Python爬虫:Scrapy优化参数设置
修改 settings.py 文件# 增加并发 CONCURRENT_REQUESTS = 100 # 降低log级别 LOG_LEVEL = 'INFO' # 禁止cookies COOKIES_ENABLED = False # 禁止重试 RETRY_ENABLED = Fa...
Python爬虫:scrapy-splash的请求头和代理参数设置
3中方式任选一种即可1、lua中脚本设置代理和请求头:function main(splash, args) -- 设置代理 splash:on_request(function(request) request:set_proxy{ host = "27.0.0.1", p...

Python爬虫:scrapy爬虫设置随机访问时间间隔
代码示例random_delay_middleware.py# -*- coding:utf-8 -*- import logging import random import time class RandomDelayMiddleware(object): def __init__(self, ...
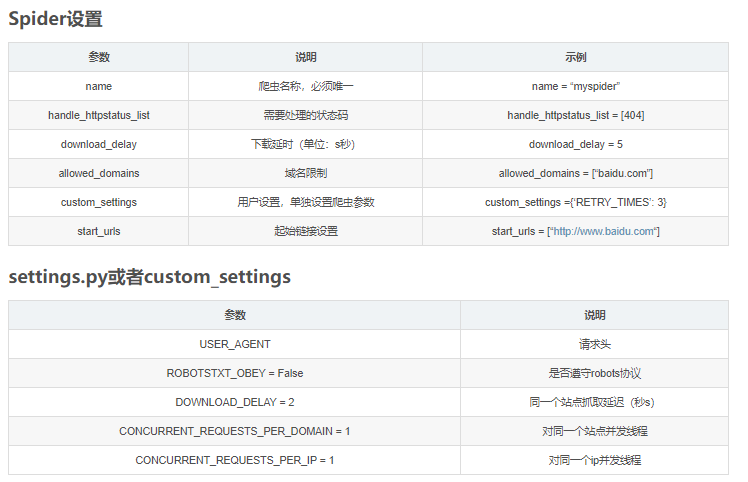
Python爬虫:scrapy框架Spider类参数设置
Python爬虫:scrapy框架Spider类参数设置
Python爬虫:scrapy框架log日志设置
Scrapy提供5层logging级别:1. CRITICAL - 严重错误 2. ERROR - 一般错误 3. WARNING - 警告信息 4. INFO - 一般信息 5. DEBUG - 调试信息logging设置通过在setting.py中进行以下设置可以被用来配置logging以下配置...
Python爬虫:scrapy框架Spider类参数设置
Spider设置参数说明示例name爬虫名称,必须唯一name = “myspider”handle_httpstatus_list需要处理的状态码handle_httpstatus_list = [404]download_delay下载延时(单位:s秒)download_delay = 5all...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








Python爬虫相关内容
- Python web爬虫
- Python爬虫beautifulsoup
- Python爬虫程序
- Python爬虫策略
- 数据采集Python爬虫
- Python爬虫代理
- Python爬虫ip
- Python爬虫伪装
- Python爬虫代理ip
- Python爬虫商品
- Python爬虫京东
- Python爬虫appium
- Python爬虫app
- Python爬虫微信朋友圈
- Python爬虫爬取
- Python爬虫微信
- Python爬虫爬取微信
- Python爬虫mitmproxy
- Python爬虫charles
- Python爬虫cookies
- Python爬虫登录
- Python爬虫github
- Python爬虫文章
- Python爬虫付费
- Python爬虫代理池
- Python爬虫原理
- Python爬虫验证码识别
- Python爬虫验证码
- Python爬虫滑动验证
- Python爬虫项目
- Python爬虫实例
- Python爬虫请求
- Python爬虫技术
- Python爬虫工具
- Python爬虫数据
- Python爬虫实战
- Python爬虫数据爬取
- Python爬虫agent
- Python爬虫分析
- Python爬虫数据采集分析
- Python爬虫数据采集
- Python爬虫实战多多商品数据分析
- Python爬虫数据分析
- Python爬虫splash
- Python爬虫源码
- Python爬虫源码总有
- Python爬虫数据抓取
- Python爬虫实战分析
- Python爬虫网页
Python更多爬虫相关
- Python爬虫库
- Python爬虫抓取
- Python爬虫scrapy
- Python爬虫入门
- Python爬虫解析
- Python爬虫入门教程
- Python爬虫urllib
- Python爬虫框架项目实战
- Python爬虫入门教程爬取
- Python爬虫电影
- Python爬虫xpath
- Python爬虫百度
- Python爬虫采集
- Python爬虫入门教程数据抓取
- Python爬虫请求头
- Python爬虫requests库
- Python爬虫线程
- Python技术爬虫
- Python爬虫技术框架
- Python网络爬虫爬虫
- Python技术框架项目实战爬虫
- Python爬虫下载
- Python爬虫get
- Python爬虫csdn
- Python爬虫ajax
- Python爬虫基础
- Python爬虫入门教程图片爬取
- Python爬虫入门教程图片
- Python爬虫报错
- Python爬虫数据库
- Python爬虫入门教程scrapy
- Python爬虫post
- Python爬虫解析网页
- Python爬虫get请求
- Python爬虫区别
- Python爬虫功能
- Python爬虫beautifulsoup4
- Python爬虫学习
- Python爬虫入门教程数据scrapy
- Python爬虫进程
- Python爬虫网站
- Python爬虫基本原理
- Python爬虫Scrapy框架
- Python爬虫页面
- Python爬虫入门教程技术
- Python网络爬虫selenium
- Python爬虫http
- Python爬虫豆瓣电影
- Python爬虫分布式
- Python爬虫入门教程多线程爬取