基于Apache Hudi和Debezium构建CDC入湖管道
1. 背景当想要对来自事务数据库(如 Postgres 或 MySQL)的数据执行分析时,通常需要通过称为更改数据捕获 CDC的过程将此数据引入数据仓库或数据湖等 OLAP 系统。 Debezium 是一种流行的工具,它使 CDC 变得简单,其提供了一种通过读取更改日志来捕获数据库中行级更改的方法,...

基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化。虽然能够在海量批处理场景中取得不错的效果,但依然存在如下现状问题:问题一:不支持事务由于传统大数据方案不支持...

使用Apache Pulsar + Hudi构建Lakehouse方案了解下?
1. 动机Lakehouse最早由Databricks公司提出,其可作为低成本、直接访问云存储并提供传统DBMS管系统性能和ACID事务、版本、审计、索引、缓存、查询优化的数据管理系统,Lakehouse结合数据湖和数据仓库的优点:包括数据湖的低成本存储和开放数据格式访问,数据仓库强大的管理和优化能...

使用Apache Hudi + Amazon S3 + Amazon EMR + AWS DMS构建数据湖
1. 引入数据湖使组织能够在更短的时间内利用多个源的数据,而不同角色用户可以以不同的方式协作和分析数据,从而实现更好、更快的决策。Amazon Simple Storage Service(amazon S3)是针对结构化和非结构化数据的高性能对象存储服务,可以用来作为数据湖底层的存储服务。然而许多...
使用Apache Spark和Apache Hudi构建分析数据湖
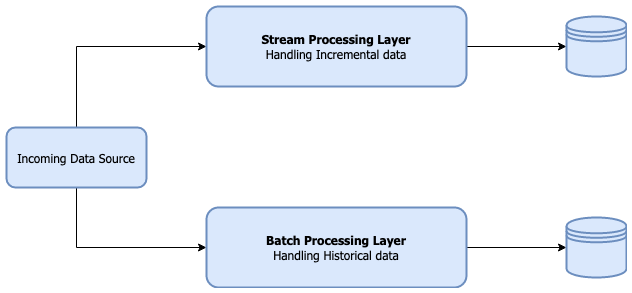
1. 引入大多数现代数据湖都是基于某种分布式文件系统(DFS),如HDFS或基于云的存储,如AWS S3构建的。遵循的基本原则之一是文件的“一次写入多次读取”访问模型。这对于处理海量数据非常有用,如数百GB到TB的数据。但是在构建分析数据湖时,更新数据并不罕见。根据不同场景,这些更新频率可能是每小时...
Uber基于Apache Hudi构建PB级数据湖实践
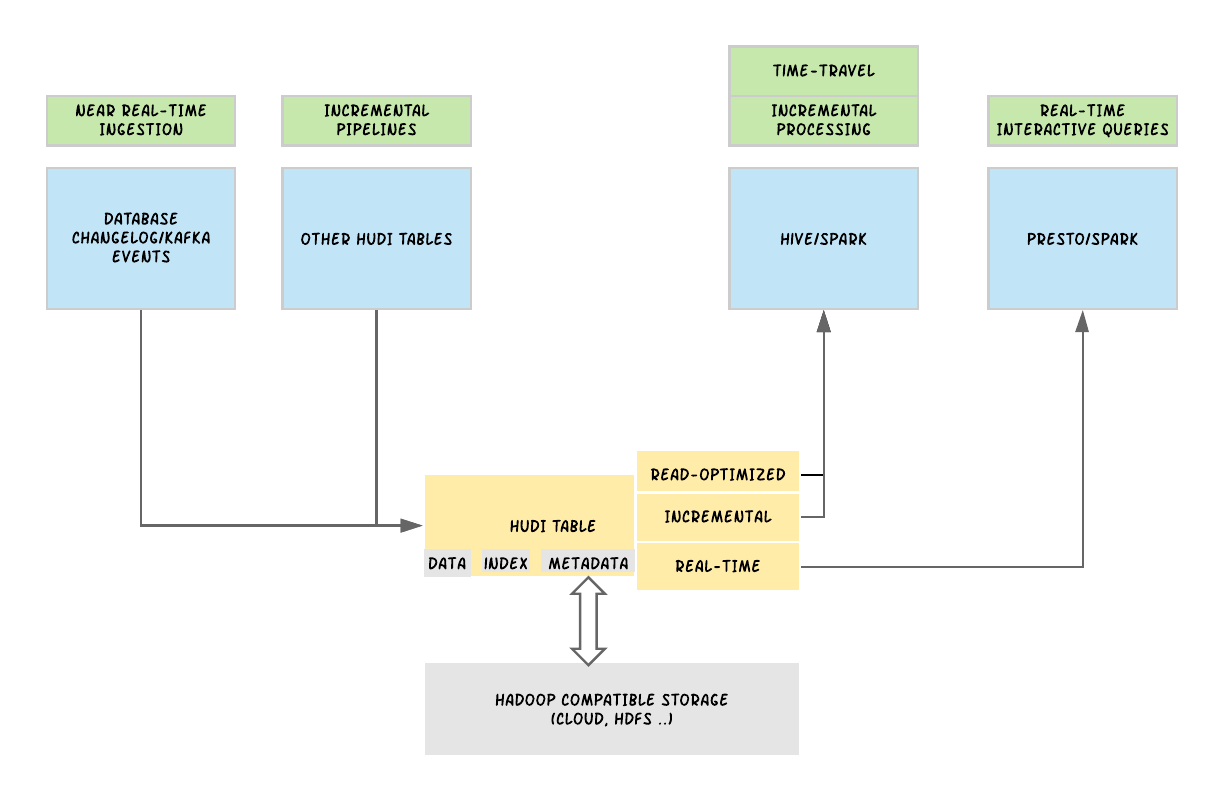
1. 引言从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全、无缝的运输和交付体验需要可靠、高性能的大规模数据存储和分析。2016年,Uber开发了增量处理框架Apache Hudi,以低延迟和高效率为关键业务数据管道赋能。一年后,我们开源了该解决方案,以使得其他有需要的组织也可以利...

Apache RocketMQ + Hudi 快速构建 Lakehouse
本文目录背景知识大数据时代的构架演进RocketMQ Connector&StreamApache Hudi构建Lakehouse实操本文标题包含三个关键词:Lakehouse、RocketMQ、Hudi。我们先从整体Lakehouse架构入手,随后逐步分析架构产生的原因、架构组件特点以及构...

Apache Hudi 在 B 站构建实时数据湖的实践
本文作者喻兆靖,介绍了为什么 B 站选择 Flink + Hudi 的数据湖技术方案,以及针对其做出的优化。主要内容为:传统离线数仓痛点数据湖技术方案Hudi 任务稳定性保障数据入湖实践增量数据湖平台收益社区贡献未来的发展与思考GitHub 地址 https://github.com/apache/...
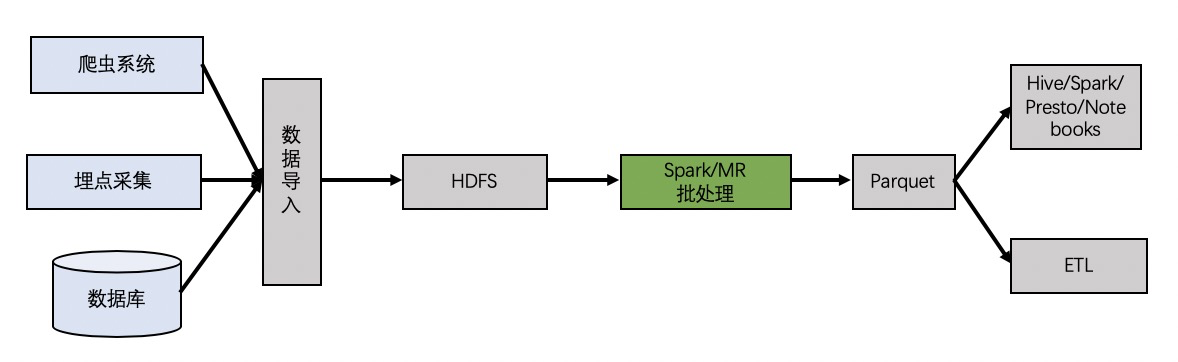
基于阿里云数据湖分析服务和Apache Hudi构建云上实时数据湖
1. 什么是实时数据湖 大数据时代数据格式的多样化,如结构化数据、半结构化数据、非结构化数据,传统数据仓库难以满足各类数据的存储,同时传统数仓已经难以满足上层应用如交互式分析、流式分析、ML等的多样化需求。而数仓T+1的数据延迟导致分析延迟较大,不利于企业及时洞察数据价值;同时随着云计算技术发展以及...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。