[帮助文档] 通过SeaTunnel集成平台将数据写入OSS-HDFS服务
SeaTunnel是一个开源、易用的超高性能分布式数据集成平台,支持海量数据的实时同步。本文介绍如何通过SeaTunnel集成平台将数据写入OSS-HDFS服务。
[帮助文档] AnalyticDB PostgreSQL读写HDFS、Hive或MySQL外部数据
若您需要通过AnalyticDB PostgreSQL版访问外部异构数据源(HDFS、Hive和JDBC)时,可以使用异构数据源访问功能将外部数据转换为AnalyticDB PostgreSQL版数据库优化后的格式进行查询和分析。

[帮助文档] 查询高可用集群中的HDFS数据
如果您所使用的数据集群开启了高可用,那么在查询高可用集群中的HDFS数据时,您需要进行额外的配置。建议您按照本文的操作步骤来配置StarRocks集群,以实现HDFS的高可用性。
[帮助文档] 使用OSS-HDFS服务回收站在指定时间内恢复删除的数据
使用OSS-HDFS回收站时,需要客户端将待删除文件挪至指定目录,并由服务端定时清理该目录下的数据。
[帮助文档] 如何提高访问OSS或OSS-HDFS数据时HTTP请求的响应速度
本文为您介绍如何提高访问OSS或OSS-HDFS数据时HTTP请求的响应速度,以便优化OSS或OSS-HDFS上的数据处理。
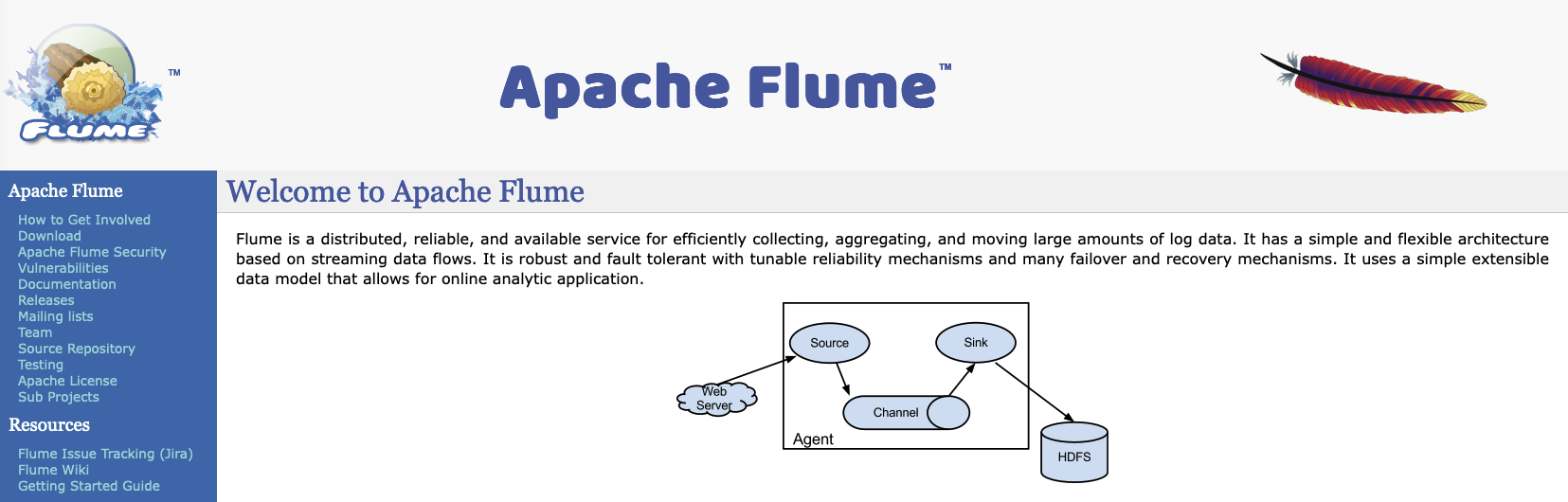
Flume实现Kafka数据持久化存储到HDFS
一、场景描述对于一些实时产生的数据,除了做实时计算以外,一般还需要归档保存,用于离线数据分析。使用Flume的配置可以实现对数据的处理,并按一定的时间频率存储,本例中将从Kafka中按天存储数据到HDFS的不同文件夹。1. 数据输入本场景中数据来自Kafka中某个Topic订阅,数据格式为json。...
请问,使用flume 消费kafka数据,上传到hdfs,出现重复消费的数据,是什么原因导致的呢
请问,使用flume 消费kafka数据,上传到hdfs,出现重复消费的数据,是什么原因导致的呢
flink 在别的集群里面运行,我怎么将kafka数据写到远程hdfs
flink 在别的集群里面运行,我怎么将kafka数据写到远程hdfs
flink消费kafka的数据写入到hdfs中,我采用了BucketingSink 这个sink将o
flink消费kafka的数据写入到hdfs中,我采用了BucketingSink 这个sink将operator出来的数据写入到hdfs文件上,并通过在hive中建外部表来查询这个。但现在有个问题,处于in-progress的文件,hive是无法识别出来该文件中的数据,可我想能在hive中实时查询...
flink将kafka中的数据落地到hdfs,在小文件和落地效率方面有什么好的建议?
背景: 现在使用的是spark streaming消费kafka的数据,然后落地到hdfs目录,产生了2个问题: 1、对于数据量较大的topic,且使用压缩存储之后,spark streaming程序会出现延迟。 2、落地的数据文件里有大量的小文件产生,namenode的压力增大 对于问题1,暂时分...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐



文件存储HDFS版数据相关内容
- 文件存储HDFS版数据流程描述
- hive文件存储HDFS版数据
- 文件存储HDFS版数据分析
- 数据文件存储HDFS版hive
- cdp数据云平台入门文件存储HDFS版迁移
- hive数据文件存储HDFS版
- 文件存储HDFS版目录数据
- 数据文件存储HDFS版学习笔记
- 文件存储HDFS版系统数据
- 文件存储HDFS版读取文件数据
- 文件存储HDFS版存储数据
- 采集数据文件存储HDFS版
- 文件存储HDFS版数据存储
- 集群数据文件存储HDFS版
- 迁移开源文件存储HDFS版数据
- distcp文件存储HDFS版迁移数据
- 文件存储HDFS版数据均衡
- 文件存储HDFS版数据存放
- 文件存储HDFS版数据存储单元
- 文件存储HDFS版块数据
- 文件存储HDFS版节点数据
- 计算数据文件存储HDFS版
- start-balancer.sh文件存储HDFS版balancer数据均衡
- 文件存储HDFS版数据hive
文件存储HDFS版您可能感兴趣
- 文件存储HDFS版文件
- 文件存储HDFS版flink
- 文件存储HDFS版parquet
- 文件存储HDFS版设置
- 文件存储HDFS版格式
- 文件存储HDFS版hive
- 文件存储HDFS版映射
- 文件存储HDFS版cdc
- 文件存储HDFS版javaapi
- 文件存储HDFS版测试
- 文件存储HDFS版hadoop
- 文件存储HDFS版大数据
- 文件存储HDFS版操作
- 文件存储HDFS版api
- 文件存储HDFS版命令
- 文件存储HDFS版java
- 文件存储HDFS版集群
- 文件存储HDFS版存储
- 文件存储HDFS版文件存储
- 文件存储HDFS版配置
- 文件存储HDFS版分布式文件系统
- 文件存储HDFS版目录
- 文件存储HDFS版架构
- 文件存储HDFS版读取
- 文件存储HDFS版namenode
- 文件存储HDFS版mapreduce