项目配置之道:优化Scrapy参数提升爬虫效率
前言在当今信息时代,数据是无处不在且无比重要的资源。为了获取有效数据,网络爬虫成为了一项至关重要的技术。Scrapy作为Python中最强大的网络爬虫框架之一,提供了丰富的功能和灵活的操作,让数据采集变得高效而简单。本文将以爬取豆瓣网站数据为例,分享Scrapy的实际应用和技术探索。Scrapy简介...
Python:Scrapy传入自定义参数运行
运行命令# 运行爬虫 $ scrapy crawl spiderName # 传入自定义参数运行 $ scrapy crawl spiderName -a parameter1=value1 -a parameter2=value2示例:通过3种方式获取传入的参数# -*- coding: utf-...
Python爬虫:Scrapy优化参数设置
修改 settings.py 文件# 增加并发 CONCURRENT_REQUESTS = 100 # 降低log级别 LOG_LEVEL = 'INFO' # 禁止cookies COOKIES_ENABLED = False # 禁止重试 RETRY_ENABLED = Fa...
Python爬虫:scrapy-splash的请求头和代理参数设置
3中方式任选一种即可1、lua中脚本设置代理和请求头:function main(splash, args) -- 设置代理 splash:on_request(function(request) request:set_proxy{ host = "27.0.0.1", p...
Python爬虫:scrapy中间件及一些参数
scrapy中间件from scrapy.settings import default_settings 'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100, 'scrapy.downloadermiddlewares...
Python爬虫:scrapy框架Spider类参数设置
Python爬虫:scrapy框架Spider类参数设置
Python爬虫:scrapy框架Spider类参数设置
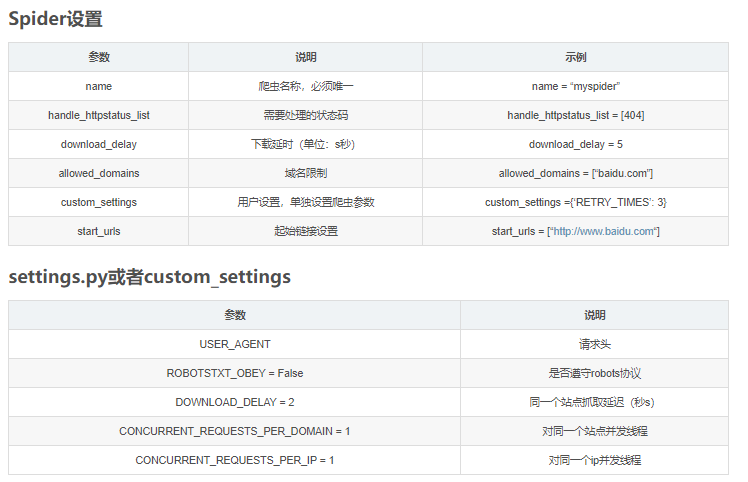
Spider设置参数说明示例name爬虫名称,必须唯一name = “myspider”handle_httpstatus_list需要处理的状态码handle_httpstatus_list = [404]download_delay下载延时(单位:s秒)download_delay = 5all...
Scrapy:如何使用多个搜索项的参数
我正在玩scrapy,现在我尝试搜索不同的关键字,从命令行工具传递参数。 基本上,我想定义一个关键字,爬虫应该搜索包含这个关键字的url。 这是我的命令行: scrapy crawl myfirst -a nombre="Vermont" 这是我的履带: class myfirstSpider(Cr...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子

