Python爬虫:scrapy爬虫设置随机访问时间间隔
代码示例random_delay_middleware.py# -*- coding:utf-8 -*- import logging import random import time class RandomDelayMiddleware(object): def __init__(self, ...
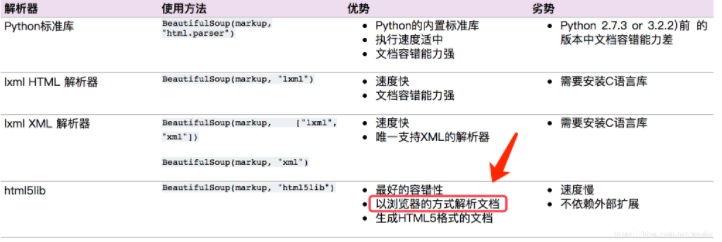
Python爬虫:scrapy利用html5lib解析不规范的html文本
问题当爬取表格(table) 的内容时,发现用 xpath helper 获取正常,程序却解析不到在chrome、火狐测试都有这个情况。出现这种原因是因为浏览器会对html文本进行一定的规范化scrapy 使用的解析器是 lxml ,下面使用lxml解析,只是函数表达不一样,xpath和css选择器...

Python爬虫:关于scrapy、Gerapy等爬虫相关框架和工具
Python爬虫:关于scrapy、Gerapy等爬虫相关框架和工具
Python爬虫:scrapy管理服务器返回的cookie
1、使用cookiesettings.py启用COOKIES_ENABLED=True # 启用cookie COOKIES_DEBUG=True # 显示发送和接受的cookie2、使用自定义cookie如果要使用登录验证的cookie,那么可以这样for url in self.start_ur...
Python爬虫:scrapy中间件及一些参数
scrapy中间件from scrapy.settings import default_settings 'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100, 'scrapy.downloadermiddlewares...

Python爬虫:scrapy框架请求参数meta、headers、cookies一探究竟(2)
cookies上面的信息中少了个response.cookies,如果添加上回报错:AttributeError: 'TextResponse' object has no attribute 'cookies'说明响应是不带cookies参数的通过 http://httpbin.org/cooki...
Python爬虫:scrapy框架请求参数meta、headers、cookies一探究竟(1)
对于scrapy请参数,会经常用到,不过没有深究今天我就来探索下scrapy请求时所携带的3个重要参数headers, cookies, meta原生参数首先新建myscrapy项目,新建my_spider爬虫通过访问:http://httpbin.org/get 来测试请求参数将爬虫运行起来# -...
Python爬虫:scrapy直接运行爬虫
一般教程中教大在命令行运行爬虫:# 方式一 $ scrapy crawl spider_name这样,每次都要切换到命令行,虽然可以按向上键得到上次运行的指令,不过至少还要敲一次运行命令还有一种方式是单独配置一个文件,spider_name是具体爬虫名称,通过pycharm运行设置,不过每次都要改....
Python爬虫:scrapy查看Cookie值
#请求Cookie Cookie = response.request.headers.getlist('Cookie') #响应Cookie Cookie = response.headers.getlist('Set-Cookie')
Python爬虫:scrapy防止爬虫被禁的策略
爬虫策略:1、动态User-Agent(随机切换User-Agent,模拟不同用户的浏览器信息),使用中间件class RandomUserAgentMiddleware(object): def process_request(self, request, spider): request.hea...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子

