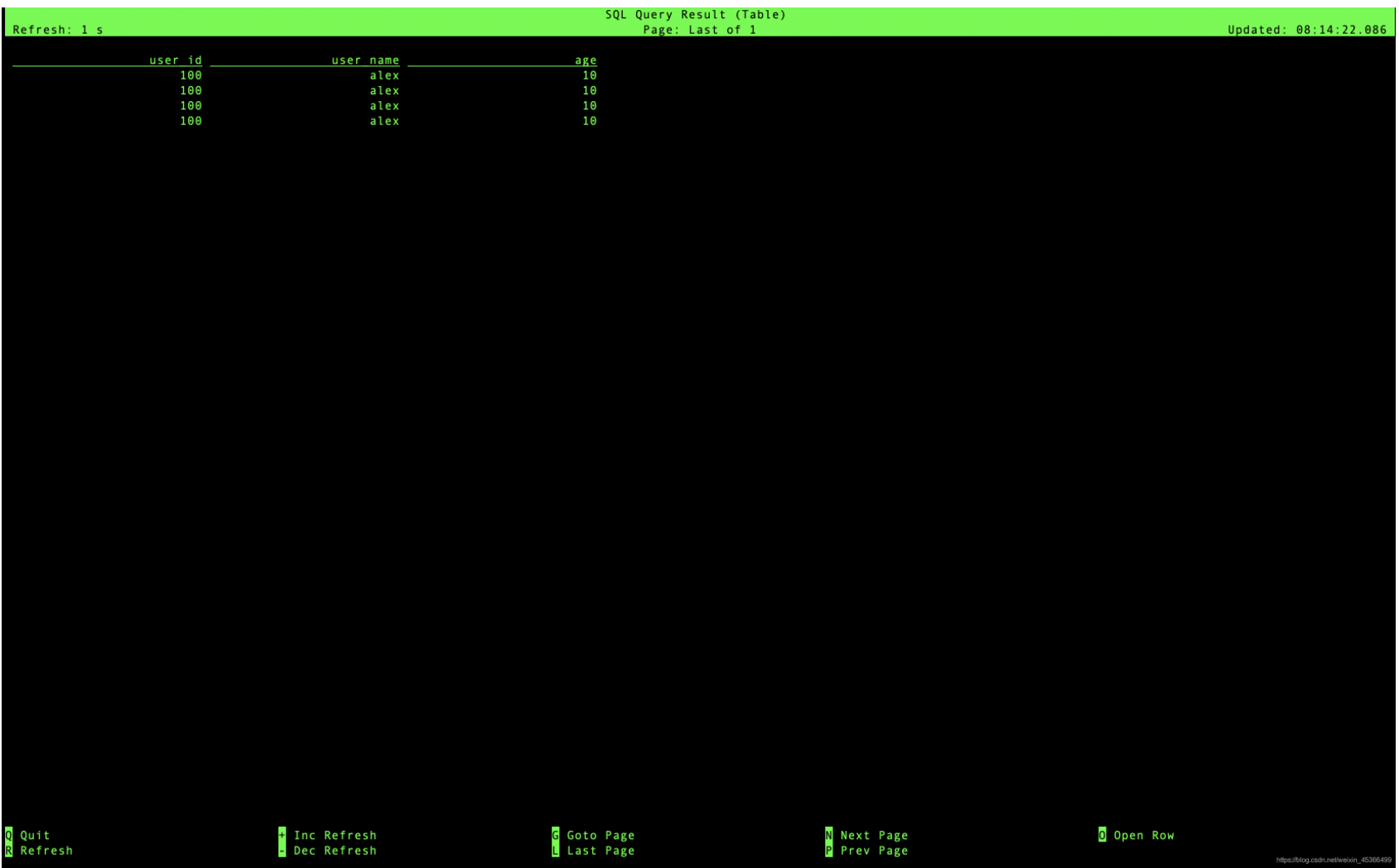
Flink SQL与JDBC的集成
版本说明:flink-1.12.1第一步:加载依赖与添加jar包Maven dependency<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-j...
Flink SQL与Kafka的集成
版本说明:flink-1.12.1kafka_2.12-2.4.1(1)Flink Stream与Kafka的集成添加maven依赖:<dependency> <groupId>org.apache.flink</groupId> <artifactId&g...
Spark SQL与JDBC的集成
数据源:userid,addres,age,username 001,guangzhou,20,alex 002,shenzhen,34,jack 003,beijing,23,lili 创建mysql数据表create table person( userid varchar(20), addre...

spring boot集成mybatis只剩两个sql 并提示 Cannot obtain primary key information from the database, generated objects may be incomplete
前言spring boot集成mybatis时只生成两个sql, 搞了一个早上,终于找到原因了找了很多办法都没有解决, 最后注意到生成sql的时候打印了一句话: Cannot obtain primary key information from the database, g...
Spark SQL 与Hive集成
一、Spark SQL 与Hive集成(spark-shell)(1)添加配置项目第一步:把Hadoop集群的core-site.xml,hdfs-site.xml和hive的配置文件hive-site.xml拷贝到spark的conf的目录下cp hive-site.xml /opt/Hadoop...
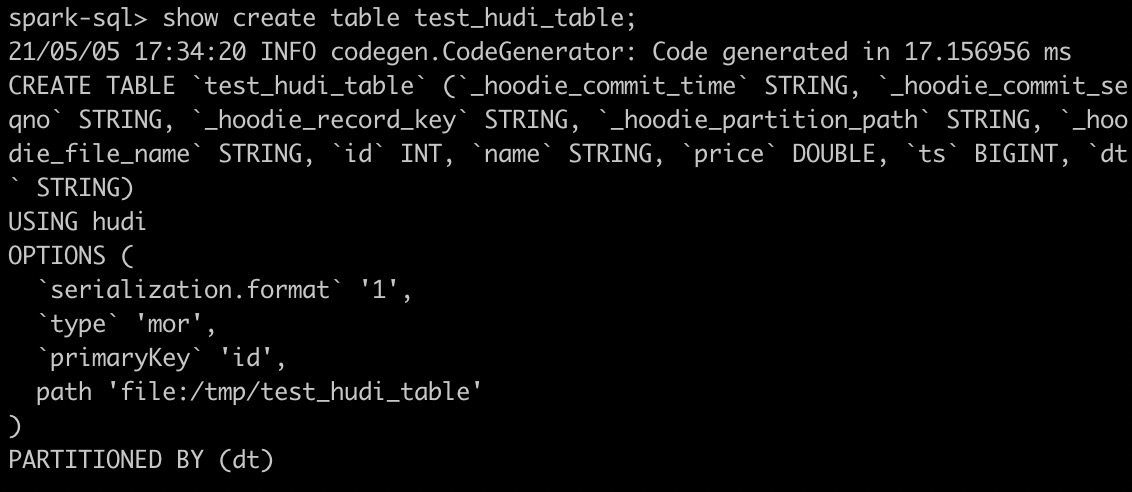
Apache Hudi集成Spark SQL抢先体验
Apache Hudi集成Spark SQL抢先体验1. 摘要社区小伙伴一直期待的Hudi整合Spark SQL的PR正在积极Review中并已经快接近尾声,Hudi集成Spark SQL预计会在下个版本正式发布,在集成Spark SQL后,会极大方便用户对Hudi表的DDL/DML操作,下面就来看...
MaxCompute studio SQL中console无缝集成是咋样的流程呢?
MaxCompute studio SQL中console无缝集成是咋样的流程呢?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子




最佳实践




