[帮助文档] 通过Spark SQL Engine开发Spark SQL作业
当您需要实时分析数据或通过JDBC协议开发Spark SQL作业时,可以通过AnalyticDB for MySQL的Spark Distribution SQL Engine开发Spark SQL作业。通过Spark Distribution SQL Engine可以更方便地利用SQL分析、处理和...
[帮助文档] Spark常见错误码及其解决方法
本文汇总了AnalyticDB for MySQL Spark作业常见的错误码、报错信息、报错原因和解决办法。您可以参考本文解决报错。

[帮助文档] Spark Job资源抢占
当您希望以较低的成本执行Spark作业(包括Spark SQL作业和Spark Jar作业)时,可以为Job型资源组开启竞价实例功能。开启竞价实例功能后,集群会尝试使用闲置(更低价)的Spark Executor资源执行Spark作业。本文主要介绍什么是竞价实例,竞价实例的应用场景以及使用方法。
[帮助文档] Spark读写OSS-HDFS数据源
AnalyticDB for MySQL湖仓版(3.0)Spark支持访问OSS-HDFS数据源,本文介绍如何使用Spark来操作OSS-HDFS数据。
[帮助文档] 高性能版Spark全密态计算引擎性能测试报告_云原生数据仓库AnalyticDB MySQL版(AnalyticDB for MySQL)
本文介绍高性能版Spark全密态计算引擎与AnalyticDB for MySQL Spark的性能测试流程及对比结果,通过对比可知,在处理大规模数据集时,高性能版Spark全密态计算引擎相较于AnalyticDB for MySQL Spark 3.2.0版本的性能提升了0.9倍,具体性能对比详情...
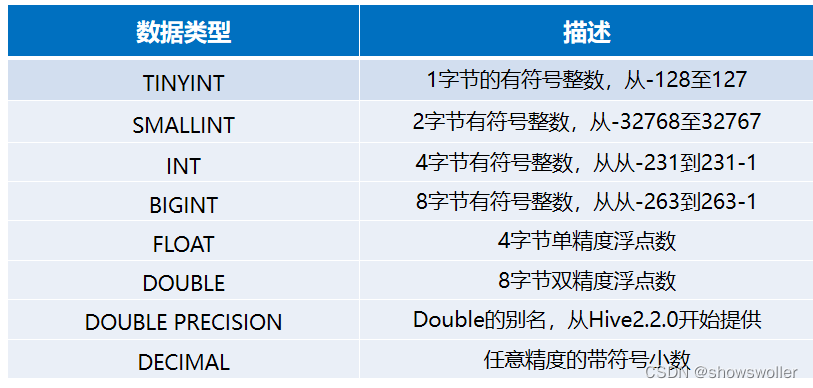
【大数据技术Hadoop+Spark】Hive数据仓库架构、优缺点、数据模型介绍(图文解释 超详细)
一、Hive简介Hive起源于Facebook,Facebook公司有着大量的日志数据,而Hadoop是实现了MapReduce模式开源的分布式并行计算的框架,可轻松处理大规模数据。然而MapReduce程序对熟悉Java语言的工程师来说容易开发,但对于其他语言使用者则难度较大。因此Facebook...
spark +hbase 数据仓库有什么资料可参考么?
3 个方面:1、业务相关2、数据同步:调度系统3、分析:spark 引擎
【Spark Summit East 2017】现代化你的数据仓库的全新“Sparkitecture”
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。 本讲义出自Myles Collins在Spark S...
【Spark Summit EU 2016】在数据仓库中引入Dataframes+Parquet
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。 本讲义出自Sol Ackerman与Franklyn...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。






