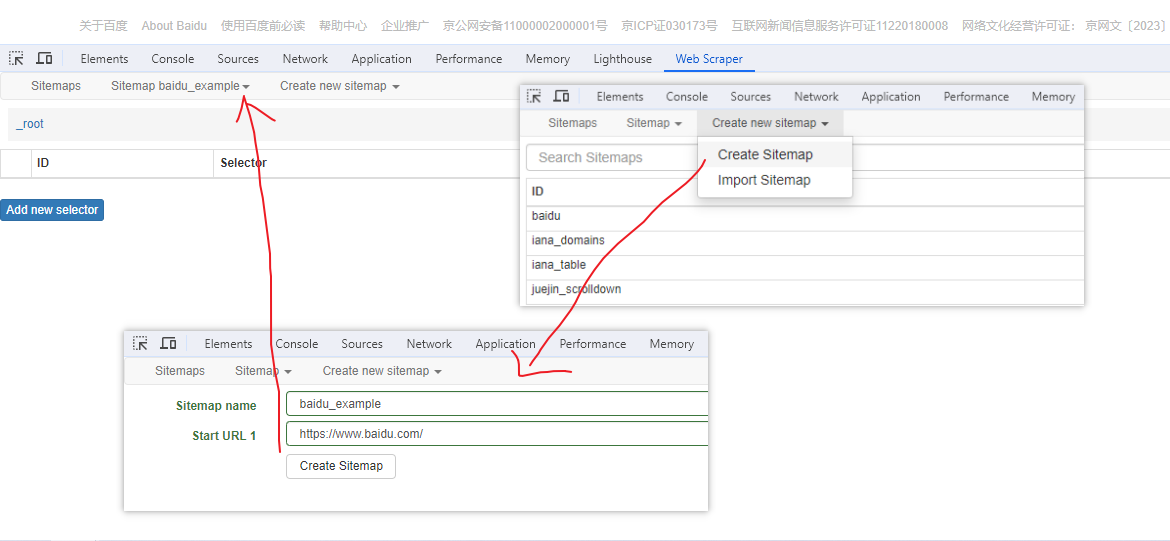
浏览器插件:WebScraper基本用法和抓取页面内容(不会编程也能爬取数据)
Web Scraper 是一个浏览器扩展,用于从页面中提取数据(网页爬虫)。对于简单或偶然的需求非常有用,例如正在写代码缺少一些示例数据,使用此插件可以很快从类似的网站提取内容作为模拟数据。从 Chrome 的插件市场安装后,页面 F12 打开开发者工具会多出一个名 Web Scraper 的面板,...
利用无头浏览器爬取JavaScript生成的网页
在进行网页爬取时,经常会遇到 JavaScript 生成的网页。由于 JavaScript 的动态渲染特性,传统的爬虫工具往往无法获取完整的页面内容。这时就需要使用无头浏览器来爬取JavaScript生成的网页,以获取所需的数据。 JavaScript生成的网页之所以无法被传统爬虫获取,是因为传统爬...

如何使用Selenium自动化Firefox浏览器进行Javascript内容的多线程和分布式爬取
概述 网页爬虫是一种自动化获取网页数据的技术,可用于数据分析、信息检索、竞争情报等。面临诸多挑战,如动态加载的Javascript内容、反爬虫机制、网络延迟、资源限制等。解决这些问题的高级爬虫技术包括Selenium自动化浏览器、多线程和分布式爬取。Selenium是开源自动化测试工具,可模拟用户在...
Crawler:基于requests库+urllib3库+伪装浏览器实现爬取抖音账号的信息数据
输出结果更新……代码设计from contextlib import closingimport requests, json, time, re, os, sys, timeimport urllib3urllib3.disable_warnings(urllib3.exceptions.Inse...
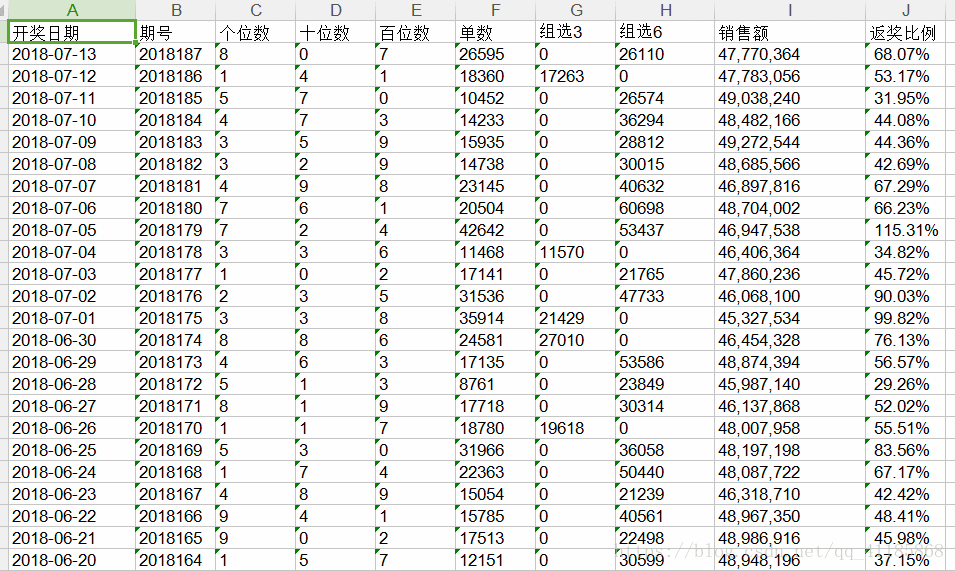
Crawler:基于BeautifulSoup库+requests库+伪装浏览器的方式实现爬取14年所有的福彩网页的福彩3D相关信息,并将其保存到Excel表格中
输出结果本来想做个科学预测,无奈,我看不懂爬到的数据……得到数据:3D(爬取的14年所有的福彩信息).rar好吧,等我看到了再用机器学习算法预测一下……完整代码,请点击获取http://1111111111111核心代码import requestsimport BeautifulSoupimpor...
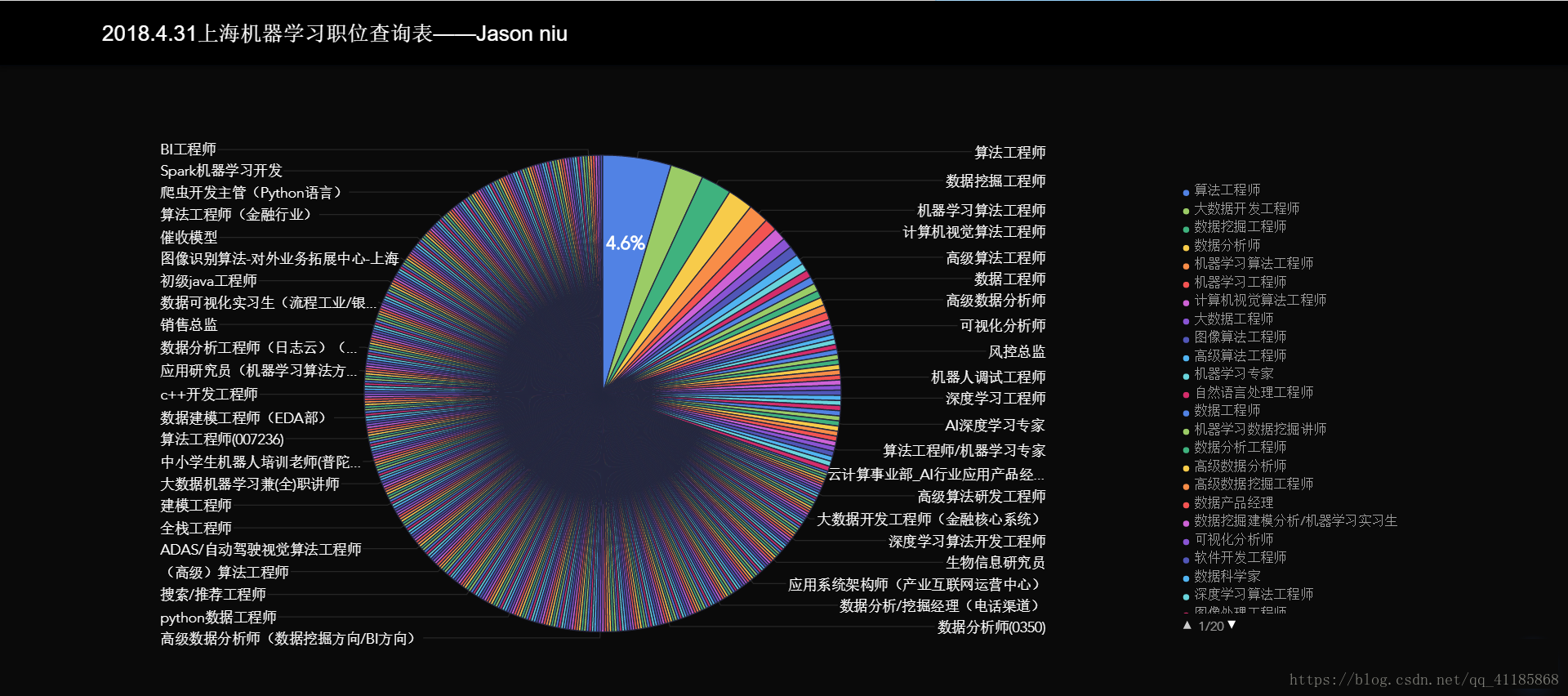
Crawler:基于urllib+requests库+伪装浏览器实现爬取国内知名招聘网站,上海地区与机器学习有关的招聘信息(2018.4.30之前)并保存在csv文件内
输出结果设计思路核心代码# -*- coding: utf-8 -*-#Py之Crawler:爬虫实现爬取国内知名招聘网站,上海地区与机器学习有关的招聘信息并保存在csv文件内import reimport csvimport requestsfrom tqdm import tqdmfrom ur...
大佬们,最近写的使用selenium 无头模式爬取数据的无法获取数据了,对方网站加了对无头浏览器的反爬措施,请问这个如何破?
大佬们,最近写的使用selenium 无头模式爬取数据的无法获取数据了,对方网站加了对无头浏览器的反爬措施,请问这个如何破?
用python2和python3伪装浏览器爬取网页
python网页抓取功能非常强大,使用urllib或者urllib2可以很轻松的抓取网页内容。但是很多时候我们要注意,可能很多网站都设置了防采集功能,不是那么轻松就能抓取到想要的内容。 今天我来分享下载python2和python3中都是如何来模拟浏览器来跳过屏蔽进行抓取的。 最基础的抓取: #! ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。



