配置Pycharm的Scrapy爬虫Spider子类通用模板
Scrapy爬虫的模板比较单一,每次新建爬虫程序要么重新手敲一遍,要么复制粘贴从头手敲:效率较低,容易出错,浪费时间复制粘贴:老代码需要改动的地方较多,容易漏掉,导致出错所以,pycharm中配置一个模板文件就很重要了# -*- encoding: utf-8 -*- &...
Python爬虫:scrapy框架Spider类参数设置
Python爬虫:scrapy框架Spider类参数设置
Python爬虫:scrapy框架Spider类参数设置
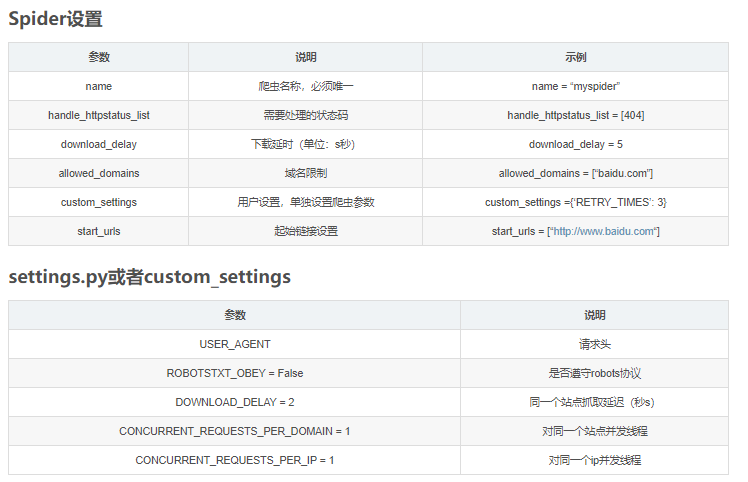
Spider设置参数说明示例name爬虫名称,必须唯一name = “myspider”handle_httpstatus_list需要处理的状态码handle_httpstatus_list = [404]download_delay下载延时(单位:s秒)download_delay = 5all...
爬虫之scrapy报错spider 农田 ?报错
参照了此链接:https://www.cnblogs.com/derek1184405959/p/8450457.html 一模一样,但是一直报错 但是我的spider文件如下. tencentPosition.py中name为main文件: 想问下是什么问题
scrapyd&scrapy:如何针对不同spider输出不同日志文件并且能在scrapyd中查看?
我的scrapy项目有多个不同的spider,我想针对不同的spider输出不同的日志文件,所以我在每个spider中重写了custor_settings,就像这样 settings = get_project_settings() today = time.strftime("%Y-%m-%d",...
scrapy分布式Spider源码分析及实现过程
分布式框架scrapy_redis实现了一套完整的组件,其中也实现了spider,RedisSpider是在继承原scrapy的Spider的基础上略有改动,初始URL不在从start_urls列表中读取,而是从redis起始队列中读取。 scrapy_redis源码在scrapy.redis.sp...
Scrapy框架的使用之Spider的用法
本文来自云栖社区官方钉群“Python技术进阶”,了解相关信息可以关注“Python技术进阶”。 在Scrapy中,要抓取网站的链接配置、抓取逻辑、解析逻辑里其实都是在Spider中配置的。在前一节实例中,我们发现抓取逻辑也是在Spider中完成的。本节我们就来专门了解一下Spider的基本用法。 ...
Scrapy框架的使用之Spider的用法
在Scrapy中,要抓取网站的链接配置、抓取逻辑、解析逻辑里其实都是在Spider中配置的。在前一节实例中,我们发现抓取逻辑也是在Spider中完成的。本节我们就来专门了解一下Spider的基本用法。 1.Spider运行流程 在实现Scrapy爬虫项目时,最核心的类便是Spider类了,它定义了如...
为Scrapy项目提供多个Spider
为Scrapy项目提供多个Spider scrapy startproject project name 在终端输入上述命令后,会根据生成一个完整的爬虫项目 此时的项目树如下 |-- JobCrawler |-- __init__.py |-- items.py |-- middlewares.py...
scrapy 爬取百度知道,多spider子一个项目中,使用一个pielines
爬取过程中 遇见 百度蜘蛛反爬 robot.txt,我们可以在scrapy 的setting.py 配置文件下配置 ROBOTSTXT_OBEY = False 最终代码 # -*- coding: utf-8 -*- from scrapy.spider import Spider from sc...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子

