绕开算力限制,如何用单GPU微调 LLM?这是一份「梯度累积」算法教程(2)
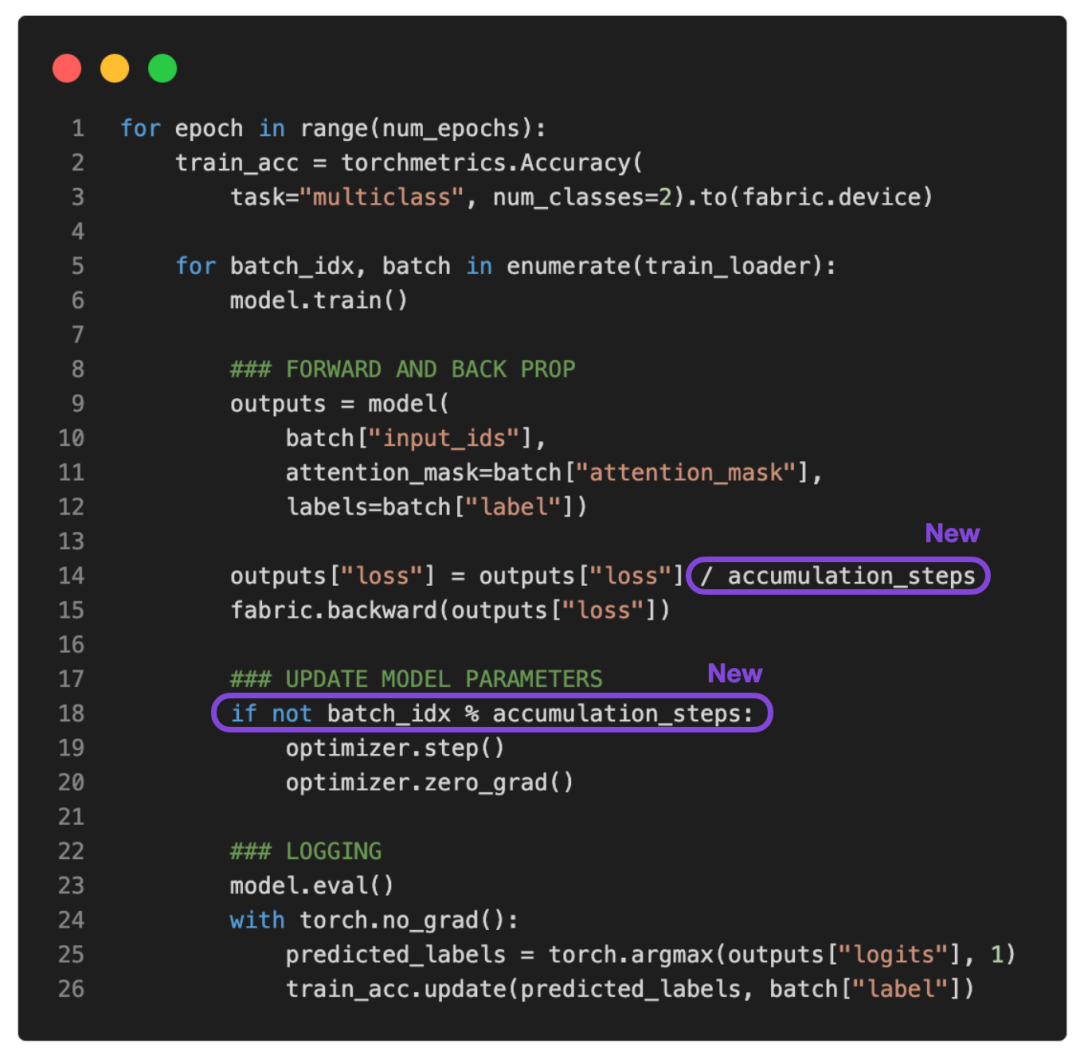
由于没有多的 GPU 可用于张量分片(tensor sharding),又能做些什么来训练具有更大批大小(batch size)的模型呢?其中一种解决方法就是梯度累积,可以通过它来修改前面提到的训练循环。什么是梯度积累?梯度累积是一种在训练期间虚拟增加批大小(batch ...

绕开算力限制,如何用单GPU微调 LLM?这是一份「梯度累积」算法教程
让算力资源用到极致,是每一位开发者的必修课。自从大模型变成热门趋势之后,GPU 就成了紧俏的物资。很多企业的储备都不一定充足,更不用说个人开发者了。有没有什么方法可以更高效的利用算力训练模型?在最近的一篇博客,Sebastian Raschka 介绍了「梯度累积」的方法,能够在 GPU 内存受限时使...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。






