[帮助文档] 如何使用HiveJindoSDK处理OSS-HDFS服务中的数据
使用Hive搭建离线数仓时,随着数据量的不断增长,传统的基于HDFS存储的数仓可能无法以较低成本满足用户的需求。在这种情况下,您可以使用OSS-HDFS服务作为Hive数仓的底层存储,并通过JindoSDK获得更好的读写性能。
[帮助文档] AnalyticDB PostgreSQL读写HDFS、Hive或MySQL外部数据
若您需要通过AnalyticDB PostgreSQL版访问外部异构数据源(HDFS、Hive和JDBC)时,可以使用异构数据源访问功能将外部数据转换为AnalyticDB PostgreSQL版数据库优化后的格式进行查询和分析。

Sqoop【付诸实践 01】Sqoop1最新版 MySQL与HDFS\Hive\HBase 核心导入导出案例分享+多个WRAN及Exception问题处理(一篇即可学会在日常工作中使用Sqoop)
1.环境说明 # 不必要信息不再贴出 # JDK [root@tcloud ~]# java -version java version "1.8.0_251" # MySQL [root@tcloud ~]# mysql -V mysql Ver 14.14 Distrib 5.7.28 # Ha...
[帮助文档] 使用JindoTableMoveTo命令将Hive表和分区数据迁移至OSS-HDFS服务
本文介绍如何使用JindoTable MoveTo命令将Hive表和分区数据迁移至OSS-HDFS服务。
[帮助文档] Hive如何以EMR集群的方式处理OSS-HDFS服务中的数据
本文介绍Hive如何以EMR集群的方式处理OSS-HDFS服务中的数据。
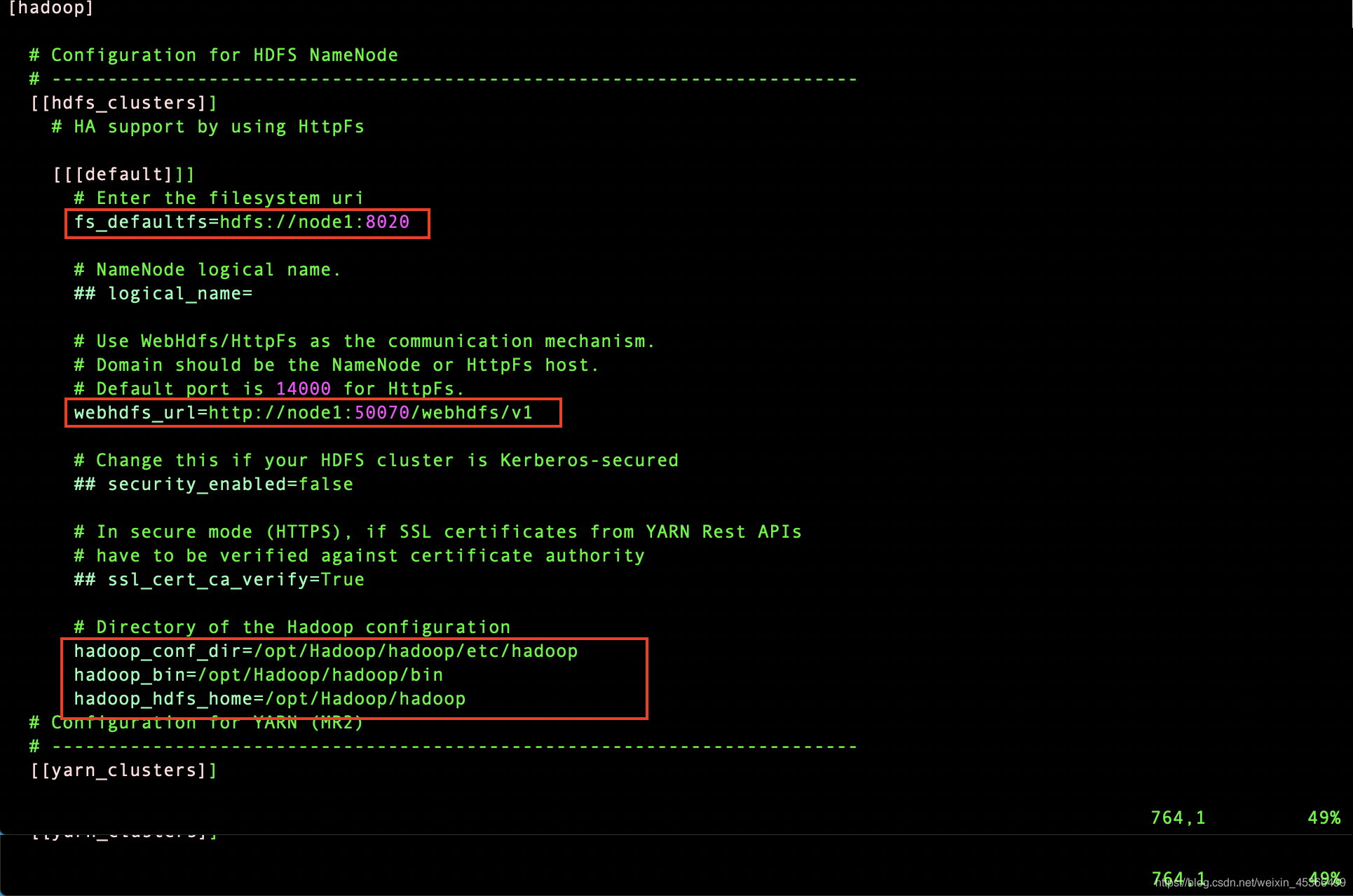
Hue与HDFS、YARN、Hive、MySQL、HBase的集成
一、Hue与HDFS的集成第一步进入到/opt/Hadoop/hue/desktop/conf目录下,修改hue.ini文件修改如下:fs_defaultfs=hdfs://node1:8020 webhdfs_url=http://node1:50070/webhdfs/v1 hadoop_con...
Cloudera-manager(CDH6.3.0)大数据平台搭建一指禅(impala,kudu,hdfs,hive,kafka,yarn,spark,hbase,hue)
Cloudera-manager(CDH6.3.0)大数据平台搭建一指禅指南(impala,kudu,hdfs,hive,kafka,yarn,spark,hbase,hue) CHD6,大量hadoop生态的重大更新升级,果断把现有系统升级到CHD6上。 准备: 192.168.88.31 mas...
大数据平台解决方案,Hadoop + HDFS+Hive+Hbase大数据开发整体架构设计
波若大数据平台Hadoop + HDFS+Hive+Hbase大数据开发工具剖析: HDFS:分布式、高度容错性文件系统,能提供高吞吐量的数据访问,非常适合大规模数据集上的应用,大规模的波若大数据平台(BR-odp)用户部署上1000台的HDFS集群。数据规模高达50PB以上 HDFS和MR共同组成...
HDFS+MapReduce+Hive+HBase十分钟快速入门
1. 前言 本文的目的是让一个从未接触Hadoop的人,在很短的时间内快速上手,掌握编译、安装和简单的使用。 2. Hadoop家族 截止2009-8-19日,整个Had...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐



文件存储HDFS版您可能感兴趣
- 文件存储HDFS版绑定
- 文件存储HDFS版nas
- 文件存储HDFS版容器
- 文件存储HDFS版文件
- 文件存储HDFS版flink
- 文件存储HDFS版parquet
- 文件存储HDFS版设置
- 文件存储HDFS版格式
- 文件存储HDFS版映射
- 文件存储HDFS版hadoop
- 文件存储HDFS版数据
- 文件存储HDFS版大数据
- 文件存储HDFS版操作
- 文件存储HDFS版api
- 文件存储HDFS版命令
- 文件存储HDFS版java
- 文件存储HDFS版集群
- 文件存储HDFS版存储
- 文件存储HDFS版文件存储
- 文件存储HDFS版配置
- 文件存储HDFS版分布式文件系统
- 文件存储HDFS版目录
- 文件存储HDFS版架构
- 文件存储HDFS版读取
- 文件存储HDFS版namenode
- 文件存储HDFS版mapreduce