[帮助文档] 使用PyJindo访问阿里云OSS-HDFS
本文将以两种方式为您介绍如何在Python 3.6及更高版本中,利用Python的工具包PyJindo来操作OSS-HDFS。
[帮助文档] 配置OSS/OSS-HDFS Credential Provider
本文为您介绍如何配置OSS/OSS-HDFS Credential Provider。

[帮助文档] 按Bucket配置OSS/OSS-HDFS Credential Provider
本文为您介绍如何按Bucket配置OSS/OSS-HDFS Credential Provider。
[帮助文档] 加速OSS-HDFS透明缓存
本文以JindoCache支持阿里云OSS-HDFS透明缓存加速的使用方式为例,利用集群本身的存储资源缓存OSS-HDFS文件,以加速作业对OSS-HDFS的访问。
大数据计算MaxCompute有一组di上线任务,数据源是hdfs,每天都运行,是什么原因呢?
大数据计算MaxCompute有一组di上线任务,数据源是hdfs,每天都运行,但是在information_schema.TASKS_HISTORY查不到运行记录,是什么原因呢?select * from(select distinct owner_name, get_json_object(se...
为啥datax读大数据计算MaxCompute和HDFS性能差10倍啊?
为啥datax读大数据计算MaxCompute和HDFS性能差10倍啊?
[帮助文档] HBase-HDFS
HBASE-HDFS服务本质上是基于HDFS的,其主要作用是存放HBase的WAL文件,确保HBase日志的持久化与高可靠性。
大数据成长之路-- hadoop集群的部署(3)HDFS新增节点
大数据成长之路-- hadoop集群的部署(3)6、HDFS新增节点服役新数据节点目标:掌握HDFS新添加节点到集群的步骤需求基础:随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。 准备新节点第一步:复制一台新的虚拟机出来...
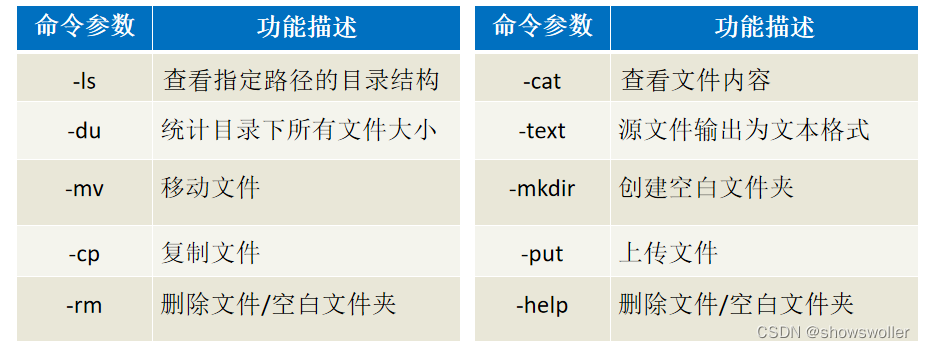
【大数据技术Hadoop+Spark】HDFS Shell常用命令及HDFS Java API详解及实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言私信~~~一、HDFS的Shell介绍Shell在计算机科学中俗称“壳”,是提供给使用者使用界面的进行与系统交互的软件,通过接收用户输入的命令执行相应的操作,Shell分为图形界面Shell和命令行式Shell。文件系统(FS)Shell包含了各种的类Shell的命...
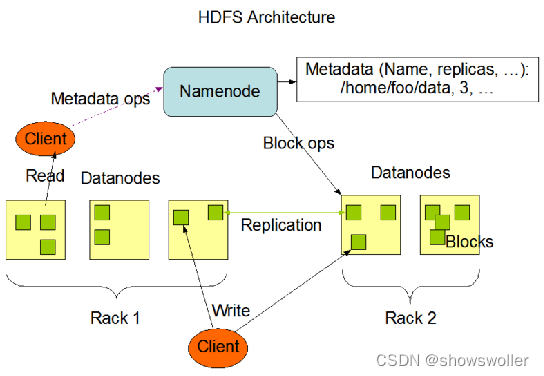
【大数据技术Hadoop+Spark】HDFS概念、架构、原理、优缺点讲解(超详细必看)
一、相关基本概念文件系统。文件系统是操作系统提供的用于解决“如何在磁盘上组织文件”的一系列方法和数据结构。分布式文件系统。分布式文件系统是指利用多台计算机协同作用解决单台计算机所不能解决的存储问题的文件系统。如单机负载高、数据不安全等问题。HDFS。英文全称为Hadoop Distributed F...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐



文件存储HDFS版您可能感兴趣
- 文件存储HDFS版文件
- 文件存储HDFS版flink
- 文件存储HDFS版parquet
- 文件存储HDFS版设置
- 文件存储HDFS版格式
- 文件存储HDFS版hive
- 文件存储HDFS版映射
- 文件存储HDFS版cdc
- 文件存储HDFS版javaapi
- 文件存储HDFS版测试
- 文件存储HDFS版hadoop
- 文件存储HDFS版数据
- 文件存储HDFS版操作
- 文件存储HDFS版api
- 文件存储HDFS版命令
- 文件存储HDFS版java
- 文件存储HDFS版集群
- 文件存储HDFS版存储
- 文件存储HDFS版文件存储
- 文件存储HDFS版配置
- 文件存储HDFS版分布式文件系统
- 文件存储HDFS版目录
- 文件存储HDFS版架构
- 文件存储HDFS版读取
- 文件存储HDFS版namenode
- 文件存储HDFS版mapreduce