[帮助文档] 迁移Hadoop集群至DataLake集群
本文将详细阐述如何将您已有的旧版数据湖集群(Hadoop),高效地迁移至数据湖集群(DataLake),以下分别简称“旧集群”和“新集群”。迁移过程将充分考虑旧集群的版本、元数据类型以及存储方式,并针对这些因素,提供适应新集群的迁移策略与步骤。
[帮助文档] 如何管理SmartDataHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。

[帮助文档] 如何管理HDFSHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。
[帮助文档] 如何管理OSS/OSS-HDFSHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。
Hadoop学习:MapReduce实现WordCount经典案例
一、✌题目要求> 统计文本中每个单词的数量二、✌实现思想> Map阶段默认输入为TextInputFormat,键值对对应为行的偏移量和每行的文本内容 > 在map函数中将每行文本进行切分,提取出每个单词 > 在Reduce阶段根据相同Key值进行累加求和 > 三、✌代...
[帮助文档] 如何通过HadoopShell命令访问OSS和OSS-HDFS
本文为您介绍如何通过Hadoop Shell命令访问OSS和OSS-HDFS。
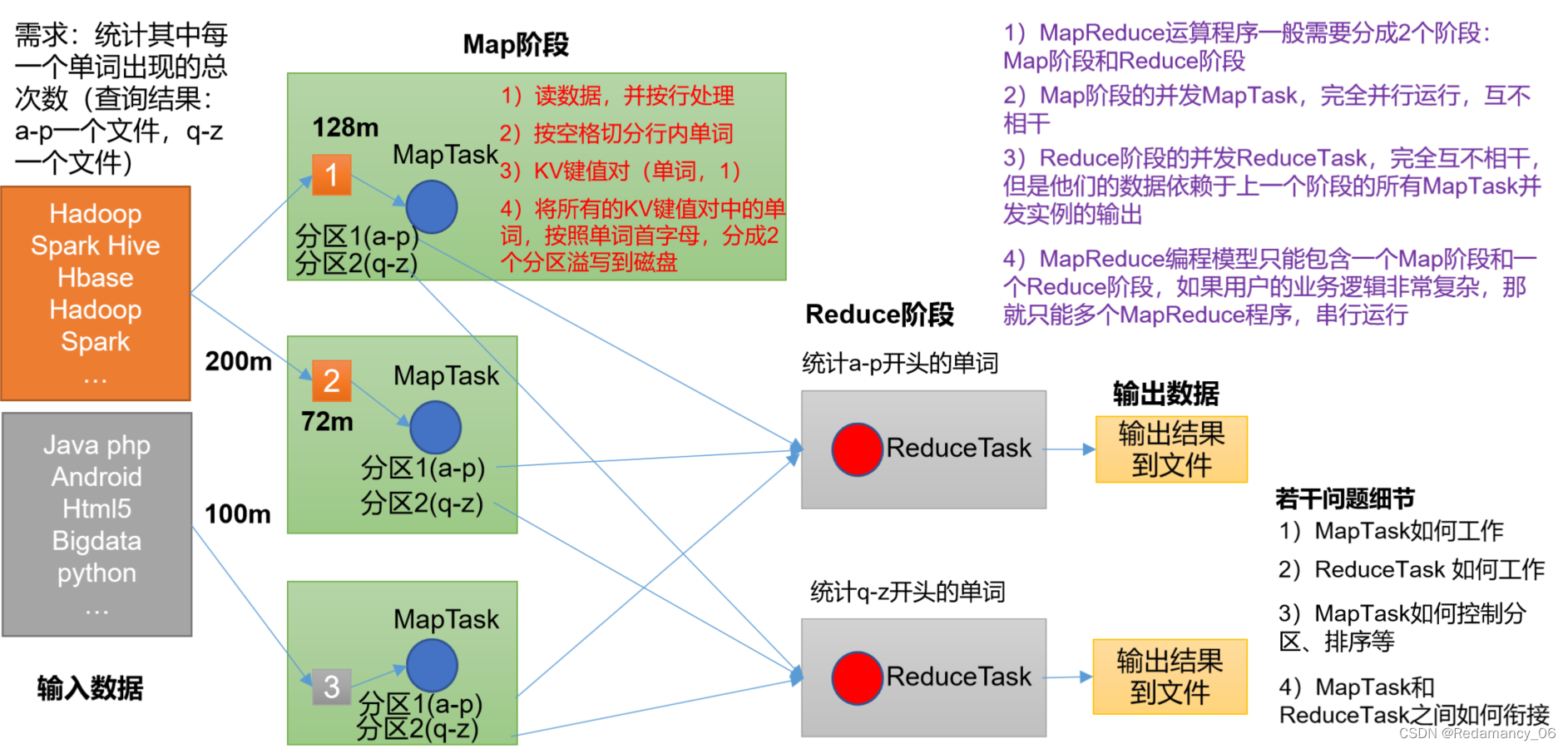
Hadoop中的MapReduce概述、优缺点、核心思想、编程规范、进程、官方WordCount源码、提交到集群测试、常用数据序列化类型、WordCount案例实操
@[toc]11.MapReduce概述11.1MapReduce定义 MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。 MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Ha...

Hadoop之MapReduce02【自定义wordcount案例】
创建MapperTask 创建一个java类继承Mapper父类接口形参说明 注意数据经过网络传输,所以需要序列化/** * 注意数据经过网络传输,所以需要序列化 * * KEYIN:默认是一行一行读取的偏移量 long LongWritable * VALUEIN:默认读取的一行的类型...
Hadoop之MapReduce01【自带wordcount案例】
一、什么是mapreduce组件 说明HDFS 分布式存储系统MapReduce 分布式计算系统YARN hadoop 的资源调度系统Common 三大[HDFS,Mapreduce,Yarn]组件的底层支撑组件,主要提供基础工具包和 RPC 框架等 Mapreduce 是一个分布式运算...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









hadoop mapreduce相关内容
- hadoop mapreduce框架
- hadoop mapreduce计算框架
- hadoop mapreduce编程
- hadoop mapreduce实践
- hadoop mapreduce编程实践
- hadoop mapreduce案例
- 实战hadoop mapreduce
- hadoop mapreduce编程案例
- hadoop mapreduce作业
- hadoop分布式计算框架mapreduce
- hadoop mapreduce概念
- hadoop分布式mapreduce
- hadoop mapreduce partitioner
- hadoop mapreduce combiner
- hadoop mapreduce概念作业
- hadoop mapreduce词频统计
- hadoop框架mapreduce
- hadoop mapreduce编程模型
- hadoop mapreduce模型
- hadoop mapreduce概念模型
- hadoop mapreduce wordcount
- hadoop mapreduce分析
- hadoop mapreduce hive
- hadoop mapreduce源码
- 云计算hadoop mapreduce
- 大数据技术hadoop mapreduce
- hadoop学习mapreduce
- hadoop学习笔记mapreduce
- hadoop mapreduce join
- hadoop mapreduce开发
- hadoop mapreduce框架原理
- hadoop学习mapreduce框架原理
- hadoop知识点mapreduce
- hadoop mapreduce shuffle
- hadoop学习mapreduce合并
- hadoop mapreduce spark
- hadoop快速入门mapreduce案例字符统计
- hadoop mapreduce流程
- hadoop mapreduce框架原理机制
- hadoop mapreduce设置
- hadoop mapreduce job
- hadoop mapreduce进程
- hadoop mapreduce序列化案例实操
- hadoop yarn mapreduce
- hadoop配置文件mapreduce
- hadoop序列化mapreduce案例
- 云计算hadoop版本生态圈mapreduce模型
- hadoop mapreduce配置项
hadoop更多mapreduce相关
- hadoop mapreduce概念学习
- hadoop mapreduce实战手册
- hadoop mapreduce性能优化
- hadoop mapreduce程序
- mapreduce hadoop参数
- hadoop运行mapreduce程序
- hadoop大数据分析实战mapreduce
- hadoop mapreduce格式
- eclipse运行mapreduce hadoop
- hadoop mapreduce学习作业
- hadoop mapreduce实战手册datanode
- hadoop mapreduce程序代码
- hadoop计算mapreduce
- hadoop mapreduce性能优化参数
- hadoop mapreduce实战手册运行
- hadoop mapreduce map原理
- hadoop mapreduce实战手册设置
- hadoop mapreduce实践文件
- hadoop mapreduce实战手册分布式集群
- hadoop框架mapreduce模式中谈海量数据处理
- hadoop算法原理mapreduce实现
- hadoop mapreduce特性
- hadoop mapreduce参数
- hadoop mapreduce开发实践分发streaming
- hadoop mapreduce实战手册简介