[帮助文档] 如何通过ES-Hadoop实现Hive读写阿里云Elasticsearch数据_检索分析服务 Elasticsearch版(ES)
ES-Hadoop是Elasticsearch推出的专门用于对接Hadoop生态的工具,可以让数据在Elasticsearch和Hadoop之间双向移动,无缝衔接Elasticsearch与Hadoop服务,充分使用Elasticsearch的快速搜索及Hadoop批处理能力,实现交互式数据处理。本...
[帮助文档] 如何通过ES-Hadoop实现Spark读写阿里云Elasticsearch数据_检索分析服务 Elasticsearch版(ES)
Spark是一种通用的大数据计算框架,拥有Hadoop MapReduce所具有的计算优点,能够通过内存缓存数据为大型数据集提供快速的迭代功能。与MapReduce相比,减少了中间数据读取磁盘的过程,进而提高了处理能力。本文介绍如何通过ES-Hadoop实现Hadoop的Spark服务读写阿里云El...

[帮助文档] 如何通过ES-Hadoop将HDFS中的数据写入Elasticsearch_检索分析服务 Elasticsearch版(ES)
ES-Hadoop是Elasticsearch推出的专门用于对接Hadoop生态的工具,可以让数据在Elasticsearch和Hadoop之间双向移动,无缝衔接Elasticsearch与Hadoop服务,充分使用Elasticsearch的快速搜索及Hadoop批处理能力,实现交互式数据处理。对...
[帮助文档] 如何迁移自建Kudu集群的数据到EMR上的Hadoop集群_EMR on ECS_开源大数据平台 E-MapReduce(EMR)
E-MapReduce(简称EMR)支持将您本地自建的Kudu集群迁移至EMR上。本文为您介绍如何迁移自建Kudu集群的数据到E-MapReduce上的Hadoop集群。
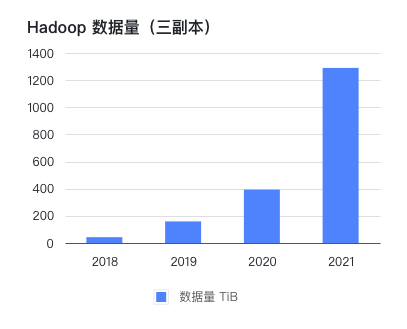
一面数据: Hadoop 迁移云上架构设计与实践
背景一面数据创立于 2014 年,是一家领先的数据智能解决方案提供商,通过解读来自电商平台和社交媒体渠道的海量数据,提供实时、全面的数据洞察。长期服务全球快消巨头(宝洁、联合利华、玛氏等),获得行业广泛认可。公司与阿里、京东、字节合作共建多个项目,旗下知乎数据专栏“数据冰山”拥有超30万粉丝。一面所...
[帮助文档] 如何将Hadoop文件系统上的数据迁移至JindoFS
本文以OSS为例,介绍如何将Hadoop文件系统上的数据迁移至JindoFS。
数据到hadoop的迁移
最近在用flume和sqoop来做非关系数据(日志)和关系数据(MYSQL)迁移到hdfs的工作,简单记录下使用过程,以此总结 一 flume的使用 使用flume把web的log日志数据导入到hdfs上 步骤 1 在 elephant 节点上 先安装flume sudo yum install -...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








