【大数据技术Spark】Spark SQL操作Dataframe、读写MySQL、Hive数据库实战(附源码)
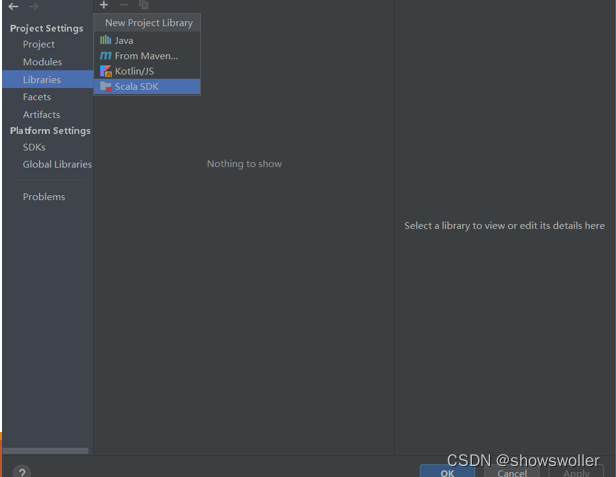
需要源码和依赖请点赞关注收藏后评论区留言私信~~~一、Dataframe操作步骤如下1)利用IntelliJ IDEA新建一个maven工程,界面如下2)修改pom.XML添加相关依赖包3)在工程名处点右键,选择Open Module Settings4)配置Scala Sdk,界面如下5)新建文件...
大数据计算MaxCompute中使用jar 调用 SDK 可以读写表吗?
大数据计算MaxCompute中使用jar 调用 SDK 可以读写表吗? 比直接写sql任务方便吗? 业务逻辑比较复杂

大数据计算MaxCompute有办法直接给某个账号赋予表的读写权限吗?
大数据计算MaxCompute有办法直接给某个账号赋予表的读写权限吗?现在要一张表一张表的申请有点麻烦
大数据计算MaxCompute 有Python可以直接读写方案吗? 不通过pyODPS
大数据计算MaxCompute 有Python可以直接读写方案吗? 不通过pyODPS
MaxCompute如果handle函数里涉及了对全局变量的读写操作,请问要考虑脏数据的问题吗?
问题1:MaxCompute在pyodps里使用df.apply的时候,如果handle函数里涉及了对全局变量的读写操作,请问要考虑脏数据的问题吗?apply分布式执行的时候会不会自行保证数据的一致性?问题2:比如说假如handle方法里面使用了一个全局的计数器,每调用一次就+1,也就是说最后这个计...
大数据数据存储的搜索引擎Elasticsearch的调优的磁盘读写优化
但是,在使用Elasticsearch时,磁盘读写优化也是一个重要的考虑因素。 以下是一些关于Elasticsearch调优的磁盘读写优化的建议:合适的索引结构:应该使用合适的索引结构,以便更好地支持查询。数据类型:应该使用合适的数据类型,以便更好地支持查询。分布式特性:可以使用Ela...
请问通过MaxCompute服务读写OSS需要注意什么?
请问通过MaxCompute服务读写OSS需要注意什么?
[帮助文档] 如何使用OSS外部表根据字段名称对数据进行读写
OSS支持用户在OSS目录下上传不同表结构的数据,MaxCompute建立的OSS外部表可以根据字段名称对数据进行读写。本文为您介绍在MaxCompute中使用OSS外部表根据字段名称对数据进行读写。
maxcompute同一个分区支持同时读写吗?
如果不是分区表,而是非分区表的话,是否能够支持同时读写呢?
[帮助文档] 如何读写MaxCompute数据
现有湖仓一体架构是以MaxCompute为中心读写Hadoop集群数据,有些线下IDC场景,客户不愿意对公网暴露集群内部信息,需要从Hadoop集群发起访问云上的数据。本文以开源大数据开发平台E-MapReduce(云上Hadoop)方式模拟本地Hadoop集群,为您介绍如何读写MaxCompute...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute数据同步
- 云原生大数据计算服务 MaxCompute配置
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute表数据
- 云原生大数据计算服务 MaxCompute实时同步
- 云原生大数据计算服务 MaxCompute单表
- 云原生大数据计算服务 MaxCompute方案
- 云原生大数据计算服务 MaxCompute订阅
- 云原生大数据计算服务 MaxCompute mysql
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute项目