使用Python打造爬虫程序之HTML解析大揭秘:轻松提取网页数据
引言 在爬虫技术中,HTML解析是至关重要的一环。通过解析HTML文档,我们可以提取出网页中的有用信息,为后续的数据分析和处理提供基础。本文将带领你走进HTML解析的世界,学习使用Python进行HTML解析和数据提取的技巧和方法。 一、HTML文档结构概述 HTML(HyperText Marku...
Python爬虫:scrapy内置网页解析库parsel-通过css和xpath解析xml、html
文档https://pypi.org/project/parsel/https://github.com/scrapy/parsel安装pip install parsel代码示例from parsel import Selector selector = Selector(text="""<...

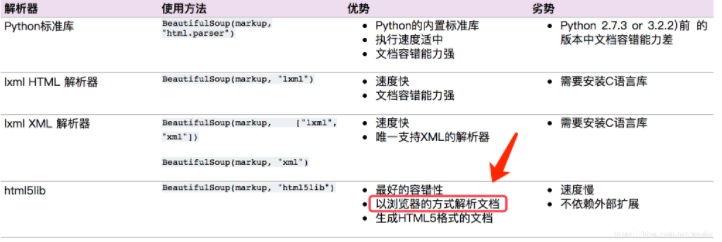
Python爬虫:scrapy利用html5lib解析不规范的html文本
问题当爬取表格(table) 的内容时,发现用 xpath helper 获取正常,程序却解析不到在chrome、火狐测试都有这个情况。出现这种原因是因为浏览器会对html文本进行一定的规范化scrapy 使用的解析器是 lxml ,下面使用lxml解析,只是函数表达不一样,xpath和css选择器...
Python爬虫:处理html实体编码
Python处理HTML实体编码python2import HTMLParser char = r"&#12345;" http_parser = HTMLParser.HTMLParser(); uChar = http_parser.unescape(char);python3from ...
10分钟教你Python爬虫(上)-- HTML和爬虫基础
各位看客老爷们,新年好。小玮又来啦。这次给大家带来的是爬虫系列的第一课---HTML和爬虫基础。在最开始的时候,我们需要先了解一下什么是爬虫。简单地来说呢,爬虫就是一个可以自动登陆网页获取网页信息的程序。举个例子来说,比如你想每天看到自己喜欢的新闻内容,而不是各类新闻平台给你推送的各种各样的信息,你...
(转载)Python写爬虫--抓取网页并解析HTML
CUHK上学期有门课叫做Semantic Web,课程project是要搜集整个系里面的教授信息,输入到一个系统里,能够完成诸如“如果选了A教授的课,因时间冲突,B教授的哪些课不能选”、 “和A教授实验室相邻的实验室都是哪些教授的”这一类的查询。这就是所谓的“语义网”了啊。。。然而最坑爹的是,所有这...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。







Python爬虫相关内容
- Python爬虫技术
- Python构建爬虫
- Python爬虫优势
- Python运行爬虫
- Python web爬虫
- Python构建web爬虫
- Python爬虫数据可视化
- Python爬虫pandas
- Python爬虫beautifulsoup
- Python爬虫图片爬取
- Python爬虫王者荣耀
- Python爬虫数据处理
- Python爬虫数据存储
- Python爬虫并发
- Python爬虫动态加载
- Python爬虫入门
- Python爬虫html解析
- Python爬虫程序
- Python爬虫策略
- Python爬虫优化
- Python爬虫网易
- Python web爬虫分析
- Python多线程爬虫
- Python并发编程爬虫
- Python线程爬虫
- 数据采集Python爬虫
- Python爬虫代理
- Python爬虫ip
- Python爬虫伪装
- Python爬虫代理ip
- Python爬虫商品
- Python爬虫京东
- Python爬虫appium
- Python爬虫app
- Python爬虫微信朋友圈
- Python爬虫爬取
- Python爬虫微信
- Python爬虫爬取微信
- Python爬虫mitmproxy
- Python爬虫charles
- Python爬虫cookies
- Python爬虫登录
- Python爬虫github
- Python爬虫文章
- Python爬虫付费
- Python爬虫代理池
- Python爬虫原理
- Python爬虫验证码识别
Python更多爬虫相关
- Python爬虫数据
- Python爬虫实战
- Python爬虫库
- Python爬虫抓取
- Python爬虫scrapy
- Python爬虫网页
- Python爬虫解析
- Python爬虫入门教程
- Python爬虫urllib
- Python爬虫数据抓取
- Python爬虫框架项目实战
- Python爬虫工具
- Python爬虫入门教程爬取
- Python爬虫电影
- Python爬虫xpath
- Python爬虫请求
- Python爬虫百度
- Python爬虫采集
- Python爬虫分析
- Python爬虫实例
- Python爬虫入门教程数据抓取
- Python爬虫请求头
- Python爬虫requests库
- Python爬虫线程
- Python爬虫验证码
- Python框架爬虫
- Python技术爬虫
- Python爬虫技术框架
- Python爬虫数据分析
- Python网络爬虫爬虫
- Python技术框架项目实战爬虫
- Python爬虫下载
- Python爬虫get
- Python爬虫csdn
- Python爬虫ajax
- Python爬虫项目
- Python爬虫基础
- Python爬虫入门教程图片爬取
- Python爬虫入门教程图片
- Python爬虫报错
- Python爬虫数据库
- Python爬虫入门教程scrapy
- Python爬虫post
- Python爬虫解析网页
- Python爬虫get请求
- Python爬虫区别
- Python爬虫功能
- Python爬虫scrapy设置
- Python爬虫数据爬取
- Python爬虫beautifulsoup4