[帮助文档] PySpark任务开发入门
您可以自行编写并构建包含业务逻辑的Python脚本,上传该脚本后,即可便捷地创建和执行PySpark任务。本文通过一个示例,为您演示如何进行PySpark任务的开发与部署。
大数据计算MaxCompute Spark可以支持yarn client模式吗?
大数据计算MaxCompute Spark可以支持yarn client模式吗?driver在本地,executor在cupid上

[帮助文档] 创建工作空间
工作空间是Serverless Spark的基本单元,用于管理任务、成员、角色和权限。所有的任务开发都需要在具体的工作空间内进行。因此,在开始任务开发之前,您需要先创建工作空间。本文将为您介绍如何在EMR Serverless Spark页面快速创建工作空间。
[帮助文档] Spark SQL任务快速入门
EMR Serverless Spark支持通过SQL代码编辑和运行任务。本文带您快速体验Spark SQL任务的创建、启动和运维等操作。
[帮助文档] RAM用户授权
当RAM用户(子账号)进行EMR Serverless Spark操作,例如创建、查看或删除工作空间等操作时,必须具有相应的权限。本文为您介绍如何进行RAM授权。
[帮助文档] 阿里云账号角色授权
使用EMR Serverless Spark前,需要授予您的阿里云账号AliyunServiceRoleForEMRServerlessSpark和AliyunEMRSparkJobRunDefaultRole系统默认角色。本文为您介绍角色授权的基本操作。
大数据计算MaxCompute Spark Local 模式启动报错,还需要开其他的配置么?
大数据计算MaxCompute Spark Local 模式启动报错,查了这个AK是有odps:权限的,还需要开其他的配置么?Exception in thread "main" java.util.concurrent.ExecutionException: [403] com.aliyun.od...

大数据问题排查系列 - SPARK STANDALONE HA 模式的一个缺陷点与应对方案
前言大家好,我是明哥!作为当今离线批处理模式的扛把子,SPARK 在绝大多数公司的数据处理平台中都是不可或缺的。而在底层使用的具体资源管理器上,SPARK 支持四种模式:standaloneyarnmesoskubernetes四种模式的简单对比如下图:以上四种模式中,mesos 在业界使用的最少&...
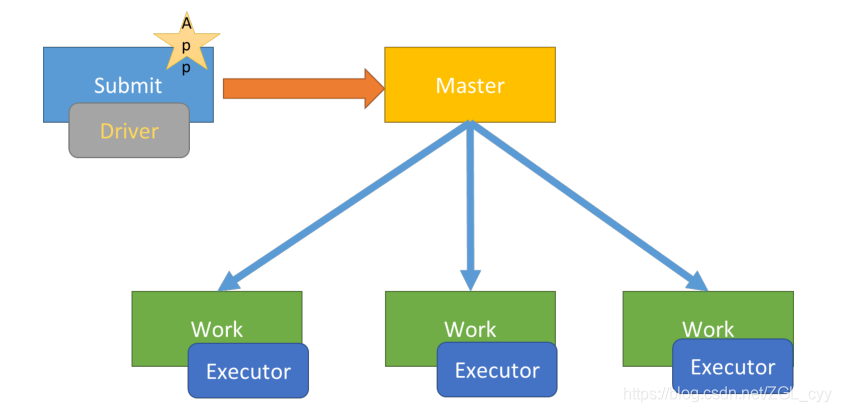
大数据Spark部署模式DeployMode
1 两种模式区别Spark Application提交运行时部署模式Deploy Mode,表示的是Driver Program运行的地方,要么是提交应用的Client:client,要么是集群中从节点(Standalone:Worker,YARN:NodeManager)...
MaxCompute Spark运行模式有哪些
MaxCompute Spark运行模式有哪些
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子








云原生大数据计算服务 MaxComputespark相关内容
- 云原生大数据计算服务 MaxCompute spark任务
- 云原生大数据计算服务 MaxCompute spark访问oss
- spark云原生大数据计算服务 MaxCompute
- 数据计算云原生大数据计算服务 MaxCompute spark节点
- 云原生大数据计算服务 MaxCompute spark资源
- 云原生大数据计算服务 MaxCompute spark运行
- 云原生大数据计算服务 MaxCompute spark sql
- 云原生大数据计算服务 MaxCompute引擎spark
- 云原生大数据计算服务 MaxCompute spark yarn模式
- 云原生大数据计算服务 MaxCompute hive spark
- 云原生大数据计算服务 MaxCompute spark引擎
- 云原生大数据计算服务 MaxCompute spark resource
- 云原生大数据计算服务 MaxCompute框架spark
- aigc云原生大数据计算服务 MaxCompute spark
- spark云原生大数据计算服务 MaxCompute资源
- 数据计算云原生大数据计算服务 MaxCompute spark访问oss
- 云原生大数据计算服务 MaxCompute spark区别
- 数据计算云原生大数据计算服务 MaxCompute spark oss
- 云原生大数据计算服务 MaxCompute spark程序访问
- 数据计算云原生大数据计算服务 MaxCompute spark程序访问
- 云原生大数据计算服务 MaxCompute spark local
- 云原生大数据计算服务 MaxCompute spark配置
- 云原生大数据计算服务 MaxCompute开发spark
- 云原生大数据计算服务 MaxCompute离线spark
- 云原生大数据计算服务 MaxCompute spark生态圈
- 云原生大数据计算服务 MaxCompute spark统计
- 云原生大数据计算服务 MaxCompute spark实战源码
- 云原生大数据计算服务 MaxCompute spark编程
- 云原生大数据计算服务 MaxCompute spark dataframe
- 云原生大数据计算服务 MaxCompute spark概念
- 云原生大数据计算服务 MaxCompute spark源码
- 云原生大数据计算服务 MaxCompute spark倒排索引实战
- 云原生大数据计算服务 MaxCompute spark流程
- 云原生大数据计算服务 MaxCompute spark优势
- 云原生大数据计算服务 MaxCompute spark数据模型
- 云原生大数据计算服务 MaxCompute spark编程模型
- 云原生大数据计算服务 MaxCompute spark企业级
- spark引擎云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute apache spark
- 云原生大数据计算服务 MaxCompute运行spark
- 云原生大数据计算服务 MaxCompute spark hbase
- 云原生大数据计算服务 MaxCompute spark ha
- 云原生大数据计算服务 MaxCompute spark概述
- 云原生大数据计算服务 MaxCompute spark dataframe dataset常用操作
- 云原生大数据计算服务 MaxCompute spark mllib
- 云原生大数据计算服务 MaxCompute spark数据分析
- 云原生大数据计算服务 MaxCompute spark streaming queries
- 云原生大数据计算服务 MaxCompute spark streaming
云原生大数据计算服务 MaxCompute更多spark相关
- 云原生大数据计算服务 MaxCompute spark mc参数
- 云原生大数据计算服务 MaxCompute spark设置
- 云原生大数据计算服务 MaxCompute spark jar包
- 云原生大数据计算服务 MaxCompute spark executor
- 云原生大数据计算服务 MaxCompute spark版本
- 云原生大数据计算服务 MaxCompute spark yarn命令
- 云原生大数据计算服务 MaxCompute spark特性
- 云原生大数据计算服务 MaxCompute spark storm
- 云原生大数据计算服务 MaxCompute spark任务参数
- 云原生大数据计算服务 MaxCompute安装spark
- 云原生大数据计算服务 MaxCompute spark打包
- 云原生大数据计算服务 MaxCompute spark场景
- spark云原生大数据计算服务 MaxCompute科学
- 云原生大数据计算服务 MaxCompute进阶spark sql
- 六六云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute spark vs
- 云原生大数据计算服务 MaxCompute spark单机
- 云原生大数据计算服务 MaxCompute spark rdd
- 云原生大数据计算服务 MaxCompute spark space
- kubernetes spark云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute spark rdd函数
- spark云原生大数据计算服务 MaxCompute案例
- 部署云原生大数据计算服务 MaxCompute spark
- 开源云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute spark连接
- 云原生大数据计算服务 MaxCompute spark应用开发
- 云原生大数据计算服务 MaxCompute产品spark
- 云原生大数据计算服务 MaxCompute spark配置项
- 云原生大数据计算服务 MaxCompute spark设置参数
- 云原生大数据计算服务 MaxCompute环境spark
- 云原生大数据计算服务 MaxCompute spark功能
- 云原生大数据计算服务 MaxCompute spark开源
- 云原生大数据计算服务 MaxCompute spark standalone集群
- 云原生大数据计算服务 MaxCompute spark系统bdas
- 云原生大数据计算服务 MaxCompute spark调优
- 云原生大数据计算服务 MaxCompute spark structured streaming
- 云原生大数据计算服务 MaxCompute spark external datasource
- 云原生大数据计算服务 MaxCompute spark开发环境
- 云原生大数据计算服务 MaxCompute spark参数作用
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute如何处理
- 云原生大数据计算服务 MaxCompute pyodps
- 云原生大数据计算服务 MaxCompute ddl
- 云原生大数据计算服务 MaxCompute failed
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute数据表
- 云原生大数据计算服务 MaxCompute生命周期
- 云原生大数据计算服务 MaxCompute region
- 云原生大数据计算服务 MaxCompute schema
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute项目