[帮助文档] 使用AI通信加速库DeepNCCL加速模型的分布式训练或推理性能
DeepNCCL是阿里云神龙异构产品开发的用于多GPU互联的AI通信加速库,能够无感地加速基于NCCL进行通信算子调用的分布式训练或多卡推理等任务。开发人员可以根据实际业务情况,在不同的GPU云服务器上安装DeepNCCL通信库,以加速分布式训练或推理性能。本文主要介绍在Ubuntu或CentOS操...
[帮助文档] 基于AIACC加速器快速实现Stable Diffusion生成特定物体图片
本文介绍如何使用GPU云服务器搭建Stable Diffusion模型,并基于ControlNet框架,快速生成特定物体图片。
[帮助文档] 如何使用AIACC-TrainingMXNet版训练加速
由于MXNet支持KVStore和Horovod两种分布式训练方式,因此AIACC-Training 1.5能够支持使用KVStore的方式对MXNet分布式训练进行加速,同时支持Horovod的分布式训练方式,并且能够无缝兼容Horovod的API版本。
[帮助文档] 使用Deepytorch Inference实现模型的推理性能优化_GPU云服务器(EGS)
Deepytorch Inference是阿里云自研的AI推理加速器,针对Torch模型,可提供显著的推理加速能力。本文主要介绍安装并使用Deepytorch Inference的操作方法,以及推理效果展示。
[帮助文档] Deepytorch Inference推理加速介绍、优势及模型限制_GPU云服务器(EGS)
Deepytorch Inference是阿里云自研的AI推理加速器,专注于为Torch模型提供高性能的推理加速。通过对模型的计算图进行切割、执行层融合以及高性能OP的实现,大幅度提升PyTorch的推理性能。本文介绍Deepytorch Inference在推理加速方面的概念、优势及模型支持情况。
pytorch在GPU上运行模型实现并行计算
pytorch在GPU上运行模型十分简单,只需要以下两部:model = model.cuda():将模型的所有参数都转存到GPU上input.cuda():将输入数据放置到GPU上至于如何在多块GPU上进行并行计算,PyTorch也提供了两个函数,可以实现简单、高效的GPU并行计算。nn.para...
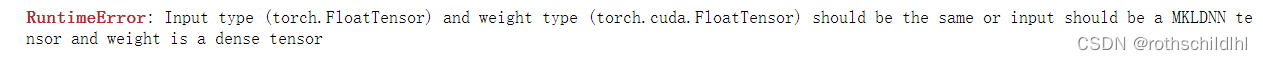
基于Pytorch使用GPU运行模型方法及可能出现的问题解决方法
基于Pytorch使用GPU运行模型方法及注意事项一、在基于pytorch深度学习进行模型训练和预测的时候,往往数据集比较大,而且模型也可能比较复杂,但如果直接训练调用CPU运行的话,计算运行速度很慢,因此使用GPU进行模型训练和预测是非常有必要的,可以大大提高实验效率。如果还没有配置好运行环境的博...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子



最佳实践
更多




GPU云服务器模型相关内容
- 模型GPU云服务器
- modelscope模型GPU云服务器推理
- 导出模型GPU云服务器
- modelscope模型GPU云服务器
- 模型GPU云服务器推理
- 模型设置GPU云服务器
- modelscope模型GPU云服务器运行
- 加载模型GPU云服务器
- GPU云服务器模型文件
- 模型GPU云服务器报错
- modelscope模型GPU云服务器报错
- pytorch模型GPU云服务器
- GPU云服务器加载模型
- GPU云服务器训练模型
- 自定义GPU云服务器模型文件
- GPU云服务器实验室模型
- 版本模型GPU云服务器
- GPU云服务器模型训练
- modelscope模型GPU云服务器设置
- GPU云服务器开源模型
- GPU云服务器文本模型
- 模型GPU云服务器环境