大数据Spark DataFrame/DataSet常用操作2
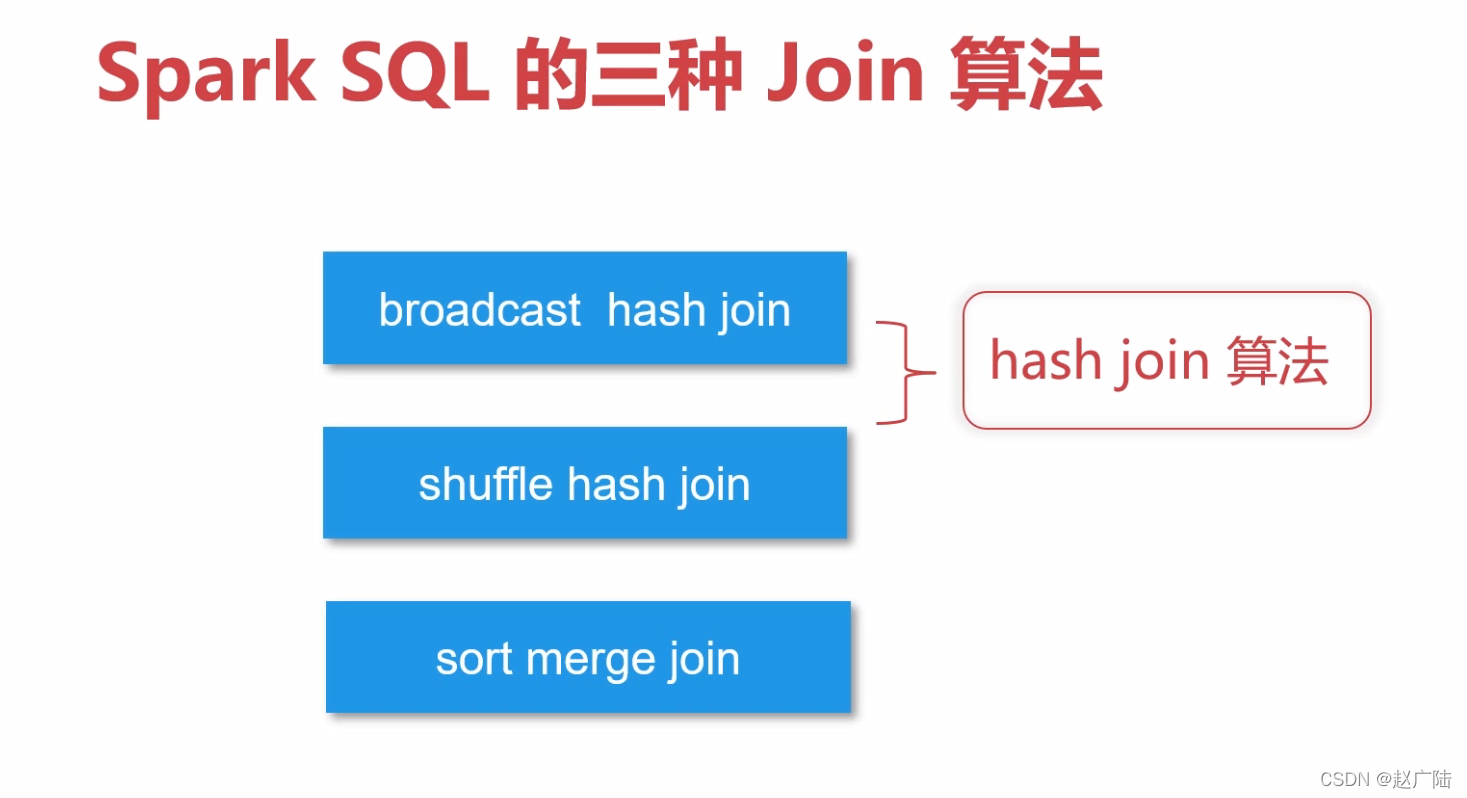
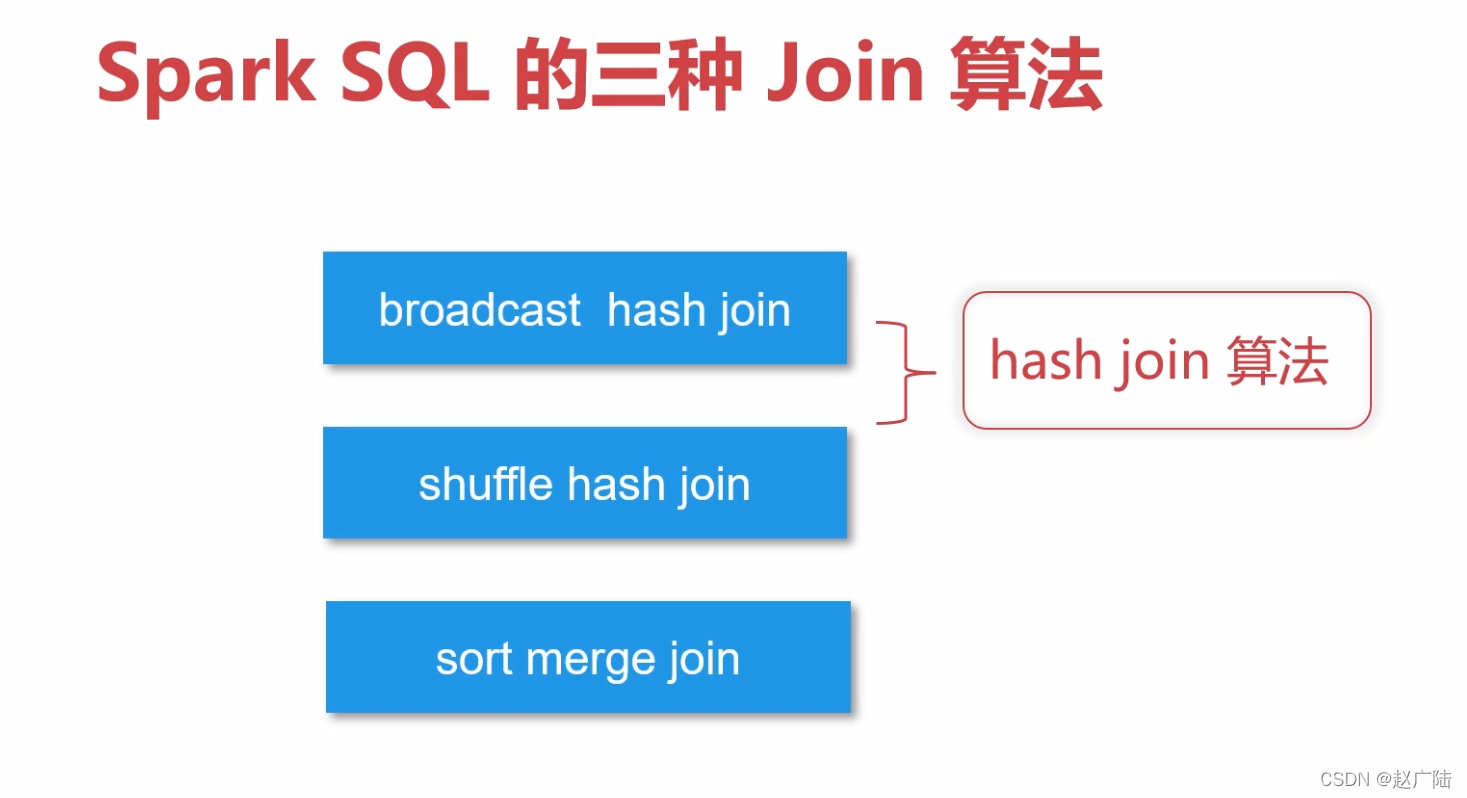
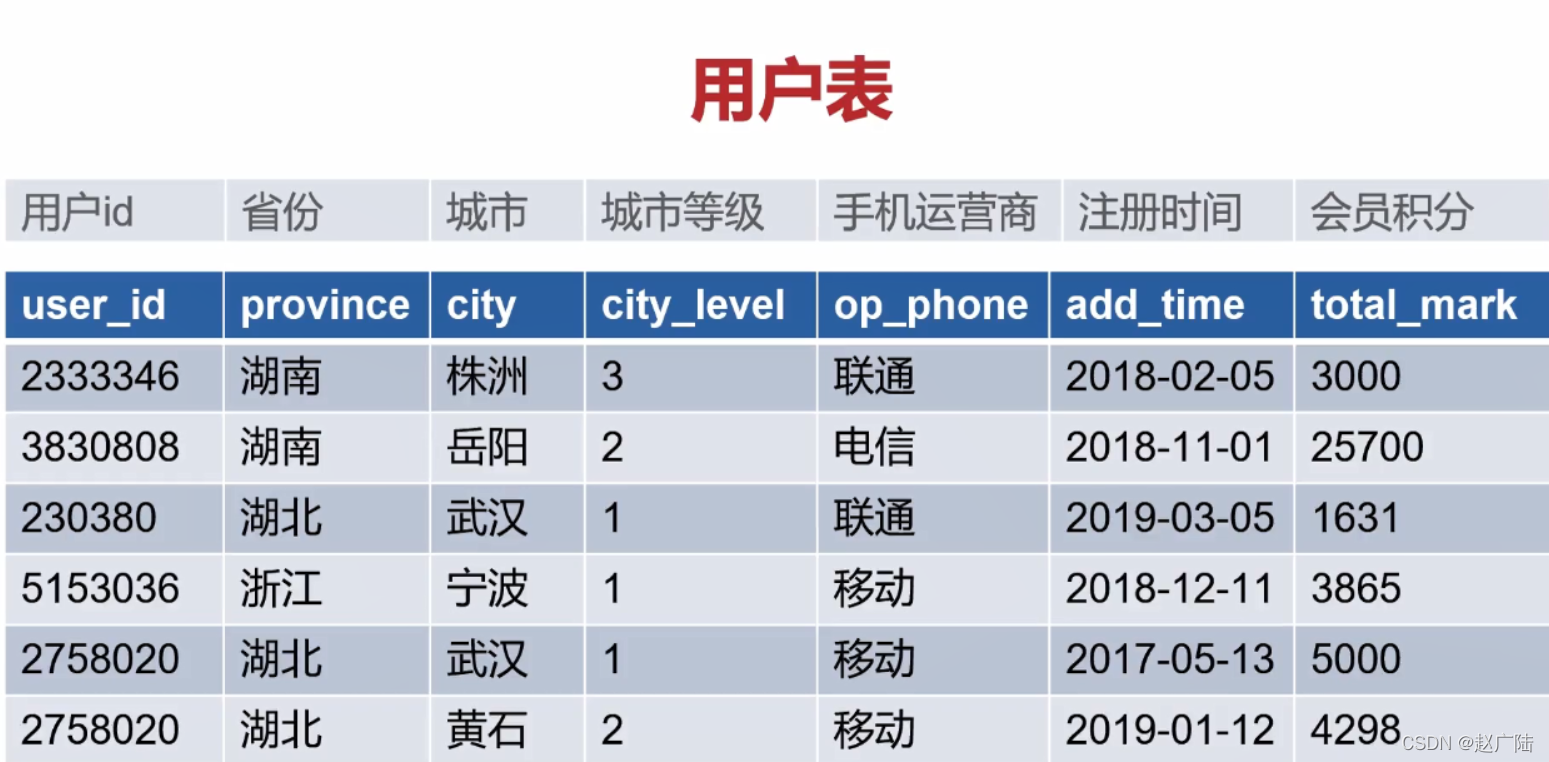
3 多表操作Join3.1 数据准备先构建两个DataFramescala> val df1 = spark.createDataset(Seq(("a", 1,2), ("b",2,3) )).toDF("k1","k2","k3") df1: org.apache.spark.sql.Da...

大数据Spark DataFrame/DataSet常用操作1
1 一般操作:查找和过滤1.1 读取数据源1.1.1读取json使用spark.read。注意:路径默认是从HDFS,如果要读取本机文件,需要加前缀file://,如下scala> val people = spark.read.format("json").load("file:///o.....


大数据Spark DataFrame/DataSet常用操作4
3.2.2 其他join类型,只需把inner改成你需要的类型即可scala> df1.join(df2,Seq("k1"),"left").show +---+---+---+---+---+ | k1| k2| k3| k2| k4| +---+---+---+...
大数据Spark DataFrame/DataSet常用操作3
3 多表操作Join3.1 数据准备先构建两个DataFramescala> val df1 = spark.createDataset(Seq(("a", 1,2), ("b",2,3) )).toDF("k1","k2","k3") df1: org.apache.spark.sql.Da...
大数据Spark DataFrame/DataSet常用操作2
2 聚合操作:groupBy和agg2.1 排序算子sort(sort等价于orderBy)DF.sort(DF.col(“id”).desc).show 以DF中字段id降序,指定升降序的方法。另外可指定多个字段排序=DF.sort($“id”.desc).showDF.sort 等价于DF.or...
[帮助文档] 如何使用Spark的DataFrame方式访问表格存储
使用Spark的DataFrame方式访问表格存储,并在本地和集群上分别进行运行调试。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache sparkdataframe相关内容
- dataframe apache spark
- apache spark dataframe常用操作语法
- apache spark dataframe常用操作
- apache spark dataframe区别
- apache spark rdd dataframe
- apache spark dataframe schema
- apache spark dataframe列
- apache spark创建DataFrame
- apache spark创建rdd dataframe
- apache spark dataframe排序
- apache spark sql dataframe函数一文详解方法
- apache spark rdd dataframe dataset
- alluxio apache spark dataframe
- 计算apache spark dataframe
apache spark您可能感兴趣
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark单机
- apache spark环境搭建
- apache spark案例
- apache spark测试
- apache spark streaming
- apache spark分布式
- apache spark SQL
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark Hadoop
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作