[帮助文档] 如何通过ServerlessSpark访问OSS数据源_云原生数据湖分析
本文介绍如何通过Serverless Spark访问OSS数据源。您需要先配置访问OSS的权限,然后可以使用SQL的方式或者提交代码包(Python或者Jar包)的方式访问OSS。

大数据Hadoop之——Apache Hudi 数据湖实战操作(Spark,Flink与Hudi整合)
一、概述Hudi(Hadoop Upserts Deletes and Incrementals),简称Hudi,是一个流式数据湖平台,支持对海量数据快速更新,内置表格式,支持事务的存储层、 一系列表服务、数据服务(开箱即用的摄取工具)以及完善的运维监控工具,它可以以极低的延迟将数据快...

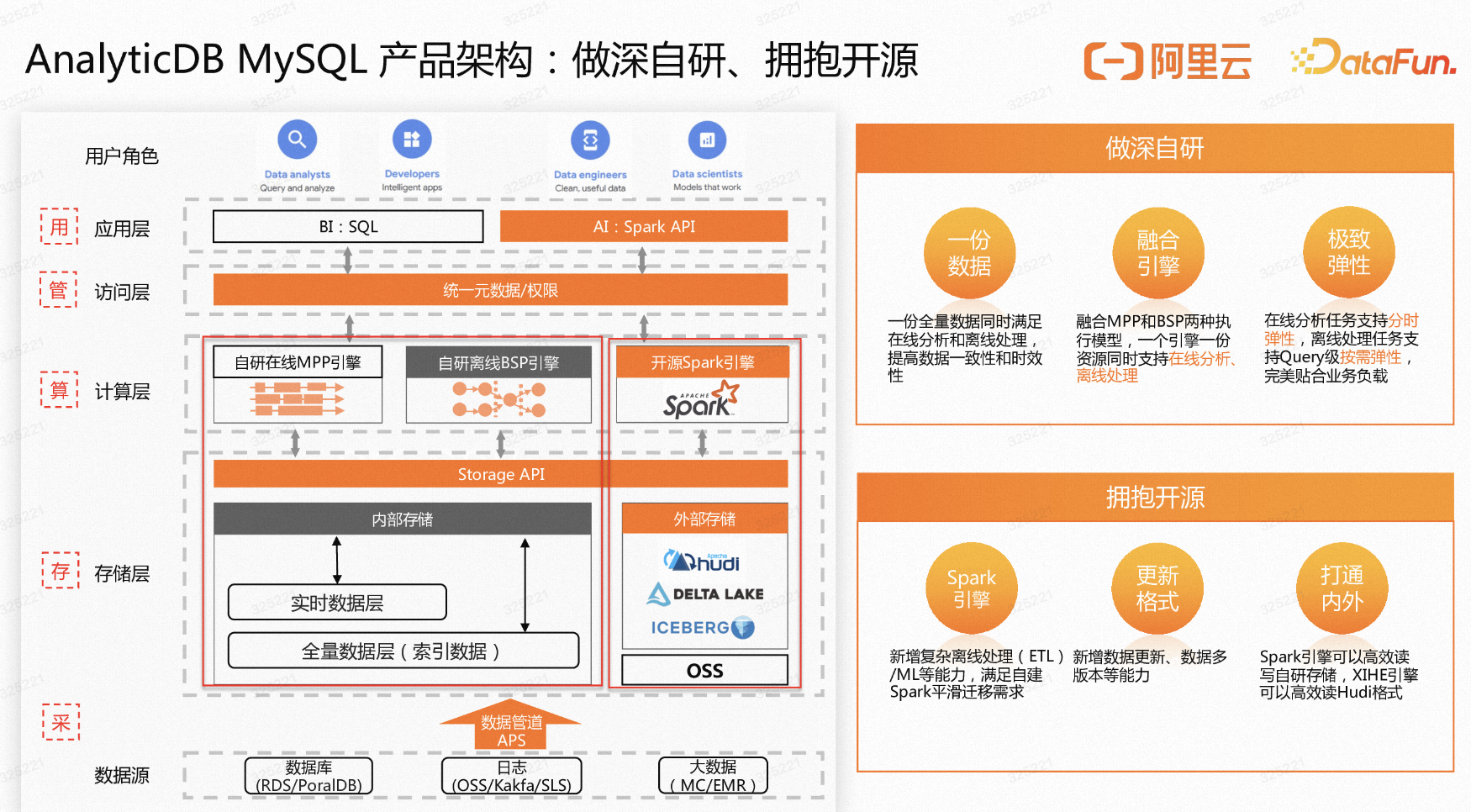
AnalyticDB MySQL — Spark 助力在OSS上构建低成本数据湖
【先打一波小广告】阿里云AnalyticDB MySQL升级为湖仓一体架构,支持高吞吐离线处理和高性能在线分析,可无缝替换CDH/TDH/Databricks/Presto/Spark/Hive等。1.目前湖仓版开放了线上训练营,参加实验免费赢耳机/充电宝/卫衣等好礼,报名链接:https://de...

深度干货|谈谈阿里云AnalyticDB Spark如何构建低成本数据湖分析
文/李少锋阿里云瑶池旗下的云原生数据仓库AnalyticDB MySQL版是基于湖仓一体架构打造的实时湖仓。本文将分享AnalyticDB MySQL Spark助力构建低成本数据湖分析的最佳实践。全文目录:AnalyticDB MySQL介绍AnalyticDB MySQL Serverless ...
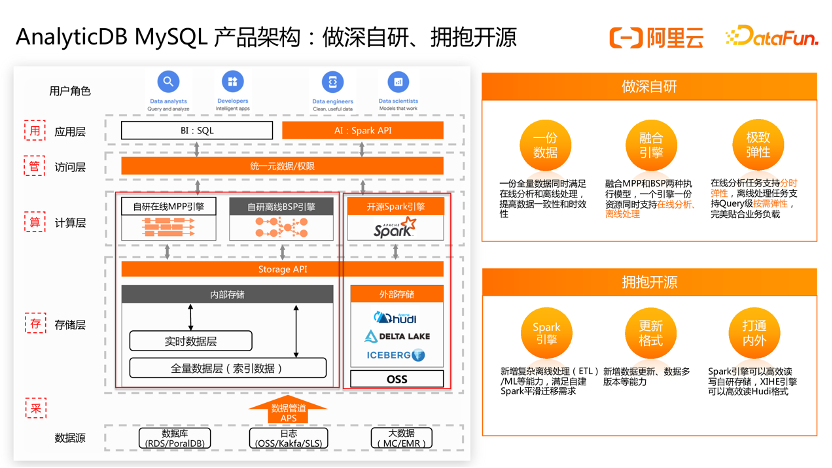
AnalyticDB MySQL Spark 助力在OSS上构建低成本数据湖
前言随着互联网的发展,数据量的爆炸式增长已经成为明显趋势。在这种情况下,企业、政府等各种机构都面临着如何存储,管理和分析庞大的数据量的问题。阿里云对象存储OSS(Object Storage Service)是阿里云提供的海量、安全、低成本、高可靠的云存储服务。OSS对象存储采用...

大数据技术解析:Hadoop、Spark、Flink和数据湖的对比
随着数字化时代的到来,数据已经成为企业和组织的重要资产之一。为了更好地处理、分析和挖掘海量数据,大数据技术逐渐崭露头角。在本文中,我们将深入探讨大数据处理领域中的一些关键技术,包括 Hadoop、Spark、Flink 和数据湖,分析它们的优势、劣势以及适用场景。 Hadoop Hadoop 是一个...
[帮助文档] 使用PythonSDK操作数据湖分析的Spark作业
本文将演示如何使用Python SDK提交一个计算π的任务,查看任务的状态和日志,超时终止任务, 以及查看虚拟集群的历史状态。
[帮助文档] 如何通过RAM子账号访问其他账号的OSS资源并提交Spark作业_云原生数据湖分析
本文主要介绍RAM子账号如何访问其他账号的OSS资源并提交Spark作业。
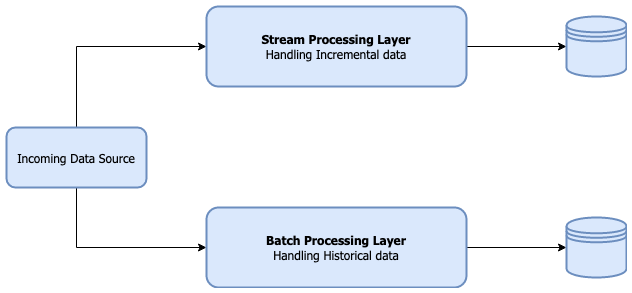
使用Apache Spark和Apache Hudi构建分析数据湖
1. 引入大多数现代数据湖都是基于某种分布式文件系统(DFS),如HDFS或基于云的存储,如AWS S3构建的。遵循的基本原则之一是文件的“一次写入多次读取”访问模型。这对于处理海量数据非常有用,如数百GB到TB的数据。但是在构建分析数据湖时,更新数据并不罕见。根据不同场景,这些更新频率可能是每小时...
[帮助文档] 如何使用DMS来编排调度Spark任务
DLA Serverless Spark目前支持DataWorks和DMS编排调度任务,同时也提供自定义SDK和Spark-Submit工具包供用户自定义编排调度。本文将介绍如何使用DMS来编排调度Spark任务。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。