[帮助文档] 迁移Hadoop集群至DataLake集群
本文将详细阐述如何将您已有的旧版数据湖集群(Hadoop),高效地迁移至数据湖集群(DataLake),以下分别简称“旧集群”和“新集群”。迁移过程将充分考虑旧集群的版本、元数据类型以及存储方式,并针对这些因素,提供适应新集群的迁移策略与步骤。
[帮助文档] 如何开通EMRDoctor
E-MapReduce(简称EMR)的数据湖(DataLake)、数据服务(DataServing)和自定义业务场景下的集群默认提供EMR Doctor服务,如果您使用的是旧版数据湖场景下的Hadoop集群类型(EMR-3.41.0之前版本、EMR 4.x版本、EMR-5.6.0之前版本),则需要提...

[帮助文档] 介绍数据湖集群特性,以及与旧版Hadoop集群之间的差异
E-MapReduce(简称EMR)新版控制台提供了数据湖集群,一个更灵活、可靠,以及高效的大数据计算集群。同时,您可以基于该集群轻松构建一个可扩展的数据管道。本文为您介绍数据湖集群支持的特性,以及与旧版Hadoop集群之间的差异。
[帮助文档] Hadoop集群事件查看及告警
E-MapReduce(简称EMR)的事件中心用于记录Hadoop类型集群发生的重要事件,并将其自动同步到云监控服务。您可以在EMR控制台上查看集群的事件,并在云监控控制台上设置相应的事件告警。
[帮助文档] 基于Hadoop集群支持Delta Lake或Hudi存储机制
Delta Lake和Hudi是数据湖方案中常用的存储机制,为数据湖提供流处理、批处理能力。MaxCompute基于开源的Hadoop集群提供了支持Delta或Hudi存储机制的湖仓一体架构。您可以通过MaxCompute查询到实时数据,即时洞察业务数据变化。
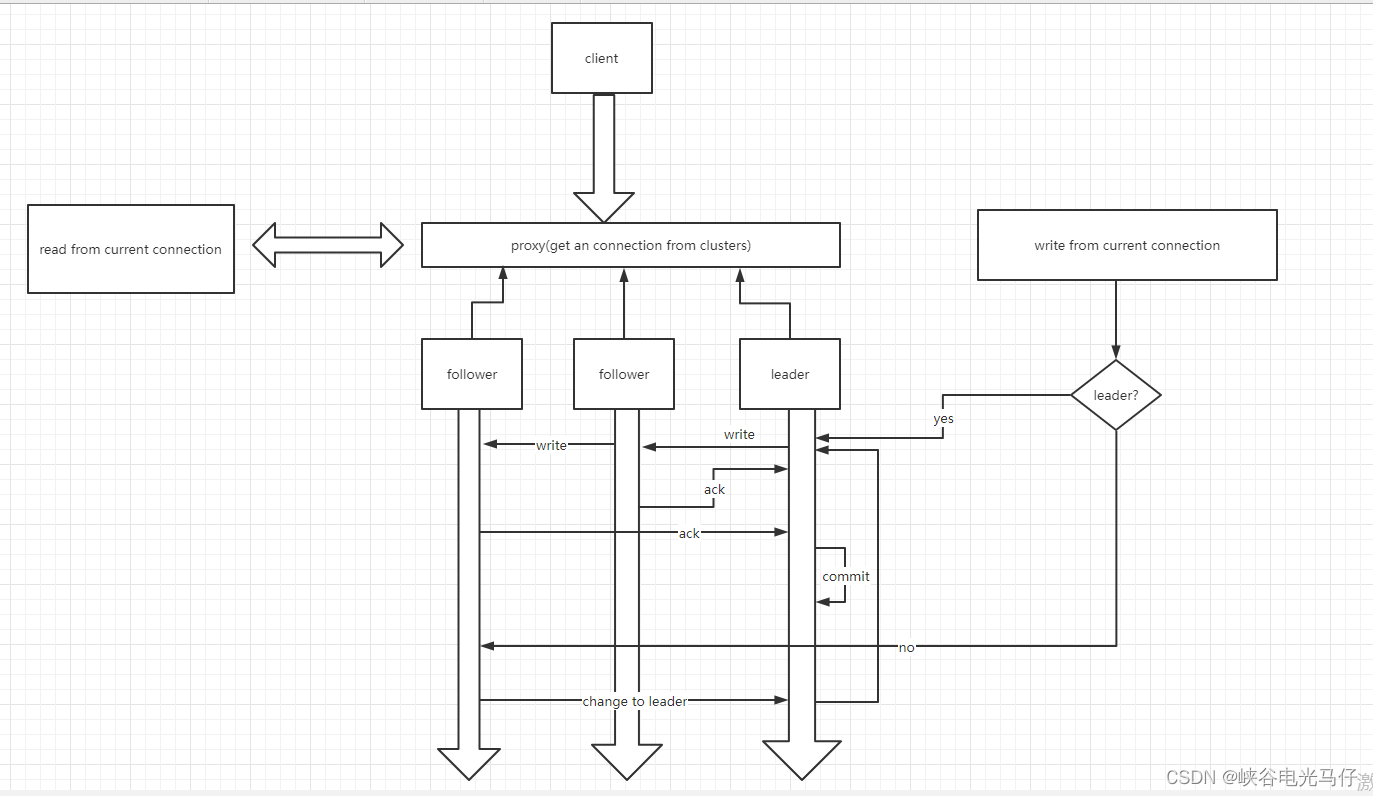
flink hadoop 从0~1分布式计算与大数据项目实战(4)zookeeper内部原理流程简介以及java curator client操作集群注册,读取
zookeeper内部原理流程用processon画的有点大,看不清的可以放大查看流程图详解1.zookeeper 集群(至少个节点)启动后,会自动选举出一个leader,其他节点为follower 跟随节点 2.client 连接给定的单地址或者集群,连接集群时,会挑选一个可用的节点进行连接,整个...

Hadoop快速入门——第四章、zookeeper(集群)(2)
9、远程拷贝到【a1】与【a2】scp -r /opt/zookeeper a1:/opt/zookeeper scp -r /opt/zookeeper a2:/opt/zookeeper10、修改【a1】与【a2】的myid编号vi /opt/zookeeper/data/myid11、脚本拷贝...
Hadoop快速入门——第四章、zookeeper(集群)(1)
前置条件:配置ssh免密登录&hadoop分布式1、上传【zookeeper-3.4.6.tar.gz】文件2、解压文件tar -zxvf zookeeper-3.4.6.tar.gz3、修改文件名称方便操作 mv zookeeper-3.4.6 zookeeper4、编辑脚本文件vi /e...
Hadoop中启动zookeeper集群启动zookeeper服务的操作步骤以及代码分别是什么?
Hadoop中启动zookeeper集群启动zookeeper服务的操作步骤以及代码分别是什么?
Hadoop中安装配置Zookeeper集群编辑myid文件的操作步骤以及代码分别是什么?
Hadoop中安装配置Zookeeper集群编辑myid文件的操作步骤以及代码分别是什么?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









hadoop集群相关内容
- hadoop集群节点
- hadoop集群资源管理器yarn图片来源
- hadoop集群hdfs
- hadoop集群yarn
- hadoop集群模式
- 环境hadoop集群
- 大数据hadoop集群
- 大数据hadoop集群部署
- 大数据hadoop集群配置
- 运行hadoop集群
- hadoop ha集群
- hadoop集群大数据
- 集群hadoop
- 配置hadoop集群
- hadoop集群程序
- hadoop集群hbase安装
- hadoop集群hive安装
- hadoop集群安装
- hadoop集群hive
- hadoop运行集群
- hadoop mapreduce概述wordcount集群序列化
- hadoop wordcount集群
- hadoop分布式集群安装
- 大数据学习hadoop集群安装
- hadoop大数据集群
- hadoop集群设置
- mapreduce hadoop集群
- ububtu18.04安装hadoop分布集群
- hadoop集群命令
- hadoop分布式集群模式
- hadoop集群datanode
- hadoop集群机器
- hadoop集群案例
- hadoop运行模式集群配置
- hadoop集群时间同步
- hadoop运行模式集群分发
- hadoop ssh集群yarn分发
- hadoop集群mapreduce
- hadoop xsync集群分发脚本
- hadoop集群环境变量
- hadoop集群检查
- 生产环境hadoop集群
- 部署hadoop集群
- hadoop集群centos
- hadoop集群master运行
- hadoop集群云计算centos
- hadoop集群云计算
- 阿里云服务器hadoop集群
hadoop更多集群相关
- hadoop集群进程
- 搭建hadoop集群
- hadoop集群步骤
- 安装hadoop集群
- hadoop hbase集群
- ambari hadoop集群
- hadoop集群进程作用是什么
- hadoop zookeeper集群步骤
- cdh5.4.7 hadoop集群
- hadoop集群安全
- hadoop集群报错
- spark hadoop集群
- hadoop伪分布集群
- hadoop tokyo集群
- hadoop集群代码
- hadoop集群运行
- hadoop集群安装配置
- hadoop集群emr
- hadoop yarn集群
- hadoop安装配置zookeeper集群代码
- 大规模hadoop集群
- ambari安装hadoop集群
- hadoop集群目录
- hadoop集群vs
- hadoop集群解决方案
- hadoop集群解决方法
- hadoop安装配置集群操作步骤代码
- hadoop集群运行报错
- hadoop集群文件步骤
- hadoop集群hbase
- hadoop集群安装配置节点
- hadoop xsync集群分发脚本操作方法
- ganglia监控hadoop集群
- hadoop集群操作步骤
- hadoop summit tokyo集群
- hadoop集群主机
- hadoop集群勒索软件攻击
- hadoop集群准备工作
- hadoop学习集群安装
- hadoop xsync集群分发脚本需求分析
- hadoop summit tokyo大规模集群
- hadoop集群登陆
- hadoop数据挖掘集群命令
- hadoop安装配置zookeeper集群操作步骤代码
- hadoop安装配置集群解压操作步骤代码
- hadoop集群nodes unhealthy解决方法