[帮助文档] 如何使用PythonClient编程方式访问TrinoOnACK服务
本文为您介绍如何使用Python Client编程的方式访问Trino On ACK服务并执行查询操作。
[帮助文档] 如何使用JDBC编程的方式访问TrinoOnACK服务并执行查询操作
本文为您介绍如何使用JDBC编程的方式访问Trino On ACK服务并执行查询操作。

[帮助文档] Hive作业异常的排查方法和解决方法
本文介绍Hive作业异常的排查方法和解决方法。
[帮助文档] 如何使用Arm节点运行Spark作业
EMR on ACK默认部署在X86架构的节点上,您也可以通过配置,将Spark作业运行在Arm类型的弹性容器实例(ECI)上。本文为您介绍如何使用Arm节点运行Spark作业。
[帮助文档] Spark作业异常的排查方法和解决方案
本文介绍Spark作业异常的排查方法和解决方案。
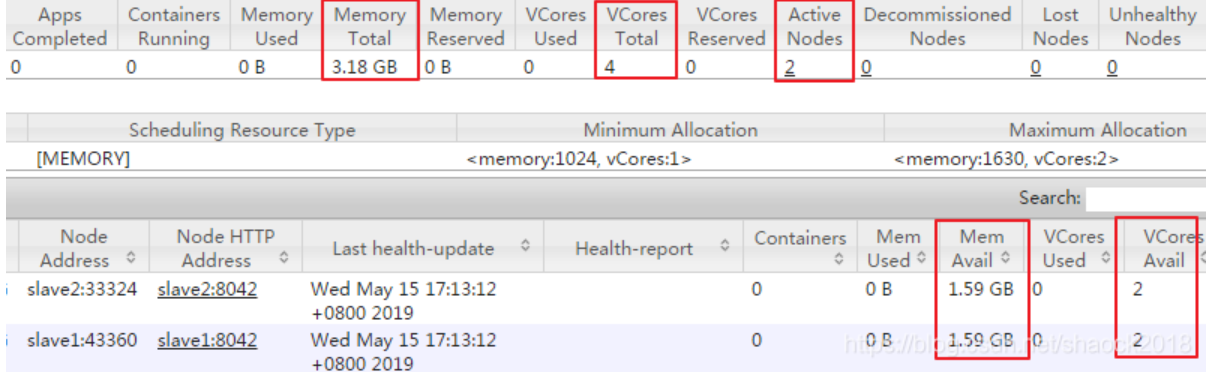
MapReduce作业在YARN的内存分配设置
0x00 教程内容内存分配设置校验结果0x01 内存分配设置1. 目前YARN配置情况a. 首先启动HDFS与YARNstart-dfs.shstart-yarn.shb. 打开master的8088端口可以看到我们之前的配置,请参考:YARN与MapReduce的配置与使用YARN总管理内存:3....
E-MapReduce作业日期设置是什么?
在创建作业过程中,支持在作业参数中设置时间变量通配符。 变量通配符格式 E-MapReduce 所支持的变量通配符的格式为${dateexpr-1d} 或者${dateexpr-1h} 的格式。例如,假设当前时间为“20160427 12:08:01”: 如果在作业参数中写成 ${yyyyMMdd ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
mapreduce您可能感兴趣
- mapreduce计算
- mapreduce框架
- mapreduce hadoop
- mapreduce实战
- mapreduce实践
- mapreduce案例
- mapreduce编程
- mapreduce大数据
- mapreduce分布式计算
- mapreduce starrocks
- mapreduce集群
- mapreduce spark
- mapreduce数据
- mapreduce hdfs
- mapreduce运行
- mapreduce maxcompute
- mapreduce任务
- mapreduce程序
- mapreduce配置
- mapreduce yarn
- mapreduce oss
- mapreduce优化
- mapreduce wordcount
- mapreduce map