[帮助文档] 如何迁移自建Kudu集群的数据到EMR上的Hadoop集群
E-MapReduce(简称EMR)支持将您本地自建的Kudu集群迁移至EMR上。本文为您介绍如何迁移自建Kudu集群的数据到E-MapReduce上的Hadoop集群。
[帮助文档] 如何通过ES-Hadoop实现Hive读写阿里云Elasticsearch数据
ES-Hadoop是Elasticsearch推出的专门用于对接Hadoop生态的工具,可以让数据在Elasticsearch和Hadoop之间双向移动,无缝衔接Elasticsearch与Hadoop服务,充分使用Elasticsearch的快速搜索及Hadoop批处理能力,实现交互式数据处理。本...

Hadoop学习---7、OutputFormat数据输出、MapReduce内核源码解析、Join应用、数据清洗、MapReduce开发总结(二)
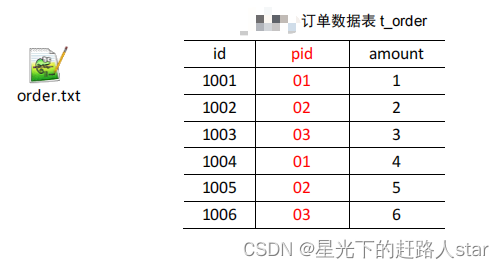
3、Join应用3.1 Reduce Join(1)Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。(2)Reduce端的主要工作:在Reduce端以连接...
Hadoop学习---7、OutputFormat数据输出、MapReduce内核源码解析、Join应用、数据清洗、MapReduce开发总结(一)
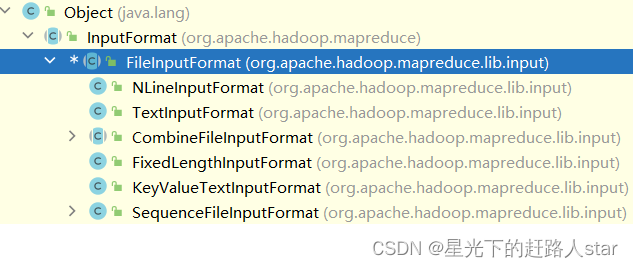
1、OutputFormat数据输出1.1 OutputFormat接口实现类OutputFormat是MapReduce输出的基类,所以实现MapReduce输出都实现了OutputFormat接口。1、MapReduce默认的输出格式是TextOutputFormat2、也可以自定义Output...
[帮助文档] 如何通过ES-Hadoop实现Spark读写阿里云Elasticsearch数据
Spark是一种通用的大数据计算框架,拥有Hadoop MapReduce所具有的计算优点,能够通过内存缓存数据为大型数据集提供快速的迭代功能。与MapReduce相比,减少了中间数据读取磁盘的过程,进而提高了处理能力。本文介绍如何通过ES-Hadoop实现Hadoop的Spark服务读写阿里云El...
[帮助文档] 如何通过ES-Hadoop将HDFS中的数据写入Elasticsearch
ES-Hadoop是Elasticsearch推出的专门用于对接Hadoop生态的工具,可以让数据在Elasticsearch和Hadoop之间双向移动,无缝衔接Elasticsearch与Hadoop服务,充分使用Elasticsearch的快速搜索及Hadoop批处理能力,实现交互式数据处理。对...
[帮助文档] 如何将Hadoop文件系统上的数据迁移至JindoFS
本文以OSS为例,介绍如何将Hadoop文件系统上的数据迁移至JindoFS。
hadoop streaming多路输出方法和注意点(附超大数据diff对比源码)
简介 hadoop 支持reduce多路输出的功能,一个reduce可以输出到多个part-xxxxx-X文件中,其中X是A-Z的字母之一,程序在输出<key,value>对的时候,在value的后面追加"#X"后缀,比如#A,输出的文件就是part-00000-A,不同的后缀可以把ke...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








