如何获取浏览器版本信息
如何获取浏览器版本信息
使用Windows Server 2008服务器,安装IIS7.5,网站程序是ASP语言编写,如何设置页面报错时在浏览器上显示真实错误信息?
使用Windows Server 2008服务器,安装IIS7.5,网站程序是ASP语言编写,如何设置页面报错时在浏览器上显示真实错误信息?
使用IE浏览器访问网站出现如下页面,不显示详细错误信息,如下图:
使用IE浏览器访问网站出现如下页面,不显示详细错误信息,如下图:
使用IE浏览器访问网站时报错,不显示详细错误信息
使用IE浏览器访问网站出现如下页面,不显示详细错误信息,如下图:
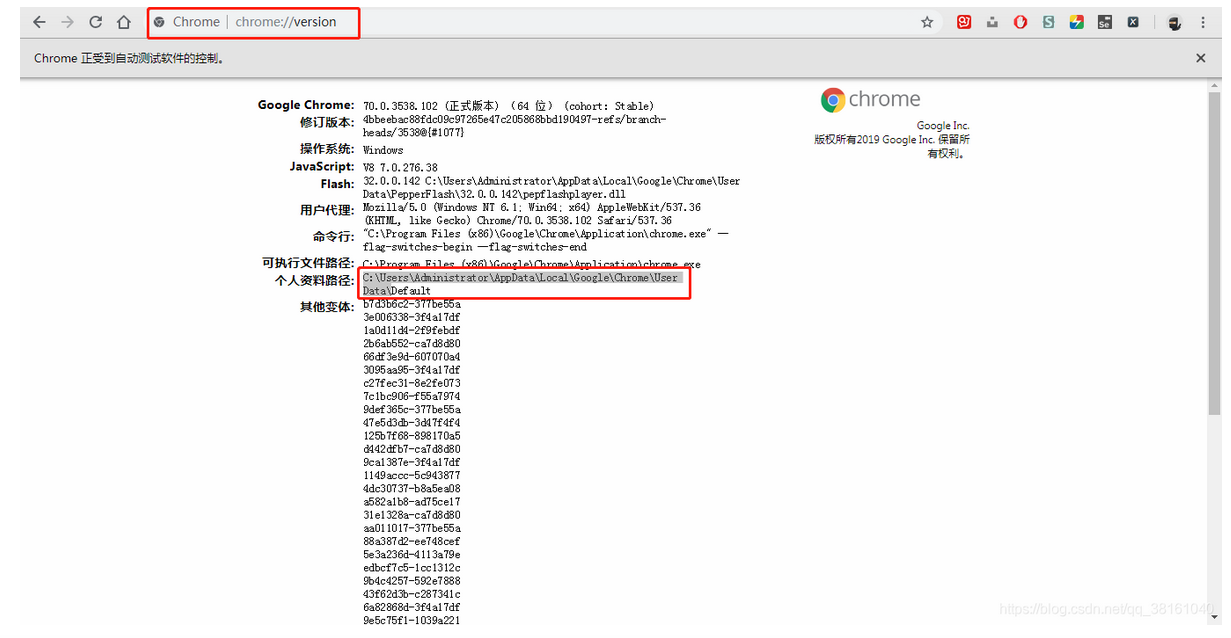
Python+selenium 自动化-启用带插件的chrome浏览器,调用浏览器带插件,浏览器加载配置信息。
正常的话我们启用的 chrome 浏览器是不带插件的,如果你能登陆 chrome 的话,你会发现登陆信息也没有,还有不管你怎样设置每次新打开的 chrome 都是默认设置的。我们正常启动的浏览器每次都要加载配置文件的,一般的配置文件就是在 user data 里,插件就是属于配置文件的一部分。 我...

微信内置浏览器调用微信 OAuth 授权获取用户基本信息
首先,我建议各位打印一份微信官方的「网页授权获取用户基本信息」文档,但是不要阅读它。烧掉它,这有重要的象征意义。一个位于微信内置浏览器内的网页要获取用户基本信息,首先要获取任意一个用户对其应用的所谓「openid」(其实应该叫「private id」,因为同一个用户在每个应用里的这个 ID 都不一样...
Chrome浏览器开发者工具中的Network选项卡中列举的信息是表示当前系统网络的好坏吗?
Chrome浏览器开发者工具中的Network选项卡中列举的信息是表示当前系统网络的好坏吗?
Crawler:基于requests库+urllib3库+伪装浏览器实现爬取抖音账号的信息数据
输出结果更新……代码设计from contextlib import closingimport requests, json, time, re, os, sys, timeimport urllib3urllib3.disable_warnings(urllib3.exceptions.Inse...
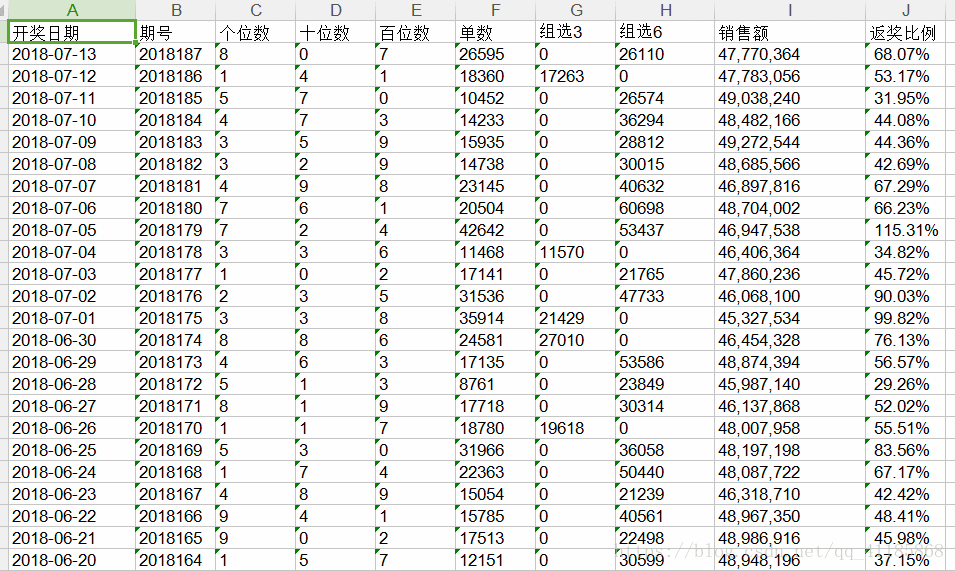
Crawler:基于BeautifulSoup库+requests库+伪装浏览器的方式实现爬取14年所有的福彩网页的福彩3D相关信息,并将其保存到Excel表格中
输出结果本来想做个科学预测,无奈,我看不懂爬到的数据……得到数据:3D(爬取的14年所有的福彩信息).rar好吧,等我看到了再用机器学习算法预测一下……完整代码,请点击获取http://1111111111111核心代码import requestsimport BeautifulSoupimpor...
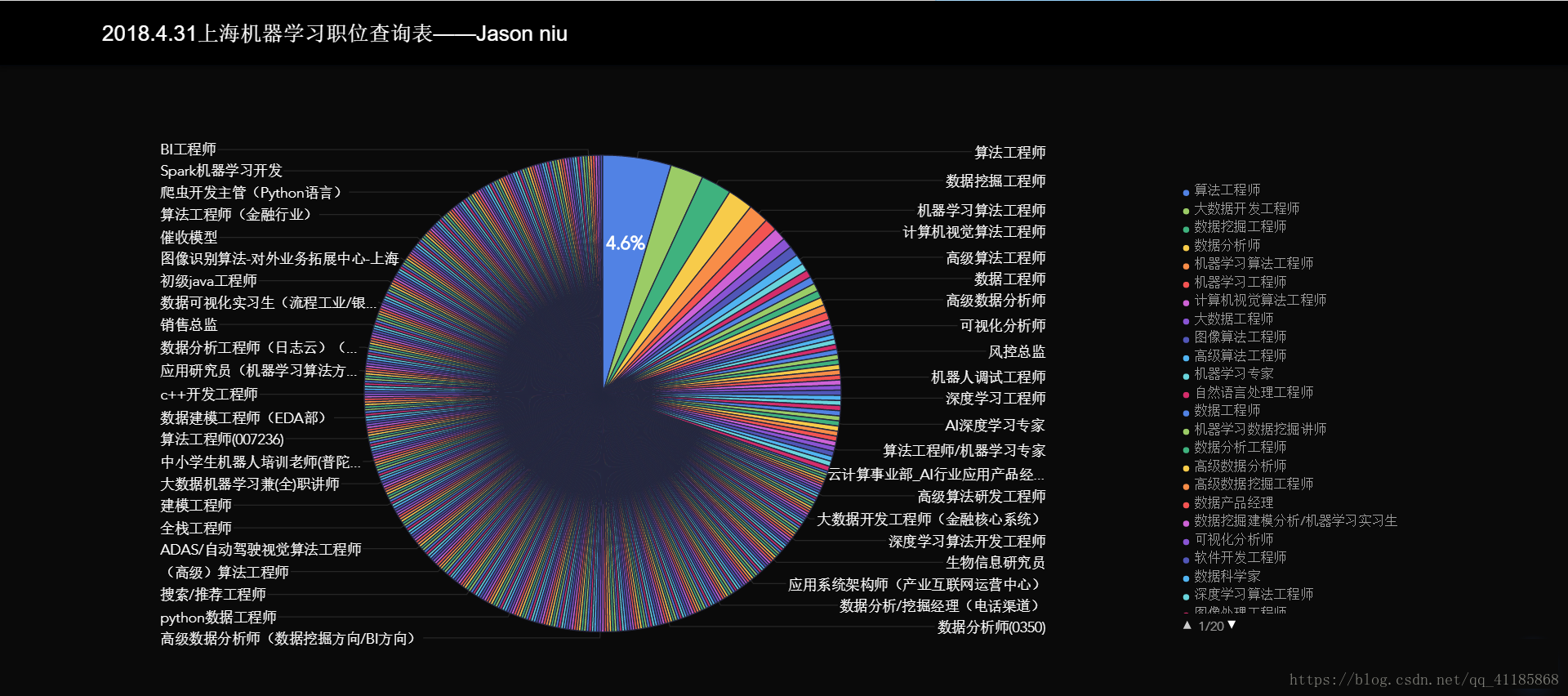
Crawler:基于urllib+requests库+伪装浏览器实现爬取国内知名招聘网站,上海地区与机器学习有关的招聘信息(2018.4.30之前)并保存在csv文件内
输出结果设计思路核心代码# -*- coding: utf-8 -*-#Py之Crawler:爬虫实现爬取国内知名招聘网站,上海地区与机器学习有关的招聘信息并保存在csv文件内import reimport csvimport requestsfrom tqdm import tqdmfrom ur...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。



