利用无头浏览器爬取JavaScript生成的网页
在进行网页爬取时,经常会遇到 JavaScript 生成的网页。由于 JavaScript 的动态渲染特性,传统的爬虫工具往往无法获取完整的页面内容。这时就需要使用无头浏览器来爬取JavaScript生成的网页,以获取所需的数据。 JavaScript生成的网页之所以无法被传统爬虫获取,是因为传统爬...
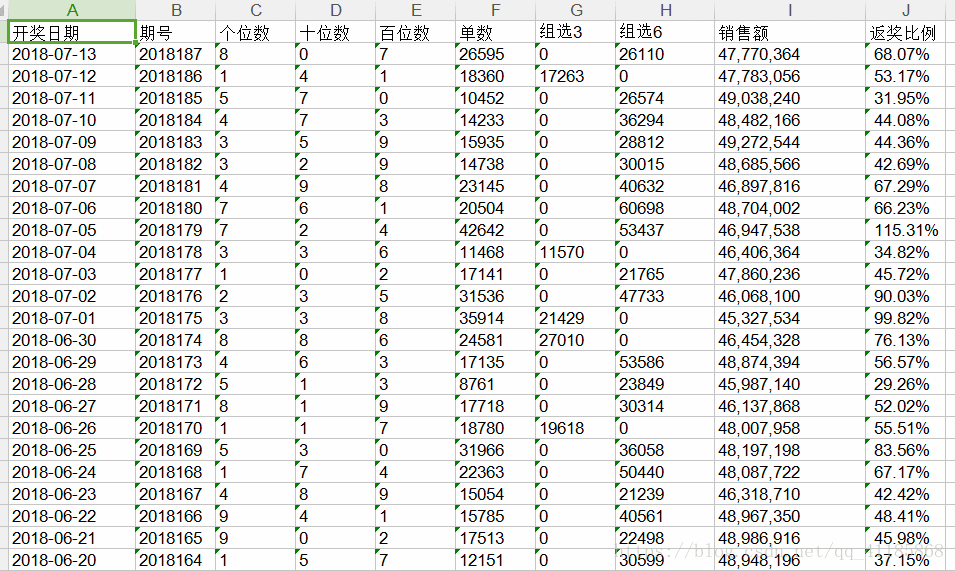
Crawler:基于BeautifulSoup库+requests库+伪装浏览器的方式实现爬取14年所有的福彩网页的福彩3D相关信息,并将其保存到Excel表格中
输出结果本来想做个科学预测,无奈,我看不懂爬到的数据……得到数据:3D(爬取的14年所有的福彩信息).rar好吧,等我看到了再用机器学习算法预测一下……完整代码,请点击获取http://1111111111111核心代码import requestsimport BeautifulSoupimpor...
用python2和python3伪装浏览器爬取网页
python网页抓取功能非常强大,使用urllib或者urllib2可以很轻松的抓取网页内容。但是很多时候我们要注意,可能很多网站都设置了防采集功能,不是那么轻松就能抓取到想要的内容。 今天我来分享下载python2和python3中都是如何来模拟浏览器来跳过屏蔽进行抓取的。 最基础的抓取: #! ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。



