深度探索:使用Apache Kafka构建高效Java消息队列处理系统
Apache Kafka作为一款分布式的、高吞吐量的消息发布订阅系统,已在众多大型互联网公司和企业级应用中得到了广泛应用。本文将深入剖析如何在Java环境下使用Apache Kafka进行消息队列处理,包括其核心概念、应用场景、以及如何实现高效的消息生产和消费。 一、Apache Kafka核心概念...

使用Apache Hudi和Debezium构建健壮的CDC管道
一篇在Bangalore Hadoop Meetup上分享的使用Apache Hudi和Debezium构建CDC管道,分享者是Apache Hudi社区活跃贡献者Pratyaksh。 ...


使用Apache Hudi构建大规模、事务性数据湖
一个近期由Hudi PMC & Uber Senior Engineering Manager Nishith Agarwal分享的Talk 关于Nishith Agarwal更详细的介绍,主要从事数据方面的工作,包...
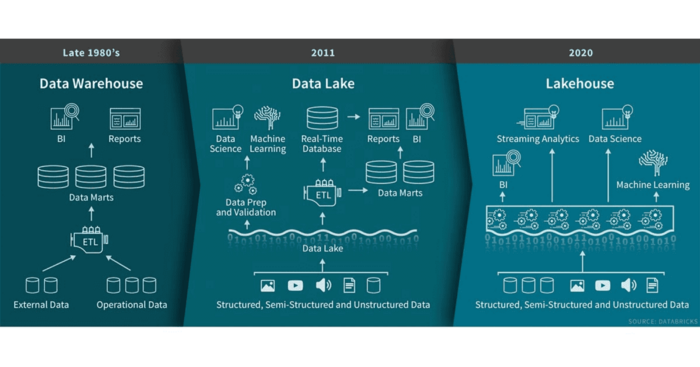
使用Apache Hudi构建下一代Lakehouse
1. 概括 本文介绍了一种称为Data Lakehouse的现代数据架构范例。Data Lakehouse相比于传统的数据湖具有很多优势,本文说明了如何通过现代化数据平台并使用Lakehouse架构来应对客户端所面临的可扩展性、数据质量和延迟方面的挑战。本文介绍了使用Apache Hudi实现Dat...
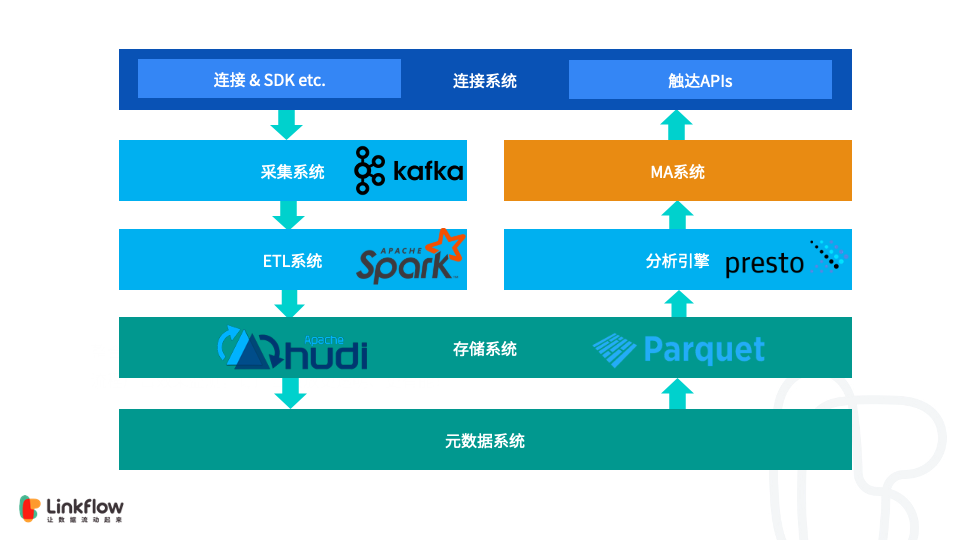
Apache Hudi在Linkflow构建实时数据湖的生产实践
1. 背景 Linkflow 作为客户数据平台(CDP),为企业提供从客户数据采集、分析到执行的运营闭环。每天都会通过一方数据采集端点(SDK)和三方数据源,如微信,微博等,收集大量的数据。这些数据都会经过清洗,计算,整合后写入存储。使用者可以通过灵活的报表或标签对持久化的数据进行分析和计算,结果又...

使用Apache Pulsar + Hudi 构建Lakehouse方案了解下?
由StreamNative Founder & CEO 郭斯杰 执笔的Apache Pulsar作为Lakehouse的提案,阐述如何利用Apache Hudi解决Pulsar作为Lakehouse的痛点问题,强烈推荐! 1. 动机 Lakehouse最早由Databricks公司提出,其可...

字节跳动基于Apache Hudi构建EB级数据湖实践
接下来将分为场景需求、设计选型、功能支持、性能调优、未来展望五部分介绍Hudi在字节跳动推荐系统中的实践。 ...

字节跳动基于Apache Hudi构建实时数据湖平台实践
一篇关于字节跳动基于 Apache Hudi 的实时数据湖平台的分享。 ...
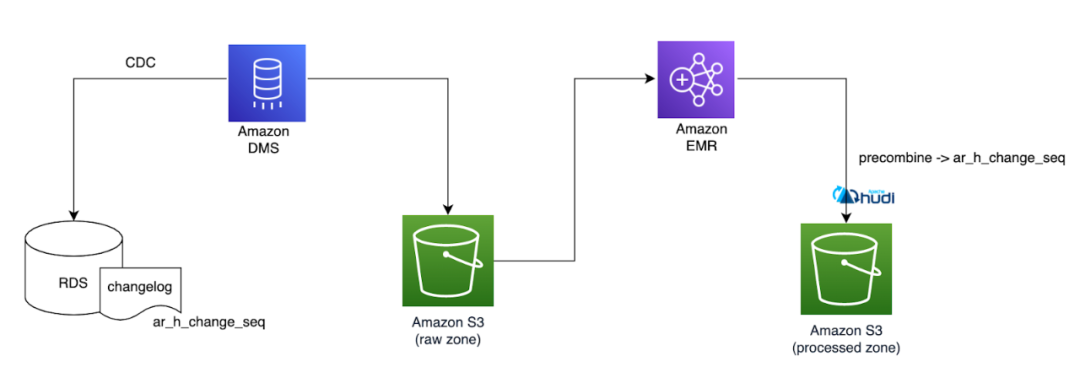
Halodoc使用Apache Hudi构建Lakehouse的关键经验
Halodoc 数据工程已经从传统的数据平台 1.0 发展到使用 LakeHouse 架构的现代数据平台 2.0 的改造。在我们之前的博客中,我们提到了我们如何在 Halodoc 实施 Lakehouse 架构来服务于大规模的分析工作负载。我们提到了平台 2.0 构建过程中的设计注意事项、最佳实践和...
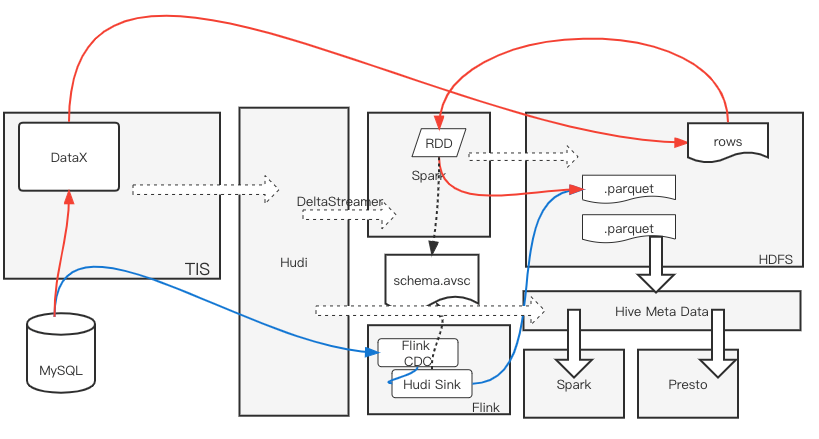
基于TIS构建Apache Hudi千表入湖方案
拥抱数据湖 随着大数据时代的到来,数据量动辄PB级,因此亟需一种低成本、高稳定性的实时数仓解决方案来支持海量数据的OLAP查询需求,Apache Hudi[1]应运而生。Hudi借助与存放在廉价的分布式文件系统之中列式存储文件,并将其元数据信息存放在Hive元数据库中与传统查询引擎Hive、Pres...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。





Apache更多构建相关
Apache您可能感兴趣
- Apache入门
- Apache tomcat
- Apache web
- Apache pdf
- Apache文本
- Apache mod_proxy
- Apache负载均衡
- Apache配置
- Apache svn
- Apache服务器
- Apache flink
- Apache rocketmq
- Apache安装
- Apache php
- Apache dubbo
- Apache linux
- Apache spark
- Apache开发
- Apache报错
- Apache服务
- Apache微服务
- Apache从入门到精通
- Apache hudi
- Apache doris
- Apache mysql
- Apache日志
- Apache kafka