Python爬虫:scrapy框架Spider类参数设置
Python爬虫:scrapy框架Spider类参数设置
python爬虫:scrapy框架Scrapy类与子类CrawlSpider
Scrapy类name 字符串,爬虫名称,必须唯一,代码会通过它来定位spiderallowed_domains 列表,允许域名没定义 或 空: 不过滤,url不在其中: url不会被处理,域名过滤功能: settings中OffsiteMiddlewarestart_urls:列表或者元组,任务的...
Python爬虫:scrapy框架Spider类参数设置
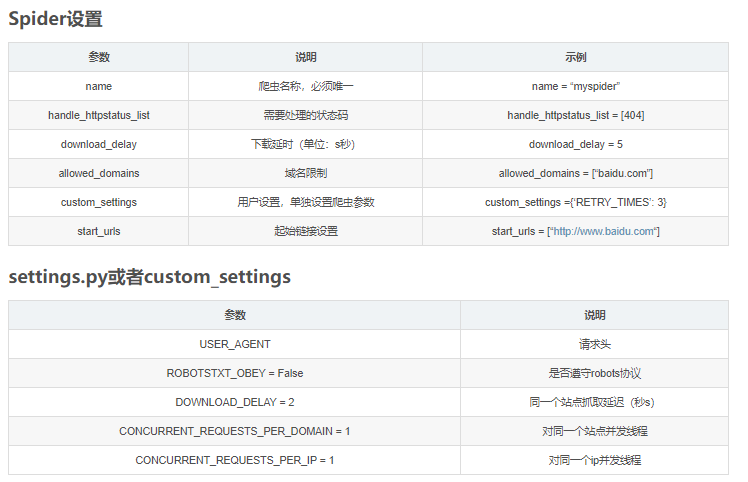
Spider设置参数说明示例name爬虫名称,必须唯一name = “myspider”handle_httpstatus_list需要处理的状态码handle_httpstatus_list = [404]download_delay下载延时(单位:s秒)download_delay = 5all...
手把手教你进行Scrapy中item类的实例化操作
接下来我们将在爬虫主体文件中对Item的值进行填充。 1、首先在爬虫主体文件中将Item模块导入进来,如下图所示。 2、第一步的意思是说将items.py中的ArticleItem类导入到爬虫主体文件中去,将两个文件串联起来,其中items.py的部分内容如下图所示。 3、将这个ArticleIte...
scrapy自动多网页爬取CrawlSpider类(五)
一.目的。 自动多网页爬取,这里引出CrawlSpider类,使用更简单方式实现自动爬取。 二.热身。 1.CrawlSpider (1)概念与作用: 它是Spider的派生类,首先在说下Spider,它是所有爬虫的基类,对于它的设计原则是只爬取start_url列表中的网页,而从爬取的网页中获取l...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子

