云原生多模数据库Lindorm
云原生多模数据库Lindorm提供各规模、多模型的云原生数据库服务。可兼容HBase/Cassandra、OpenTSDB、Solr、SQL、HDFS等多种开源标准接口。支持海量数据的低成本存储处理和弹性按需付费,是互联网、IoT、车联网、广告、社交等场景首选数据库,也是为阿里核心业务提供支撑的数据库之一。
千万级高并发吞吐、毫秒级访问延迟。共享存储,使用低成本存储介质,支持智能冷热分离和自适应压缩.存储计算分离架构,支持计算资源、存储资源独立弹性...云数据库 HBase 版.搭配使用产品.电商高并发场景.提供稳定、高性能、安全可靠的数据库服务.查看Lindorm使用文档.查看产品开发指南.查看快速入门指南.进入技术交流社区.
来自:
云产品
云原生大数据计算服务MaxCompute
阿里云云原生大数据计算服务MaxCompute是面向分析的企业级云数仓,作为一体化大数据智能计算平台ODPS的大规模批量计算引擎,MaxCompute以 Serverless 架构提供快速、全托管的在线数据仓库服务,使您经济高效的分析处理海量数据,进行敏捷的业务洞察。
为云上企业提供从基础设施、数据中心、网络、供电到平台安全能力,再到用户权限管理、隐私保护等三级超20项安全功能,兼具开源大数据与托管数据库的安全能力.汇集 MaxCompute 电子书、月刊、新品发布会与系列公开课>.标准计算资源.MaxFrame 邀测.MaxFrame 邀测.MaxFrame 邀测.更多阿里云大数据.MaxCompute 资源抵扣包套餐...
来自:
云产品
自建Hadoop迁移MaxCompute
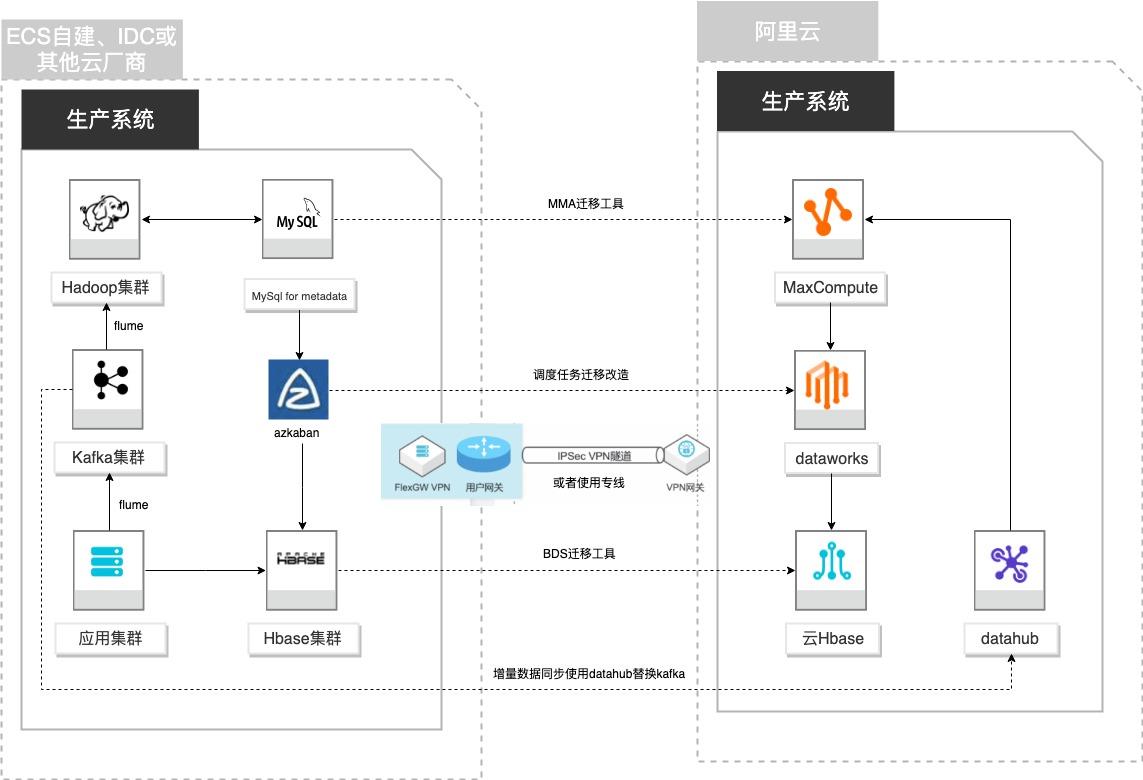
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
启动 Hbase历史数据迁移 步骤1 进入历史数据迁移界面 步骤2 创建 Hbase迁移任务 文档版本:20210723 36 自建Hadoop迁移MaxCompute Hbase表数据迁移到云数据库 Hbase版 步骤3 查看迁移进程 文档版本:20210723 37 自建Hadoop迁移MaxCompute Hbase表数据迁移到云数据库 Hbase版 4.4.启动 Hbase实时数据同步 如果如要进行一段...
EMR HBase on OSS存算分离集群快速恢复
OSS-HDFS服务(JindoFS服务)是一款云原生数据湖存储产品。基于统一的元数据管理能力,在完全兼容HDFS文件系统接口的同时,提供充分的POSIX能力支持,能更好地满足大数据和AI等领域的数据湖计算场景。
EMR HBase on OSS存算分离集群快速恢复 最佳实践 部署架构 HBase on OSS架构优势 场景描述 简化了数据迁移和恢复 OSS-HDFS服务(JindoFS服务)是一款云原生 HBase 的数据文件和表的元数据持久存储在集群外部的 数据湖存储产品。基于统一的元数据管理能力,OSS上,HBase数据迁移和恢复时无需再使用快照等复杂 在完全兼容 ...
中小企业自建Hadoop集群上云解决方案
中小企业自建 Hadoop 集群上云解决方案,助力自建 Hadoop 用户快速构建云上半托管开源大数据平台,在保持原组件使用习惯延续的同时,充分利用云上服务特点,更加便捷地迭代企业大数据平台架构,聚焦业务价值开发。
基于阿里云 E-MapReduce、OSS、边缘网络加速等产品及服务,帮助自建 Hadoop 用户快速构建云上半托管开源大数据平台,在保持原自建 Hadoop 组件使用习惯延续的同时,充分利用云上服务特点,更加便捷地迭代企业大数据平台架构,聚焦业务价值开发.中小企业自建Hadoop集群上云解决方案.提供高性能、稳定版本 Hadoop、Spark、...
来自:
解决方案
自建Hadoop迁移到阿里云EMR
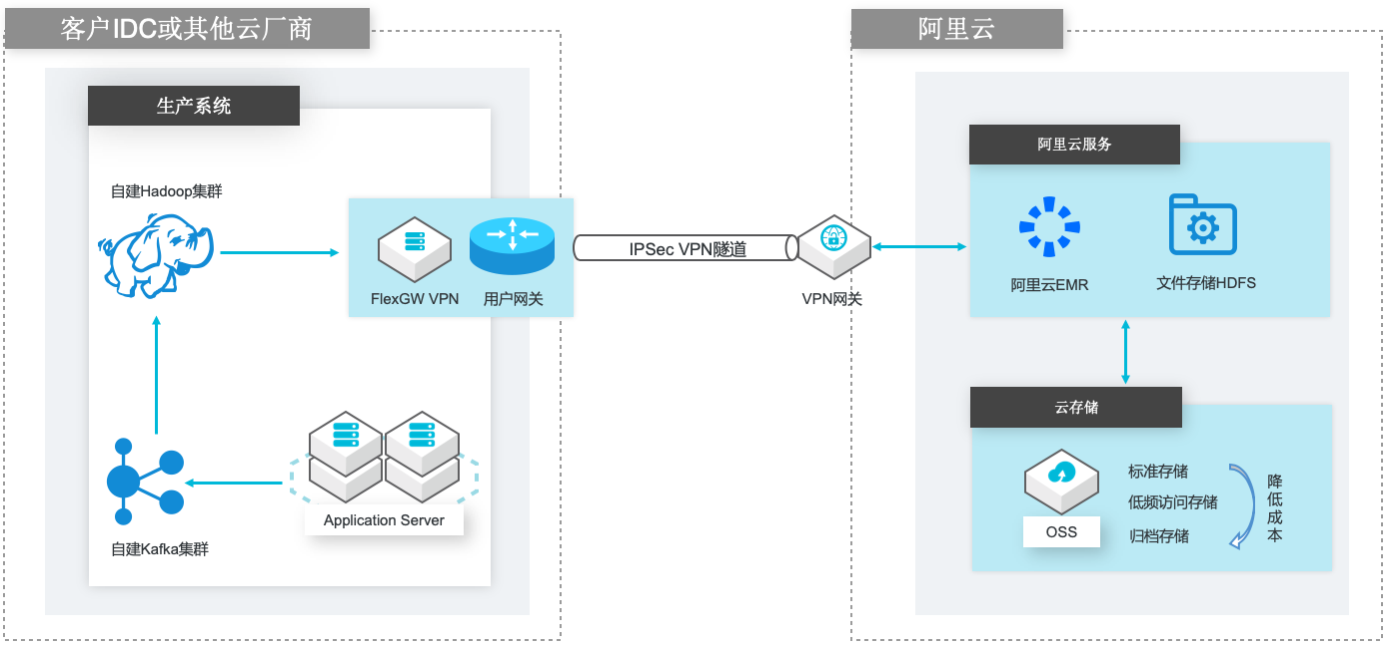
场景描述 场景1:自建Hadoop集群数据(HDFS)迁移到 阿里云EMR集群的HDFS文件系统; 场景2:自建Hadoop集群数据(HDFS)迁移到 计算存储分离架构的阿里云EMR集群,以OSS 和JindoFS作为EMR集群的后端存储。 解决的问题 客户自建Hadoop迁移到阿里云EMR集群的 技术方案; 基于IPSecVPN隧道构建安全和低成本数据 传输链路 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
自建 Hadoop数据迁移到阿里云 EMR 场景描述 解决的问题 场景1:自建 Hadoop集群数据(HDFS)迁移到阿 客户自建 Hadoop迁移到阿里云 EMR集群的技 里云EMR集群的 HDFS文件系统;术方案;场景2:自建 Hadoop集群数据(HDFS)迁移到计 基于 IPSec VPN隧道构建安全和低成本数据 算存储分离架构的阿里云 EMR集群,以 OSS 和 传输...
自建Hive数仓迁移到阿里云EMR
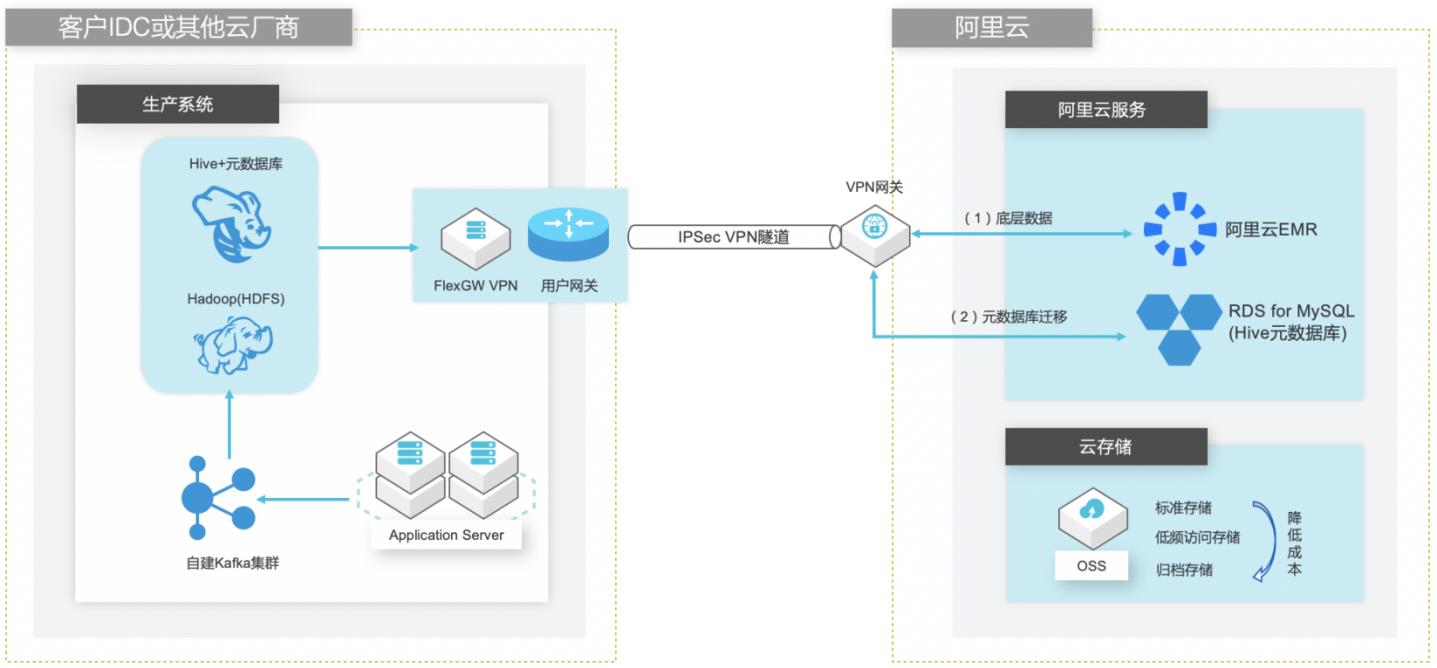
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
可靠性 使用阿里云数据库 RDS保存 Hive的元数据信息,可以提升数据可靠性和服务可 用性,免除客户运维自建 MySQL数据库的工作。文档版本:20210721 2 自建Hive数据仓库跨版本迁移到阿里云 EMR 前置条件 前置条件 在进行本文操作之前,您需要完成以下准备工作:注册阿里云账号,并完成实名认证。您可以登录阿里云控制台,并...
金融专属大数据workshop

实践目标 学习搭建一个实时数据仓库,掌握数据采集、存储、计算、输出、展示等整个业务流程。 整个实时数据仓库系统全部基于阿里云产品进行架构搭建,用户可以掌握并学会运用各个服务组件及各个组件之间如何联动。 理解阿里云原生实时离线一体数仓解决方案架构以及掌握交付落地的实践使用方法。 前置知识要求 熟练掌握SQL语法 对大数据体系系统知识有一定的了解
详 见:https://www.aliyun.com/product/bigdata/hologram 云数据库RDSMySQL版:云数据库RDSMySQL版是全球最受欢迎的开源数据 文档版本:20210803(发布日期)III阿里云最佳实践大数据WorkShop 产品介绍 库之一,作为开源软件组合LAMP(Linux+Apache+MySQL+Perl/PHP/Python)中 的 重 要 一 环,广 泛 应 用 于 各 类 应...
来自:
最佳实践
相关产品:块存储,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,弹性公网IP,数据传输,DataWorks,大数据计算服务 MaxCompute,DataV数据可视化,实时计算,数据总线,Quick BI,Hologres
大数据近实时数据投递MaxCompute
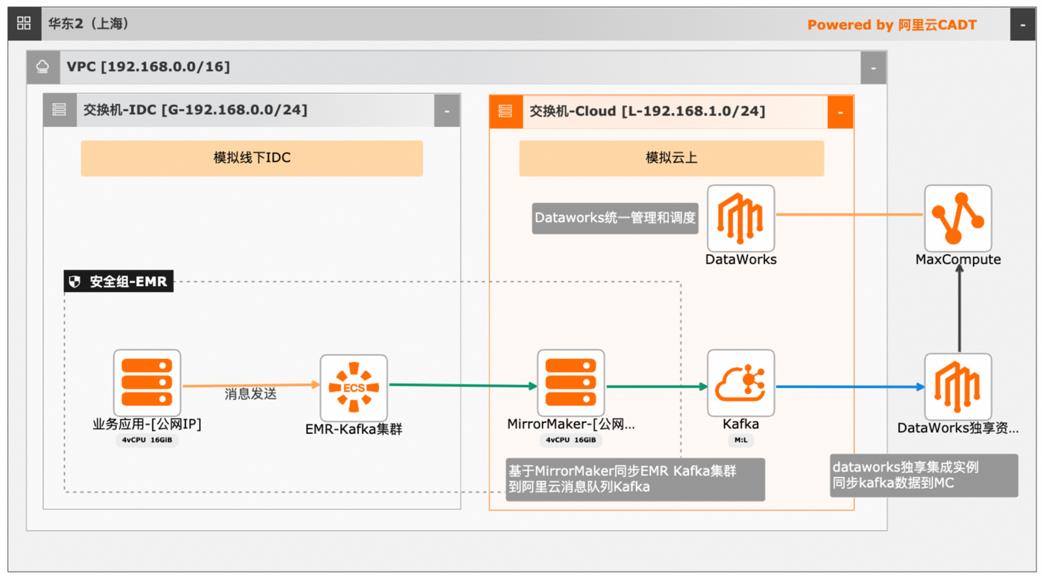
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
全数据链路延时.55 文档版本:20240419 V 大数据近实时数据投递 MaxCompute 最佳实践概述 最佳实践概述 场景描述 本最佳实践构建以下场景:使用阿里云 EMR服务部署 Kafka集群模拟线下 IDC的自建 Kafka集群 构建消息队列 Kafka、MaxCompute等服务实例,构建云上数仓。使用 MirrorMaker将 EMR Kafka集群消息同步至云消息队列 ...
CDH迁移升级CDP最佳实践
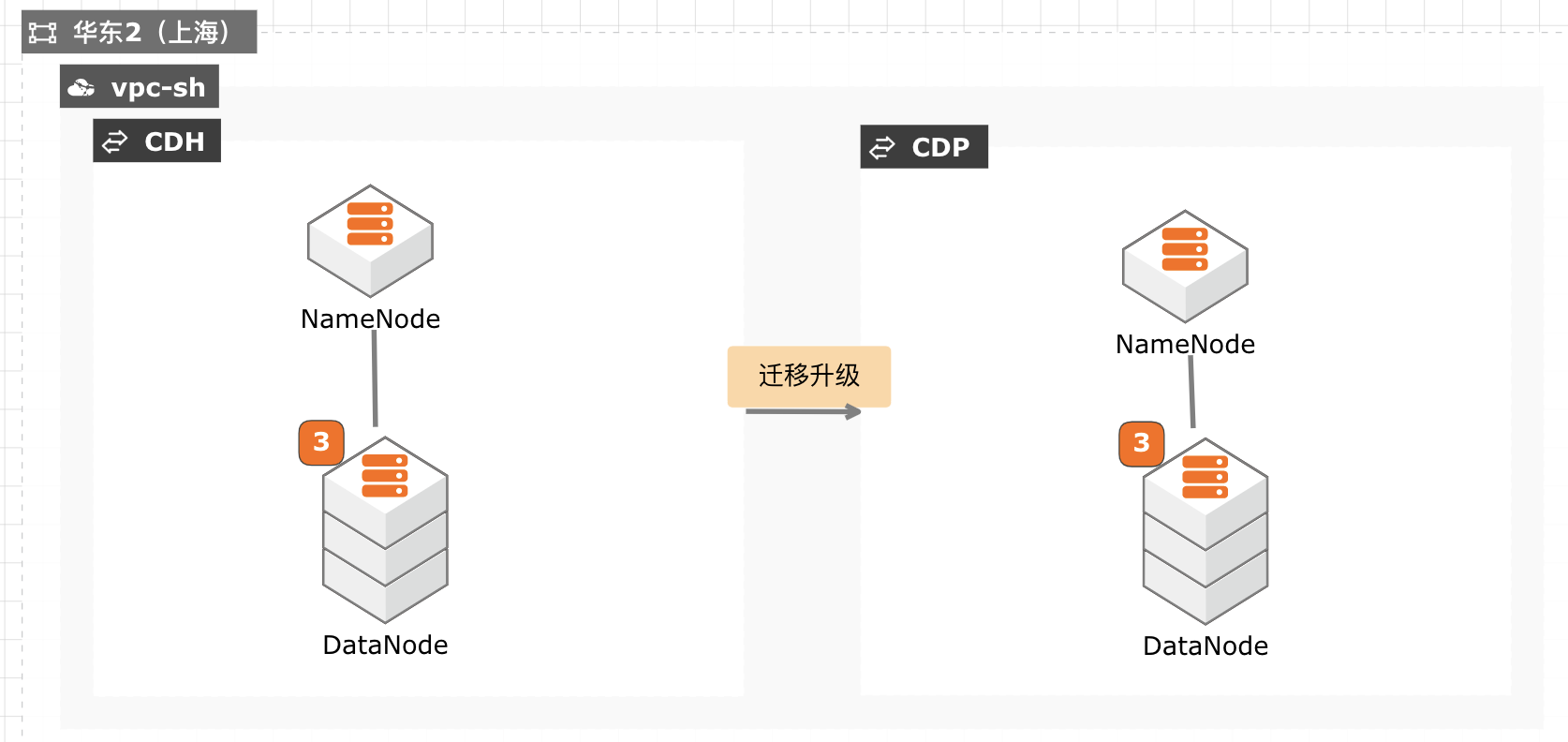
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
hdfs dfs-ls/hbase/.hbase-snapshot hdfs dfs-ls/hbase/.hbase-snapshot/snapshot_item 文档版本:20211029 80 CDH迁移升级 CDP最佳实践 数据迁移 查看 CDP集群上的 Hbase表,当前不存在任何表。hbase shell list 创建 Hbase表并查看。create 'hbase_item','cf1' list 为了防止其他操作影响'hbase_item表,先禁用表,再恢复...
云数据库产品总览(瑶池)
阿里云提供完善的数据库解决方案,多款数据库产品,满足99%的业务场景,荣获Gartner、信通院等国内外多项认证。轻松满足高可靠、高可用性、高性能等数据库需求;运维工作量大幅减少,让企业一站式享受数据上云及分布式架构的技术红利!
云数据库HBase增强版提供全文索引方案,通过BDS实现HBase与Solr之间的数据实时同步,使业务轻松应对高维度&随机组合查询需求;提供压缩存储优化特性和冷热分离功能,0应用改造实现冷热数据分离存储,降低不常用冷数据存储成本,提升常用热数据访问性能.专属集群MyBase以资源独享、自主运维、安全可控的新型模式,很大程度上...
来自:
云产品
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
云消息队列 Kafka 版支持连接自建 Filebeat 日志采集,经由 Kafka 流转到后方 ES 服务.Hbase、Spark 数据处理.云消息队列 Kafka 版数据导入 Hbase 等存储,实现低成本存储和计算分析.Flink 实时数仓.云消息队列 Kafka 版支持数据流转到 Flink,实现ETL处理、实时数据分析等业务.云消息队列 Kafka 版兼容标准规范,支持海量...
来自:
云产品
实时数仓Hologres
Hologres(原交互式分析)是一站式实时数据仓库引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与自助分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供离在线一体化全栈数仓解决方案。
以Hologres行存表替换HBase,Flink实时关联Hologres维表,实时生成用户标签,助力业务实时运营决策,实时用户触达和推荐.实时业务推荐.标准SQL语法,充分支持精细化运营复杂多维分析诉求,数据加工延迟从3小时加速到实时,多表关联join秒级返回,流量匹配效率提升300%.灵活多维分析.Flink+Hologres一套架构支持多种业务场景...
来自:
云产品
大数据workshop

大数据workshop
详见:https://www.aliyun.com/product/bigdata/hologram 文档版本:20210628(发布日期)III 阿里云最佳实践大数据 WorkShop 产品介绍 云数据库 RDS MySQL版:云数据库 RDS MySQL 版是全球最受欢迎的开源数 据库之一,作为开源软件组合 LAMP(Linux+Apache+MySQL+Perl/PHP/Python)中的重要一环,广泛应用于各类应用场景。...
来自:
最佳实践
相关产品:块存储,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,弹性公网IP,数据传输,DataWorks,大数据计算服务 MaxCompute,DataV数据可视化,实时计算,数据总线,Quick BI,Hologres
MaxCompute湖仓一体方案
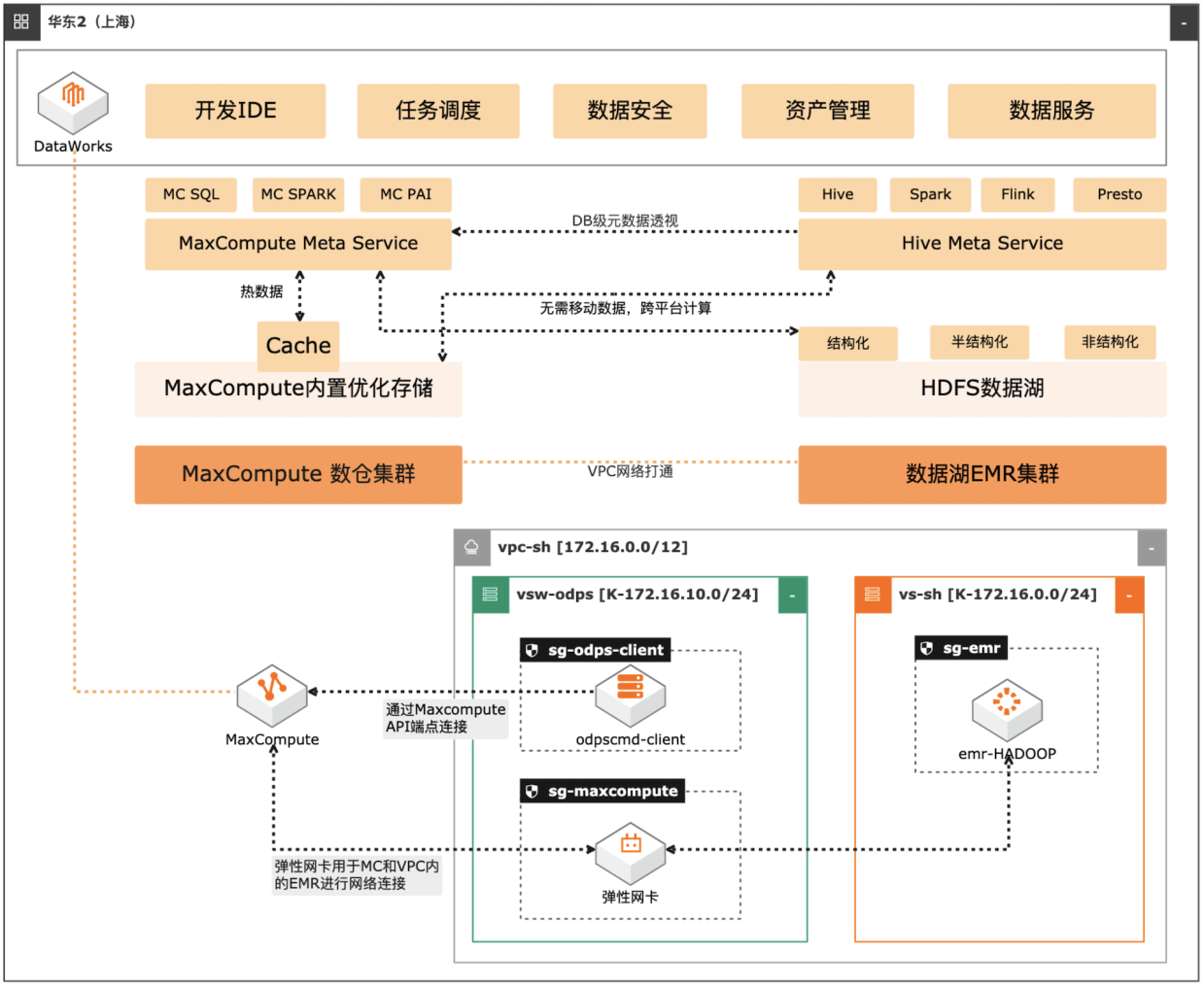
场景描述 自建数据湖与云数仓的融合解决方案,将 MaxCompute与自建的Hive集群做数据打 通,通过存储共享,元数据镜像等方式,解 决传统模式下的存储冗余,计算资源弹性能 力弱的痛点。可大幅度增强系统的资源弹 性,解决业务高峰期计算资源不足的问题。 方案优势 1.业务无侵入性:现有业务无需改造。 2.性能优化:MaxCompute在SQL上做 了大量优化与能力沉淀,可提高SQL 运行性能,降低计算成本。 3.灵活管理:元数据实时同步,无需额外 管理数据同步任务。 4.资源弹性:利用MaxCompute计算池 弹性进行海量数据计算。 解决问题 1.增强业务高峰期的资源弹性。 2.优化自建数据湖的数据治理能力。 3.减少跨平台数据处理的存储冗余。 产品列表 专有网络VPC 云服务器ECS 访问控制RAM 运维编排OOS MaxCompute(原ODPS) 云企业网CEN
EMR:阿里云 E-MapReduce(EMR)是构建在阿里云云服务器 ECS 上的开源 Hadoop、Spark、HBase、Hive、Flink 生态大数据 PaaS 产品。提供用户在云上 使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习等 场 景 下 的 大 数 据 解 决 方 案。更 多 信 息,请 参 见:...
云原生数据库
PolarDB是阿里云自研的云原生数据库,在存储计算分离架构下,利用了软硬件结合的优势,为用户提供秒级弹性、高性能、海量存储、安全可靠的数据库服务。100%兼容MySQL和PostgreSQL生态,支持分布式扩展,高度兼容Oracle语法。
云数据库HBase.云原生数据仓库ADB MySQL.数据传输DTS.推荐搭配产品.通用:大容量数据存储.海量存储,支持上百TB级别数据.PolarDB采用计算和存储分离架构,支持数据库服务器的CPU、内存能够快速扩容,最快可增加15个只读节点,支持并行查询、读写分离等功能,使查询耗时指数级下降,解决计算量较大的查询、多表连接查询、...
来自:
云产品
云原生数据库PolarDB MySQL版
PolarDB MySQL版是自研的云原生关系型数据库,100%兼容MySQL。多主多写、多活容灾、HTAP、交易和分析性能最高分别是开源数据库的6倍和400倍,TCO低于自建数据库50%。
云数据库HBase.云原生数据仓库ADB版.数据传输DTS.推荐搭配产品.通用:大容量数据存储.海量存储,支持上百TB级别数据.PolarDB采用计算和存储分离架构,支持数据库服务器的CPU、内存能够快速扩容,最快可增加15个只读节点,支持并行查询、读写分离等功能,使查询耗时指数级下降,解决计算量较大的查询、多表连接查询、日常...
来自:
云产品
E-MapReduce
阿里云E-MapReduce(简称EMR)是阿里云云原生数据湖的核心计算引擎,全面支持Hadoop、Spark、HBase、Hive、Flink等大数据组件,为客户提供企业级开源大数据平台服务。通过有效弹性伸缩和数据分层存储机制,相较于传统HDFS固定集群方式,可节省50%以上的费用,同时支持创建抢占式实例,相比按量付费的购买方式,可节省50%~80%的费用。
您可以将开源大数据服务部署在阿里云容器服务Kubernetes版(ACK)之上,利用ACK在服务部署和容器应用管理的优势,减少对底层集群资源的运维投入,以便于您可以更加专注大数据任务本身.E-MapReduce Serverless StarRocks 版是阿里云提供的 Serverless StarRocks 全托管服务,提供高性能、全场景、极速统一的数据分析体验,...
来自:
云产品
云数据库HBase
阿里云云数据库 HBase 版(ApsaraDB for HBase)是基于 Hadoop 且100%兼容HBase协议的高性能、可弹性伸缩、面向列的分布式数据库,轻松支持PB级大数据存储,满足千万级QPS高吞吐随机读写场景。
云数据库 HBase 版是面向大数据领域的一站式NoSQL服务,100%兼容开源HBase并深度扩展,支持海量数据下的实时存储、高并发吞吐、轻SQL分析、全文检索、时序时空查询等能力,是风控、推荐、广告、物联网、车联网、Feeds流、数据大屏等场景首选数据库,是为淘宝、支付宝、菜鸟等众多阿里核心业务提供关键支撑的数据库.Lindorm...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您