[帮助文档] 如何创建Spark类型任务
SPARK任务类型用于执行Spark应用。本文为您介绍创建SPARK类型任务时涉及的参数。
[帮助文档] Paimon与Spark集成
E-MapReduce支持通过Spark SQL对Paimon进行读写操作。本文通过示例为您介绍如何通过Spark SQL对Paimon进行读写操作。

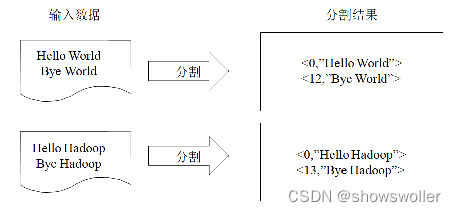
【大数据技术Hadoop+Spark】MapReduce之单词计数和倒排索引实战(附源码和数据集 超详细)
源码和数据集请点赞关注收藏后评论区留言私信~~~一、统计单词出现次数单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版“Hello World。其主要功能是统计一系列文本文件中每个单词出现的次数程序解析首先MapReduce将文件拆分成splits,由于测试用...
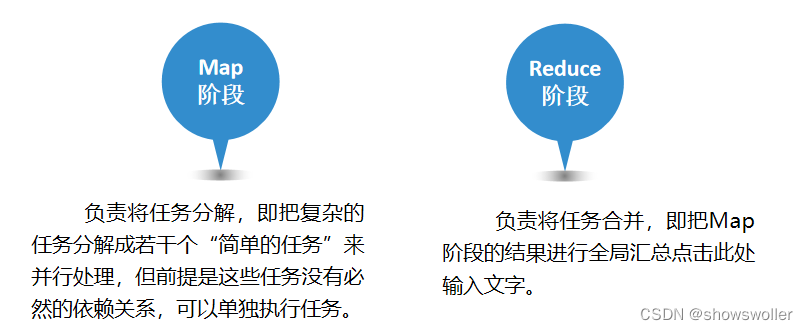
【大数据技术Hadoop+Spark】MapReduce概要、思想、编程模型组件、工作原理详解(超详细)
MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。一、MapReduce核心思想MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方...
[帮助文档] 如何使用Arm节点运行Spark作业
EMR on ACK默认部署在X86架构的节点上,您也可以通过配置,将Spark作业运行在Arm类型的弹性容器实例(ECI)上。本文为您介绍如何使用Arm节点运行Spark作业。
T-thinker | 继MapReduce, Apache Spark之后的下一代大数据并行编程框架
[欢迎随时跳过文字看最后的讲座视频直接了解 T-thinker]。什么?是不是又是一个关于设计大同小异的并行编程框架的炒作?是不是又是把各种简单烂大街问题(join, connected components, single-source shortest paths, PageRanks)统一一下...
[帮助文档] 如何在Spark3服务中开启Native引擎,有哪些限制
本文为您介绍Spark Native引擎在使用过程中的限制,以及如何在Spark3服务中开启Native引擎。
[帮助文档] Spark如何读取Hologres表数据
本文为您介绍Spark如何读取Hologres表数据。
HADOOP MapReduce 处理 Spark 抽取的 Hive 数据【解决方案一】
开端:今天咱先说问题,经过几天测试题的练习,我们有从某题库中找到了新题型,并且成功把我们干趴下,昨天今天就干了一件事,站起来。沙问题?java mapeduce 清洗 hive 中的数据 ,清晰之后将driver代码 进行截图提交。坑号1: spark之前抽取的数据是.parquet格.....
Storm&Spark中MapReduce框架包括什么呢?
Storm&Spark中MapReduce框架包括什么呢?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark更多mapreduce相关
apache spark您可能感兴趣
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark单机
- apache spark环境搭建
- apache spark案例
- apache spark测试
- apache spark streaming
- apache spark分布式
- apache spark SQL
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark Hadoop
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作