[帮助文档] 通过SeaTunnel集成平台将数据写入OSS-HDFS服务
SeaTunnel是一个开源、易用的超高性能分布式数据集成平台,支持海量数据的实时同步。本文介绍如何通过SeaTunnel集成平台将数据写入OSS-HDFS服务。
Hadoop【基础知识 05】【HDFS的JavaAPI】(集成及测试)
1.简介 想要使用 HDFS API,需要导入依赖 hadoop-client 。如果是 CDH 版本的 Hadoop,还需要额外指明其仓库地址: <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://...

[帮助文档] 如何集成HDFS到Ranger并配置权限
本文介绍如何集成HDFS到Ranger,以及如何配置权限。
[帮助文档] 如何将Ambari与Lindorm文件引擎集成来替换底层HDFS存储
Ambari提供Hadoop组件的安装、运维、监控等功能,您可以使用Ambari管理您的Hadoop集群。 本文介绍如何将Ambari与Lindorm文件引擎集成,来替换底层HDFS存储。您可以基于Ambari+Lindorm文件引擎构建云原生存储计算分离的开源大数据系统。
E-MapReduce如何配置HDFS集成Ranger
E-MapReduce如何配置HDFS集成Ranger
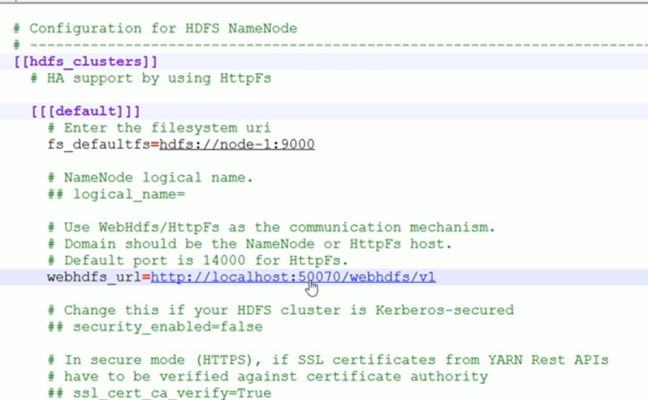
集成 Hadoop 服务(HDFS、YARN)| 学习笔记
开发者学堂课程【Hue 大数据可视化终端课程:集成 Hadoop 服务(HDFS、YARN)】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learning/course/719/detail/12849集成 Hadoop 服务(H...
他去读hdfs元数据信息的时候只读64个字段,最后导致数据集成的都是脏数据,这是啥情况呀?
datax解析以及要同步的表都是65个字段,但是他去读hdfs元数据信息的时候只读64个字段,最后导致数据集成的都是脏数据,这是啥情况呀?
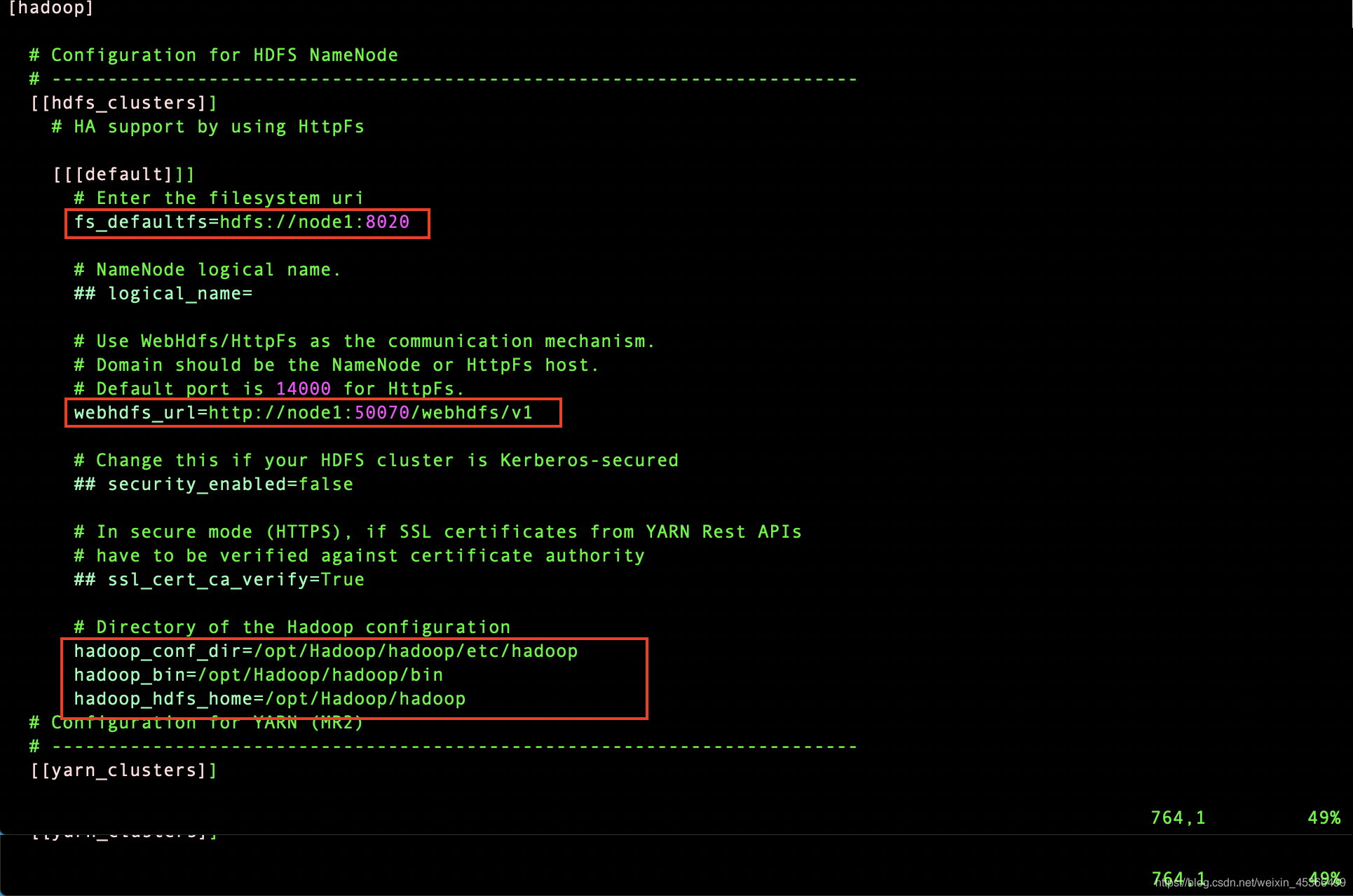
Hue与HDFS、YARN、Hive、MySQL、HBase的集成
一、Hue与HDFS的集成第一步进入到/opt/Hadoop/hue/desktop/conf目录下,修改hue.ini文件修改如下:fs_defaultfs=hdfs://node1:8020 webhdfs_url=http://node1:50070/webhdfs/v1 hadoop_con...
E-MapReduce集群中HDFS服务集成Kerberos
本文介绍在E-MapReduce集群中HDFS服务集成Kerberos。 前置: 创建E-MapReduce集群,本文以非HA集群的HDFS为例 HDFS服务在hdfs账号下启动 HDFS软件包路径/usr/lib/hadoop-current,配置在/etc/emr/hadoop-conf/ 一、...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子



文件存储HDFS版您可能感兴趣
- 文件存储HDFS版文件
- 文件存储HDFS版flink
- 文件存储HDFS版parquet
- 文件存储HDFS版设置
- 文件存储HDFS版格式
- 文件存储HDFS版hive
- 文件存储HDFS版映射
- 文件存储HDFS版cdc
- 文件存储HDFS版javaapi
- 文件存储HDFS版测试
- 文件存储HDFS版hadoop
- 文件存储HDFS版数据
- 文件存储HDFS版大数据
- 文件存储HDFS版操作
- 文件存储HDFS版api
- 文件存储HDFS版命令
- 文件存储HDFS版java
- 文件存储HDFS版集群
- 文件存储HDFS版存储
- 文件存储HDFS版文件存储
- 文件存储HDFS版配置
- 文件存储HDFS版分布式文件系统
- 文件存储HDFS版目录
- 文件存储HDFS版架构
- 文件存储HDFS版读取
- 文件存储HDFS版namenode
- 文件存储HDFS版mapreduce