[帮助文档] 如何使用TableWriterAPI对MaxCompute表进行读写
您可以使用TableWriter API对MaxCompute表进行读写。
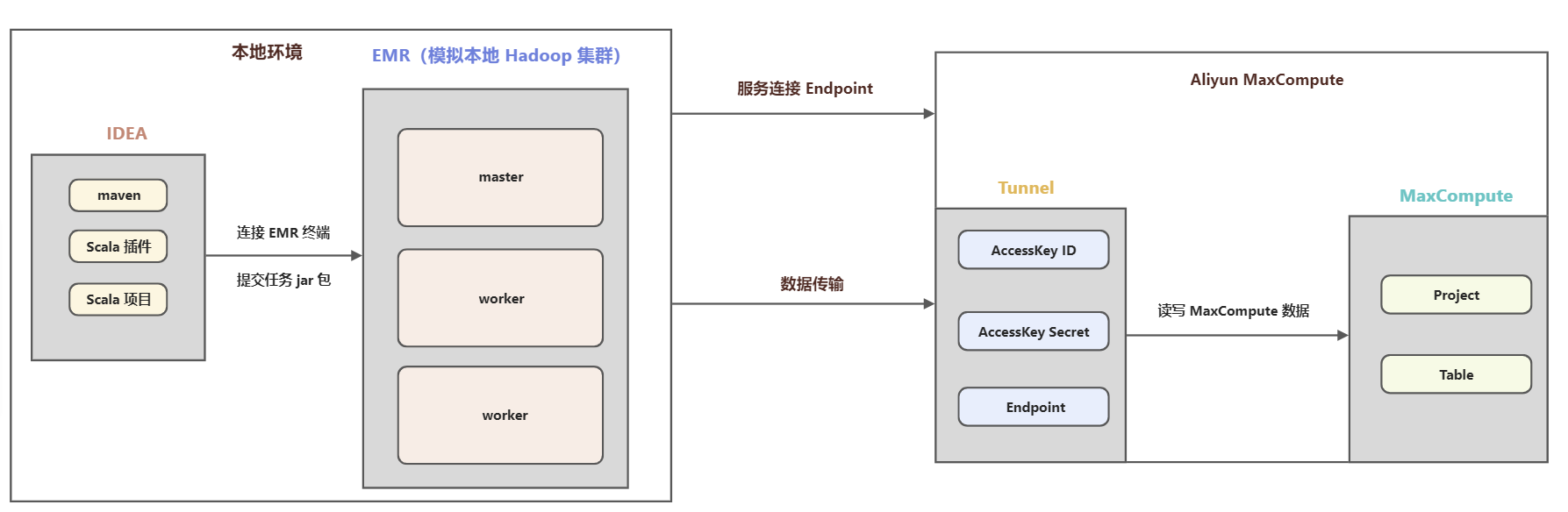
模拟IDC spark读写MaxCompute实践
一、背景1、背景信息 现有湖仓一体架构是以 MaxCompute 为中心读写 Hadoop 集群数据,有些线下 IDC 场景,客户不愿意对公网暴露集群内部信息,需要从 Hadoop 集群发起访问云上的数据。本文以 EMR (云上 Hadoop)方式模拟本地 Hadoop 集群访问 MaxComput...

为什么说HBase 大数据随机和实时读写?
为什么说HBase 大数据随机和实时读写?
带你入坑大数据(二) --- HDFS的读写流程和一些重要策略
前言 前情回顾 如果说上一篇是在阐述HDFS最基础的理论知识,这一篇就是HDFS的主要工作流程,和一些较为有用的策略 补充一个问题,就是当我们 NameNode 挂掉,SecondaryNameNode作为新的NameNode上位时,它确实可以根据fsimage.ckpt把一部分元数据加载到内存,可...
如何使用MaxCompute Spark读写阿里云Hbase
背景 Spark on MaxCompute可以访问位于阿里云VPC内的实例(例如ECS、HBase、RDS),默认MaxCompute底层网络和外网是隔离的,Spark on MaxCompute提供了一种方案通过配置spark.hadoop.odps.cupid.vpc.domain.list来...
读写MaxCompute时,抛出java.lang.RuntimeException.Parse r
读写MaxCompute时,抛出java.lang.RuntimeException.Parse response failed: ‘…’?
MaxCompute与OSS非结构化数据读写互通(及图像处理实例)
0. 前言 MaxCompute作为阿里巴巴集团内部绝大多数大数据处理需求的核心计算组件,拥有强大的计算能力,随着集团内外大数据业务的不断扩展,新的数据使用场景也在不断产生。在这样的背景下,MaxCompute(ODPS)计算框架持续演化,而原来主要面对内部特殊格式数据的强大计算能力,也正在一步步的...
《深入理解大数据:大数据处理与编程实践》一一3.3 HDFS文件存储组织与读写
本节书摘来自华章计算机《深入理解大数据:大数据处理与编程实践》一书中的第3章,第3.3节,作者 主 编:黄宜华(南京大学)副主编:苗凯翔(英特尔公司),更多章节内容可以访问云栖社区“华章计算机”公众号查看。 3.3 HDFS文件存储组织与读写 作为一个分布式文件系统,HDFS内部的数据与文件存储机制...
新建子管理账号,授权“读写所有云资源”权限,但子账号不能访问大数据(数加)里面的功能(大数据开发套件)
新建子管理账号,授权“读写所有云资源”权限,但子账号不能访问大数据(数加)里面的功能(大数据开发套件)
E-MapReduce中Spark 2.x读写MaxCompute数据
最新的aliyun-emapreduce-sdk将MaxCompute数据以DataSource的方式接入Spark 2.x,用户可以使用类似Spark 2.x中读写json/parquet/csv的方式来访问MaxCompute. 0. DataSource a) DataSource提供了一种插...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute异步
- 云原生大数据计算服务 MaxCompute外表
- 云原生大数据计算服务 MaxCompute导出
- 云原生大数据计算服务 MaxCompute hologres
- 云原生大数据计算服务 MaxCompute oss
- 云原生大数据计算服务 MaxCompute parquet
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute数据导出
- 云原生大数据计算服务 MaxCompute数据集
- 云原生大数据计算服务 MaxCompute文件
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute产品