gRPC源码分析(四):剖析Proto序列化
在前面的分析中,我们已经知道了使用proto序列化的代码在encoding目录中,路径中只有三个文件,其中2个还是测试文件,看起来这次的工作量并不大。 首先,针对读源码是先看源代码还是测试代码,因人而异。个人建议在对源码毫无头绪时,先从测试入手,了解大致功能;如果有一定基...
zookeeper源码分析--序列化篇
其实很多时候我们都在使用zkclient这款jar包对zk进行相关的操作,但是在zkclient里面到底发生了什么,我们却并不是很清楚。对zk的了解出了简单的节点创建,删除,监听以外,我们还可以加深对它的思想理解。下边我们来深入探讨一下zk的内部机制:其实我们清楚一点,zk是采用了java语言进行编...
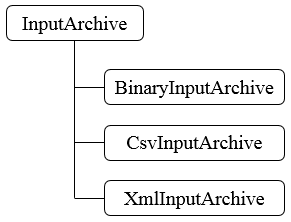
【Zookeeper】源码分析之序列化
【Zookeeper】源码分析之序列化
【Android Protobuf 序列化】Protobuf 使用 ( Protobuf 源码分析 | 创建 Protobuf 对象 )
文章目录一、Protobuf 源码分析二、创建 Protobuf 对象三、完整代码示例四、参考资料一、Protobuf 源码分析Protobuf 源文件如下 : addressbook.proto : // 指定 Protocol Buffers 语法版本 syntax = "proto2"; pa...
源码分析Dubbo序列化-源码分析kryo序列化实现原理
云栖号资讯:【点击查看更多行业资讯】在这里您可以找到不同行业的第一手的上云资讯,还在等什么,快来! 本文主要梳理 Kryo 序列化基本实现。重点剖析 Kryo # writeClassAndObject、Kryo # readClassAndObject 方法。 1、源码分析Kryo#writeCl...
MySQL · 源码分析 · Tokudb序列化和反序列化过程
序列化和写盘 Tokudb数据节点写盘主要是由后台线程异步完成的: checkpoint线程:把cachetable(innodb术语buffer pool)中所有脏页写回 evictor线程:释放内存,如果victim节点是dirty的,需要先将数据写回。 数据在磁盘上是序列化过的,序列化的过程就...
Hadoop2源码分析-序列化篇
1.概述 上一篇我们了解了MapReduce的相关流程,包含MapReduce V2的重构思路,新的设计架构,与MapReduce V1的区别等内容,今天我们在来学习下在Hadoop V2中的序列化的相关内容,其目录如下所示: 序列化的由来 Hadoop序列化依赖图详解 Writable常用实现...
hessian序列化源码分析
背景 最近在处理一个hessian的反序列化问题时,因为服务端使用了pojo bean中多了一个enum属性,导致客户端在反序列化时疯狂的在打印日志。警告说找不到对应的enum class,因为项目中本身是设置了log4j的根输出为一个文件。 &nb...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。