Python爬虫之Ajax分析方法与结果提取#6
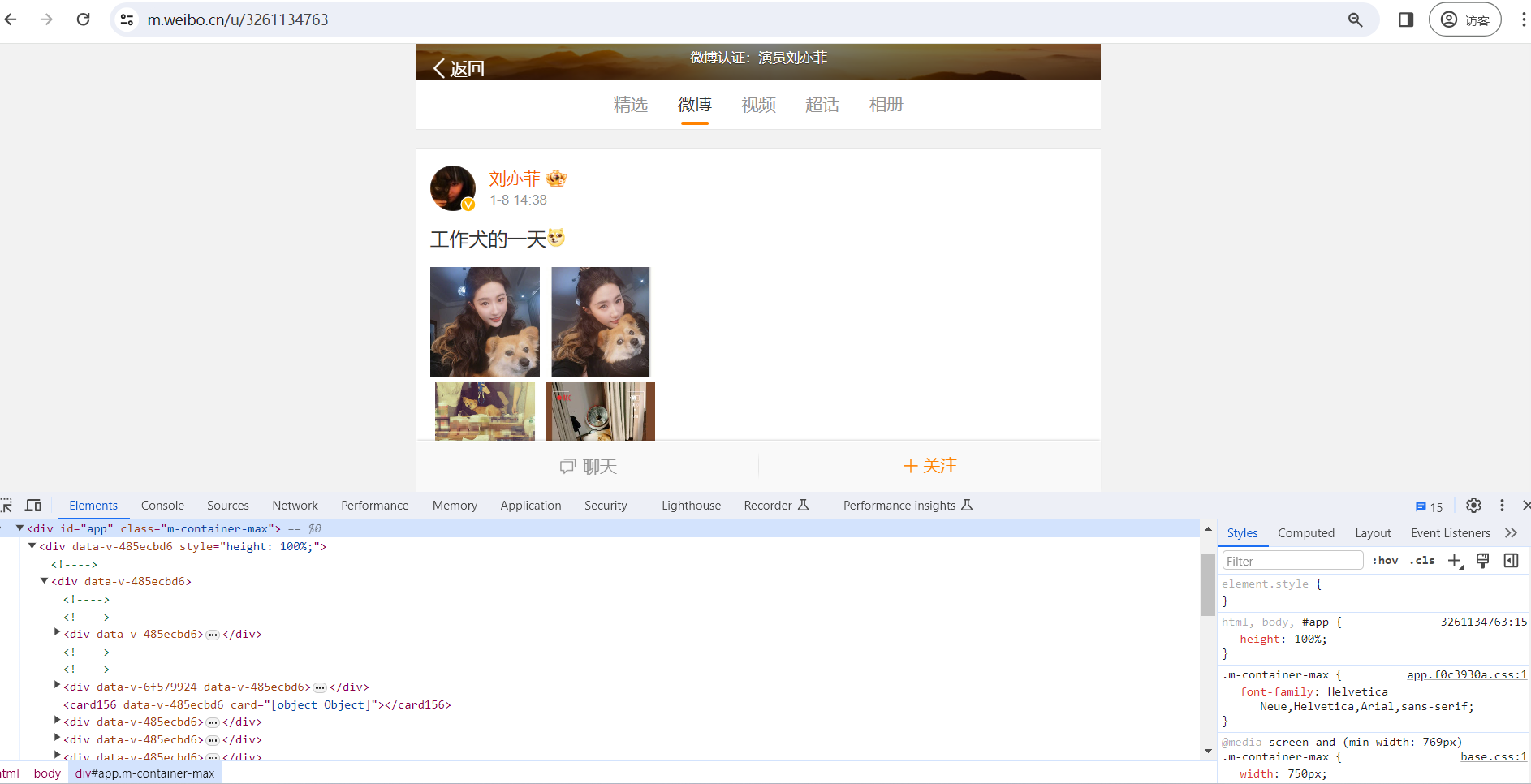
Ajax 分析方法 这里还以前面的微博为例,我们知道拖动刷新的内容由 Ajax 加载,而且页面的 URL 没有变化,那么应该到哪里去查看这些 Ajax 请求呢? 1. 查看请求 这里还需要借助浏览器的开发者工具,下面以 Chrome 浏览器为例来介绍。 首先,用 Chrome 浏览器打开微博的链接 ...
Python爬虫之Ajax数据爬取基本原理#6
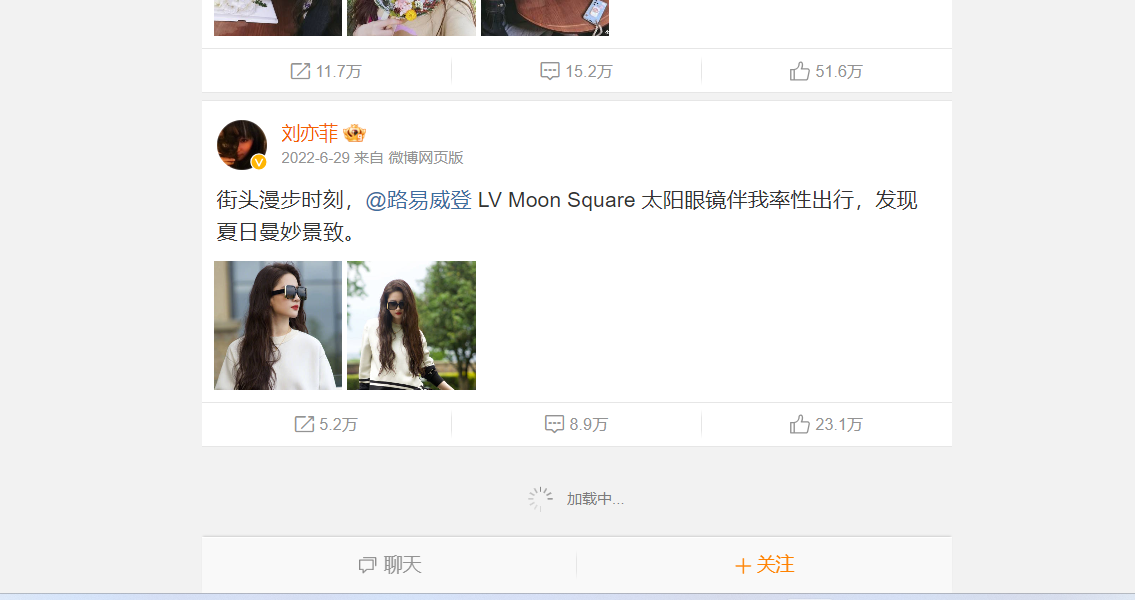
前言 有时候我们在用 requests 抓取页面的时候,得到的结果可能和在浏览器中看到的不一样:在浏览器中可以看到正常显示的页面数据,但是使用 requests 得到的结果并没有。这是因为 requests 获取的都是原始的 HTML 文档,而浏览器中的页面则是经过 JavaScript 处理数据后...

Python爬虫实战:抽象包含Ajax动态内容的网页数据
在爬虫获取网页数据时,我们经常会遇到一些网页使用Ajax技术加载动态内容的情况。这些动态内容可能包含了我们所需要的数据,但是传统的爬虫工具无法直接获取这些内容。因为传统的爬虫工具在获取网页数据时,只能获取到初始加载的静态内容,无法获取到通过Ajax技术加载动态内容。所以传统的爬虫工具只能模拟浏览器的...
【安全合规】python爬虫从0到1 - ajax的post请求(肯德基餐厅位置查询)
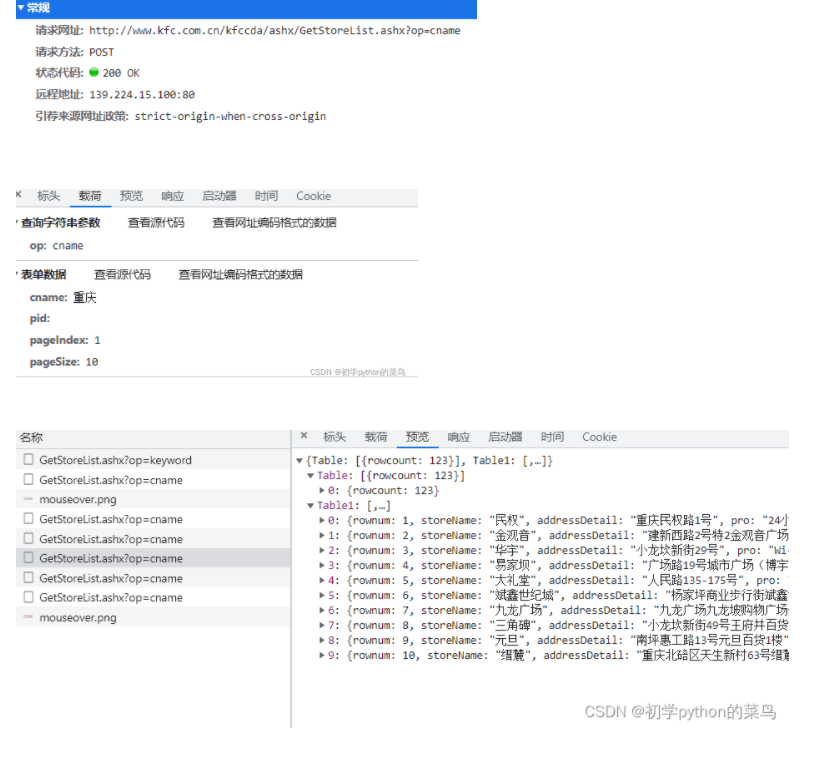
先看浏览器中的网络请求:附上源码:# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname import urllib.request import urllib.parse def down_load(page): url = '...
【安全合规】python爬虫从0到1 -ajax的get请求进阶
前面说到获得了第一页的数据。而我们要获得后面的数据时,它们的url地址并不一样。详见下图:> 第一页网址https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%A7%91%E5%B9%BB&sort=time&...
【安全合规】python爬虫从0到1 -ajax的get请求
ajax的get请求下面让我们进阶get请求的另外的中方法!!!(一)Ajax简介Ajax,全称为Asynchronous JavaScript and XML,即异步的JavaScript和XML。它不是一门编程语言,而是利用JavaScript在保证页面不被刷新、页面链接不改变的情...
Python 爬虫 AJAX 数据爬取和 HTTPS 访问| 学习笔记
开发者学堂课程【Python爬虫实战:Python 爬虫 AJAX 数据爬取和 HTTPS 访问 】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learning/course/555/detail/7643Python 爬虫 AJ...
python爬虫AJAX数据爬取和HTTPS访问 | python爬虫实战之四
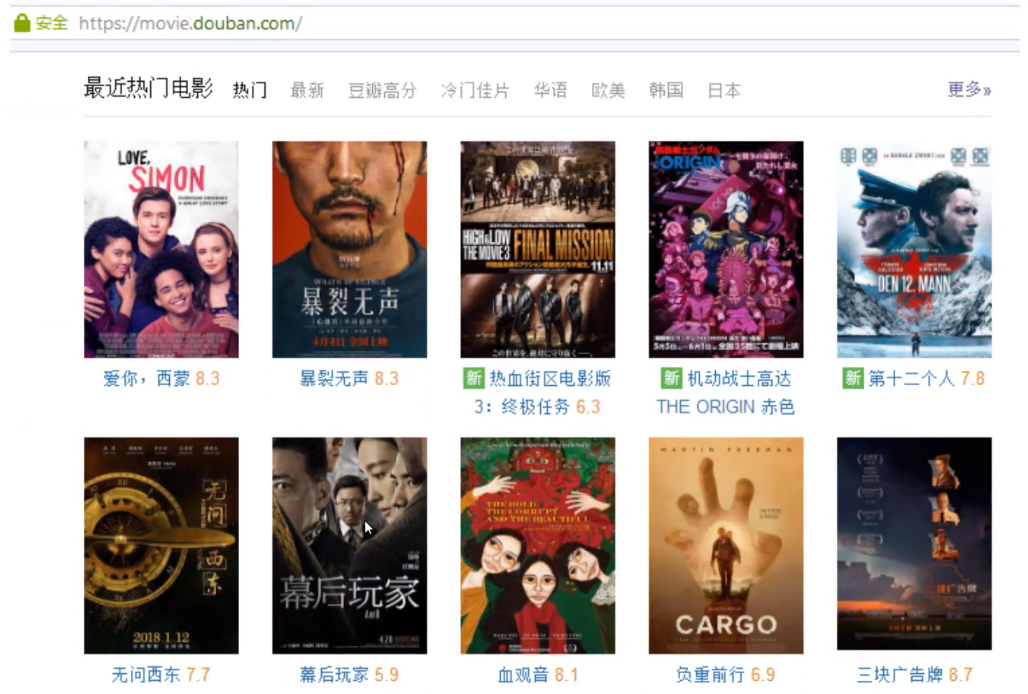
python爬虫URL编码和GETPOST请求 | python爬虫实战之三 python爬虫AJAX数据爬取和HTTPS访问 我们首先需要对之前所接触的爬虫的概念,爬取流程、爬虫标准库等内容做一个回顾。通常我们在大多数情况下编写的爬虫都为聚焦爬虫。接下来我们通过豆瓣电影来处理JSON数据。 处理J...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








Python爬虫相关内容
- Python web爬虫
- Python爬虫beautifulsoup
- Python爬虫程序
- Python爬虫策略
- 数据采集Python爬虫
- Python爬虫代理
- Python爬虫ip
- Python爬虫伪装
- Python爬虫代理ip
- Python爬虫商品
- Python爬虫京东
- Python爬虫appium
- Python爬虫app
- Python爬虫微信朋友圈
- Python爬虫爬取
- Python爬虫微信
- Python爬虫爬取微信
- Python爬虫mitmproxy
- Python爬虫charles
- Python爬虫cookies
- Python爬虫登录
- Python爬虫github
- Python爬虫文章
- Python爬虫付费
- Python爬虫代理池
- Python爬虫原理
- Python爬虫验证码识别
- Python爬虫验证码
- Python爬虫滑动验证
- Python爬虫项目
- Python爬虫实例
- Python爬虫请求
- Python爬虫技术
- Python爬虫工具
- Python爬虫数据
- Python爬虫实战
- Python爬虫数据爬取
- Python爬虫agent
- Python爬虫分析
- Python爬虫数据采集分析
- Python爬虫数据采集
- Python爬虫实战多多商品数据分析
- Python爬虫数据分析
- Python爬虫splash
- Python爬虫源码
- Python爬虫源码总有
- Python爬虫数据抓取
- Python爬虫实战分析
- Python爬虫网页
Python更多爬虫相关
- Python爬虫库
- Python爬虫抓取
- Python爬虫scrapy
- Python爬虫入门
- Python爬虫解析
- Python爬虫入门教程
- Python爬虫urllib
- Python爬虫框架项目实战
- Python爬虫入门教程爬取
- Python爬虫电影
- Python爬虫xpath
- Python爬虫百度
- Python爬虫采集
- Python爬虫入门教程数据抓取
- Python爬虫请求头
- Python爬虫requests库
- Python爬虫线程
- Python技术爬虫
- Python爬虫技术框架
- Python网络爬虫爬虫
- Python技术框架项目实战爬虫
- Python爬虫下载
- Python爬虫get
- Python爬虫csdn
- Python爬虫基础
- Python爬虫入门教程图片爬取
- Python爬虫入门教程图片
- Python爬虫报错
- Python爬虫数据库
- Python爬虫入门教程scrapy
- Python爬虫post
- Python爬虫解析网页
- Python爬虫get请求
- Python爬虫区别
- Python爬虫功能
- Python爬虫scrapy设置
- Python爬虫beautifulsoup4
- Python爬虫学习
- Python爬虫入门教程数据scrapy
- Python爬虫进程
- Python爬虫网站
- Python爬虫基本原理
- Python爬虫Scrapy框架
- Python爬虫页面
- Python爬虫入门教程技术
- Python网络爬虫selenium
- Python爬虫http
- Python爬虫豆瓣电影
- Python爬虫分布式
- Python爬虫入门教程多线程爬取