[帮助文档] 分布式可视化MapReduce编程模型
可视化MapReduce模型在MapReduce模型的基础上,新增了可视化可运维的能力。您无需修改后端代码,只需在SchedulerX控制台将分布式模型改为可视化MapReduce,即可新增一个子任务列表页面,并且可以查看每个子任务的详情、结果和日志及支持每个子任务级别的重跑。
[帮助文档] 分布式可视化MapReduce编程模型
可视化MapReduce模型在MapReduce模型的基础上,新增了可视化可运维的能力。您无需修改后端代码,只需在SchedulerX控制台将分布式模型改为可视化MapReduce,即可新增一个子任务列表页面,并且可以查看每个子任务的详情、结果和日志,同时支持每个子任务级别的重跑。

[帮助文档] 分布式可视化MapReduce编程模型
可视化MapReduce模型在MapReduce模型的基础上,新增了可视化可运维的能力。您无需修改后端代码,只需在SchedulerX控制台将分布式模型改为可视化MapReduce,即可新增一个子任务列表页面,并且可以查看每个子任务的详情、结果和日志及支持每个子任务级别的重跑。
Python实现一个最简单的MapReduce编程模型WordCount
MapReduce编程模型:Map:映射过程Reduce:合并过程import operator from functools import reduce # 需要处理的数据 lst = [ "Tom", "Jack", "Mimi", "Jiji",...
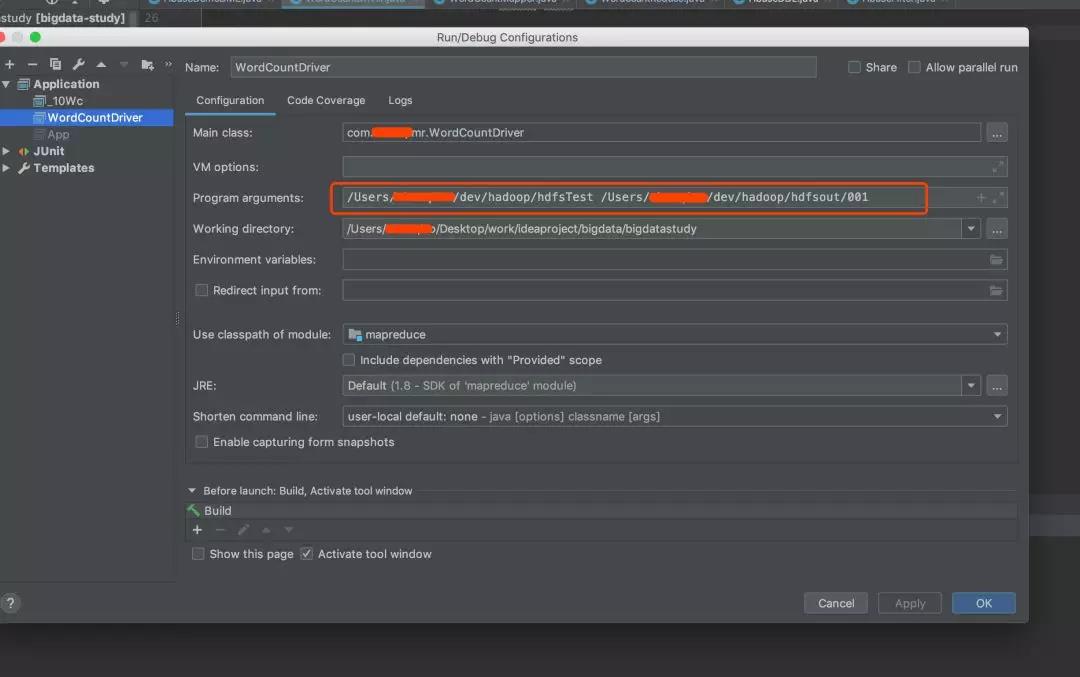
MapReduce 编程模型 & WordCount 示例(下)
接下来是 reduce task 逻辑: /** * KEYIN VALUEIN 对于map 阶段输出的KEYOUT VALUEOUT * <p> * KEYOUT :是自定义 reduce 逻辑处理结果的key * VALUEOUT : 是自定义reduce 逻辑处理结果的 value...
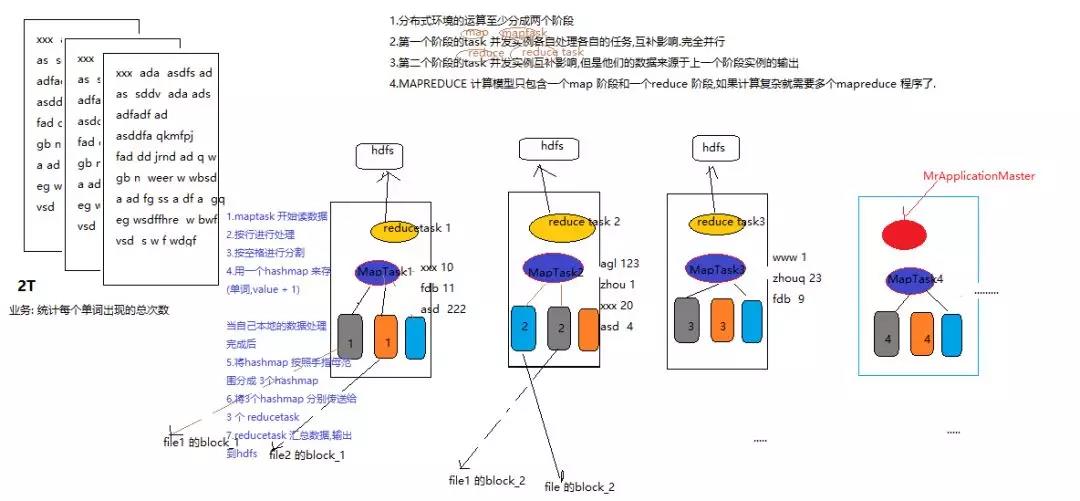
MapReduce 编程模型 & WordCount 示例(上)
学习大数据接触到的第一个编程思想 MapReduce。前言之前在学习大数据的时候,很多东西很零散的做了一些笔记,但是都没有好好去整理它们,这篇文章也是对之前的笔记的整理,或者叫输出吧。一来是加深自己的理解,二来是希望这些东西能帮助想要学习大数据或者说正在学习大数据的朋友。如果你看到里面的东西,让你知...
Hadoop MapReduce编程 API入门系列之wordcount版本4(八)
是将map、combiner、shuffle、reduce等分开放一个.java里。则需要实现Tool。 代码 1 package zhouls.bigdata.myMapR...
Hadoop MapReduce编程 API入门系列之wordcount版本1(五)
这个很简单哈,编程的版本很多种。 代码版本1 1 package zhouls.bigdata.myMapReduce.wordcount5; 2 3 import java...
Hadoop MapReduce编程 API入门系列之wordcount版本2(六)
代码 1 package zhouls.bigdata.myMapReduce.wordcount4; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.IntWritable; ...
Hadoop MapReduce编程 API入门系列之wordcount版本3(七)
代码 1 package zhouls.bigdata.myMapReduc...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
mapreduce您可能感兴趣
- mapreduce实战
- mapreduce实践
- mapreduce案例
- mapreduce hadoop
- mapreduce大数据
- mapreduce框架
- mapreduce分布式计算
- mapreduce starrocks
- mapreduce dataworks
- mapreduce集群
- mapreduce spark
- mapreduce数据
- mapreduce作业
- mapreduce hdfs
- mapreduce运行
- mapreduce maxcompute
- mapreduce任务
- mapreduce程序
- mapreduce配置
- mapreduce yarn
- mapreduce oss
- mapreduce优化
- mapreduce wordcount
- mapreduce map