Scrapy网络爬虫框架——从入门到实践
一、Scrapy框架的概念Scrapy框架是一种基于Python的开源网络爬虫框架,它可以帮助用户快速方便地抓取互联网上的数据,并且支持多线程/协程并发处理,具有很高的效率。在Scrapy中,用户可以定义自己的Spider(爬虫),通过配置Pipeline(管道)来处理数...
Scrapy:从入门到实践的网络爬虫框架
一、Scrapy框架概述Scrapy是一款基于Python的开源网络爬虫框架,最初由Pablo Hoffman开发。它采用了Twisted异步网络框架和pyOpenSSL进行加密处理,具有高效、可扩展、灵活等特点。Scrapy支持多种数据格式的抓取和保存,包括HTML、XML、JSON等,同时还支持...
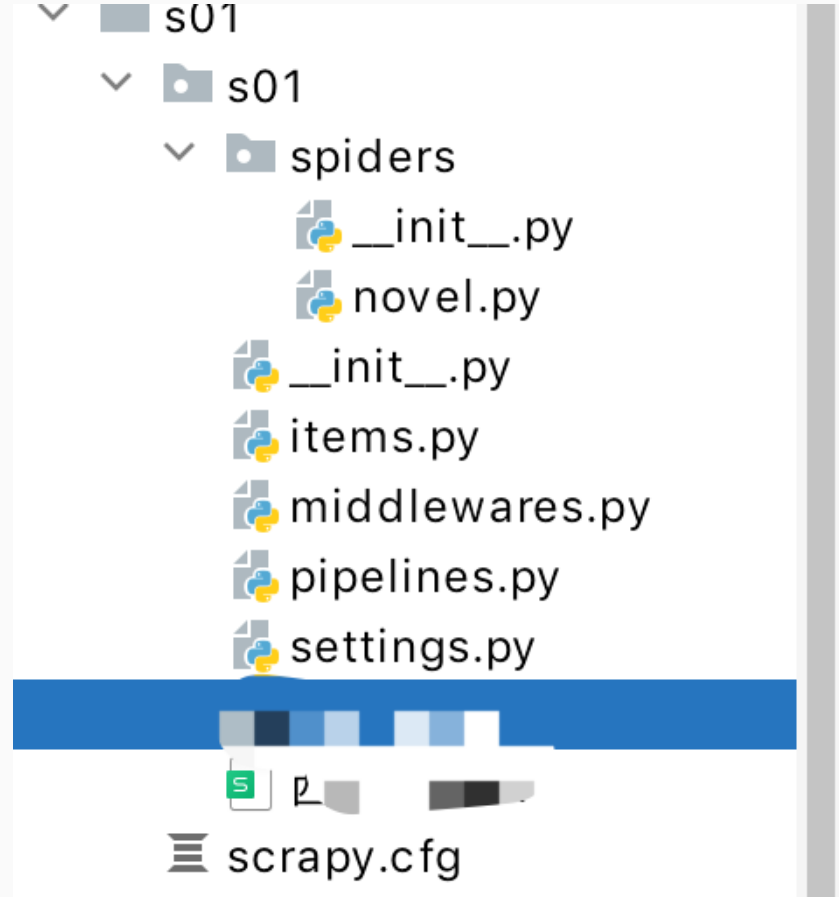
scrapy简单入门
1. 前言爬取数据用的 比 request功能强大多了2. 安装根据自己的环境选择安装哪个pip install scrapypip list 查看依赖列表权限问题可以install 后面加上 --userconda install scrapyconda list 查看依赖列表指令scrapy -...
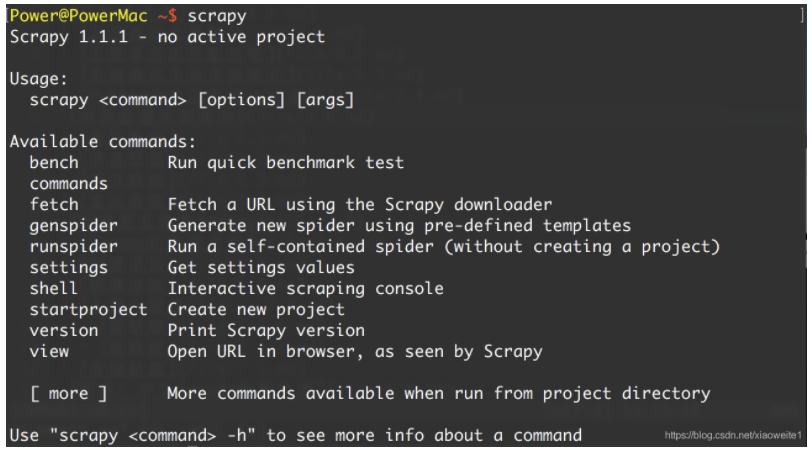
Python:Scrapy的安装和入门案例
Scrapy的安装介绍Scrapy框架官方网址:http://doc.scrapy.org/en/latestScrapy中文维护站点:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.htmlWindows 安装方式Python 2 / 3升级...
爬虫进阶:Scrapy入门
进阶前言 学Py和写爬虫都有很长一段时间了,虽然工作方面主要还是做Java开发,但事实上用python写东西真的很爽。之前都是用Requests+BeautifulSoup这样的第三方库爬一些简单的网站,好处简单上手快,坏处也明显,单线程速度慢,偶尔想要跑快点还得自己写多线程或者多进程。其实早已...
分布式爬虫scrapy+redis入门
利用分布式爬虫scrapy+redis爬取伯乐在线网站,网站网址:http://blog.jobbole.com/all-posts/ 后文中详情写了整个工程的流程,即时是新手按照指导走也能使程序成功运行。 1.下载64位redis软件 软件很小,4M,下载链接: https://pan.baidu...
爬虫入门之Scrapy框架实战(新浪百科豆瓣)(十二)
一 新浪新闻爬取 1 爬取新浪新闻(全站爬取) 项目搭建与开启 scrapy startproject sina cd sina scrapy genspider mysina http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_2.shtml 2 ...
爬虫入门之Scrapy框架基础LinkExtractors(十一)
1 parse()方法的工作机制: 1. 因为使用的yield,而不是return。parse函数将会被当做一个生成器使用。scrapy会逐一获取parse方法中生成的结果,并判断该结果是一个什么样的类型; 2. 如果是request则加入爬取队列,如果是item类型则使用pipeline处理,其他...
爬虫入门之Scrapy框架基础框架结构及腾讯爬取(十)
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据。 如果安装了 IPython ,Scrapy终端将使用 IPython (替代标准Python终端)。 IPython 终端...
爬虫入门之Scrapy 框架基础功能(九)
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。 Scrapy 使用了 Twisted(其主要对手是Tornado)多线程异步网络框架来处...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子

