[帮助文档] 创建工作空间
工作空间是Serverless Spark的基本单元,用于管理任务、成员、角色和权限。所有的任务开发都需要在具体的工作空间内进行。因此,在开始任务开发之前,您需要先创建工作空间。本文将为您介绍如何在EMR Serverless Spark页面快速创建工作空间。
[帮助文档] Spark SQL任务快速入门
EMR Serverless Spark支持通过SQL代码编辑和运行任务。本文带您快速体验Spark SQL任务的创建、启动和运维等操作。

[帮助文档] RAM用户授权
当RAM用户(子账号)进行EMR Serverless Spark操作,例如创建、查看或删除工作空间等操作时,必须具有相应的权限。本文为您介绍如何进行RAM授权。
[帮助文档] PySpark任务开发入门
您可以自行编写并构建包含业务逻辑的Python脚本,上传该脚本后,即可便捷地创建和执行PySpark任务。本文通过一个示例,为您演示如何进行PySpark任务的开发与部署。
[帮助文档] 阿里云账号角色授权
使用EMR Serverless Spark前,需要授予您的阿里云账号AliyunServiceRoleForEMRServerlessSpark和AliyunEMRSparkJobRunDefaultRole系统默认角色。本文为您介绍角色授权的基本操作。
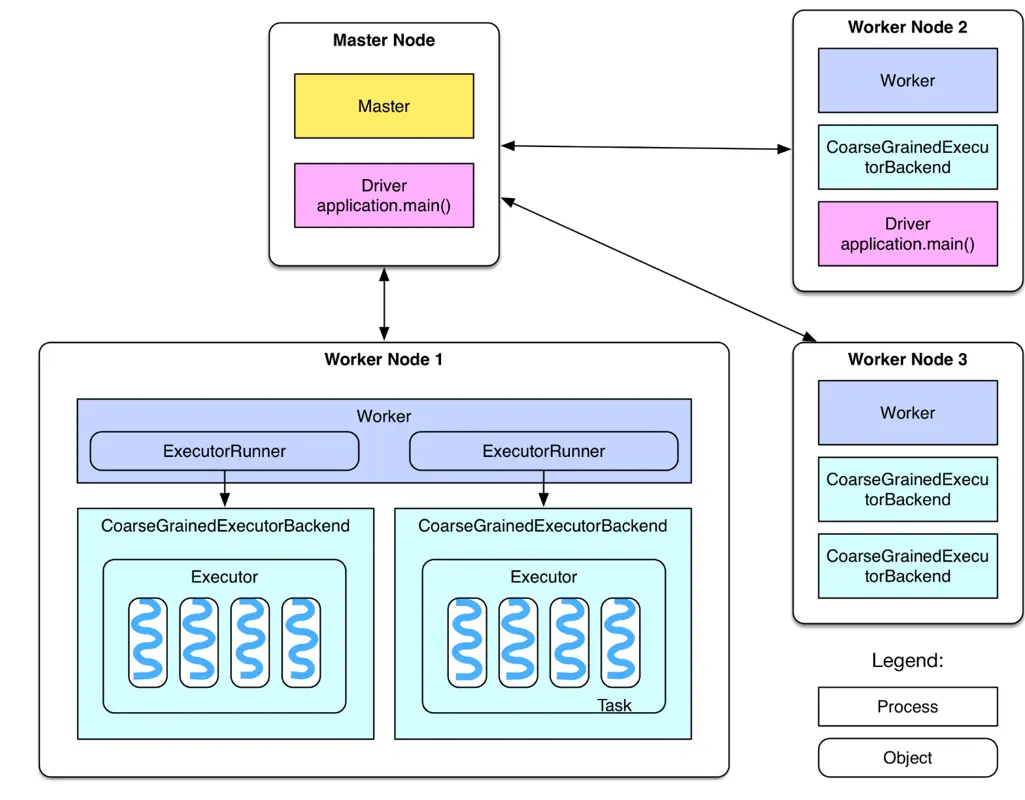
Spark 大数据实战:基于 RDD 的大数据处理分析
之前笔者参加了公司内部举办的一个 Big Data Workshop,接触了一些 Spark 的皮毛,后来在工作中陆陆续续又学习了一些 Spark 的实战知识。本文笔者从小白的视角出发,给大家普及 Spark 的应用知识。什么是 SparkSpark 集群是基于 Apache Spark 的分布式计...

Spark RDD分区和数据分布:优化大数据处理
在大规模数据处理中,Spark是一个强大的工具,但要确保性能达到最优,需要深入了解RDD分区和数据分布。本文将深入探讨什么是Spark RDD分区,以及如何优化数据分布以提高Spark应用程序的性能。 什么是RDD分区? 在Spark中,RDD(弹性分布式数据集)是数据处理的核心抽象,而RDD的分区...
Apache Spark 的基本概念和在大数据分析中的应用
Apache Spark 是一个开源的分布式计算系统,它旨在处理大规模数据集并提供高性能和易用性。Spark 提供了一个统一的编程模型,可以在多种编程语言中使用,包括 Scala、Java、Python和R。Spark 的主要特点包括: 快速:Spark 使用内存计算技术,可以比传统的批处理系统(如...
介绍 Apache Spark 的基本概念和在大数据分析中的应用。
Spark的基本概念包括:弹性分布式数据集(Resilient Distributed Dataset,简称RDD):它是Spark的核心数据结构,代表分布在集群中的可并行处理的数据集,可以在内存中存储。RDD具有容错能力,即使在节点失败时也可以自动恢复。转换操作(Transformations):...
Spark:大数据处理的下一代引擎
**引言:**随着大数据的快速增长,处理和分析大数据变得愈发重要。在这一背景下,Apache Spark作为大数据处理的下一代引擎崭露头角。它是一个开源的、快速的、通用的大数据处理框架,用于分布式数据处理和分析。本文将深入探讨Spark的核心概念、架构、应用领域,并提供示例代码,以帮助读者更好地理解...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子








云原生大数据计算服务 MaxComputespark相关内容
- 云原生大数据计算服务 MaxCompute spark区别
- 数据计算云原生大数据计算服务 MaxCompute spark oss
- 云原生大数据计算服务 MaxCompute spark程序访问
- 数据计算云原生大数据计算服务 MaxCompute spark程序访问
- 云原生大数据计算服务 MaxCompute spark local
- 云原生大数据计算服务 MaxCompute spark配置
- 云原生大数据计算服务 MaxCompute spark生态圈
- 云原生大数据计算服务 MaxCompute spark源码
- 云原生大数据计算服务 MaxCompute spark倒排索引实战
- 云原生大数据计算服务 MaxCompute spark流程
- 云原生大数据计算服务 MaxCompute spark优势
- 云原生大数据计算服务 MaxCompute spark数据模型
- 云原生大数据计算服务 MaxCompute spark sql
- 云原生大数据计算服务 MaxCompute spark编程模型
- 数据计算云原生大数据计算服务 MaxCompute spark节点
- spark引擎云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute运行spark
- 云原生大数据计算服务 MaxCompute spark hbase
- 云原生大数据计算服务 MaxCompute spark ha
- 云原生大数据计算服务 MaxCompute spark dataframe dataset常用操作
- 云原生大数据计算服务 MaxCompute spark mllib
- 云原生大数据计算服务 MaxCompute spark数据分析
- 云原生大数据计算服务 MaxCompute spark streaming queries
- 云原生大数据计算服务 MaxCompute spark streaming
- 云原生大数据计算服务 MaxCompute spark structured streaming
- 云原生大数据计算服务 MaxCompute spark external datasource
- 云原生大数据计算服务 MaxCompute spark rdd函数
- 云原生大数据计算服务 MaxCompute spark rdd
- 云原生大数据计算服务 MaxCompute spark standalone集群
- 云原生大数据计算服务 MaxCompute spark space
- 云原生大数据计算服务 MaxCompute spark运行
- 云原生大数据计算服务 MaxCompute spark任务
- 云原生大数据计算服务 MaxCompute环境spark
- 云原生大数据计算服务 MaxCompute spark设置
- 云原生大数据计算服务 MaxCompute学习spark项目实战
- 云原生大数据计算服务 MaxCompute spark版本
- 云原生大数据计算服务 MaxCompute spark设置参数
- 云原生大数据计算服务 MaxCompute spark单机
- spark云原生大数据计算服务 MaxCompute案例
- 六六云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute框架spark
- 云原生大数据计算服务 MaxCompute进阶spark sql
- 云原生大数据计算服务 MaxCompute spark调优
- 云原生大数据计算服务 MaxCompute spark executor
- 云原生大数据计算服务 MaxCompute spark场景
- 云原生大数据计算服务 MaxCompute spark打包
- 云原生大数据计算服务 MaxCompute spark参数作用
- 云原生大数据计算服务 MaxCompute spark配置项
云原生大数据计算服务 MaxCompute更多spark相关
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute数据同步
- 云原生大数据计算服务 MaxCompute配置
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute表数据
- 云原生大数据计算服务 MaxCompute实时同步
- 云原生大数据计算服务 MaxCompute单表
- 云原生大数据计算服务 MaxCompute方案
- 云原生大数据计算服务 MaxCompute订阅
- 云原生大数据计算服务 MaxCompute mysql
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute项目