各位,Flink 的离线计算的数据是怎么存放的?是存在 HDFS(或Hive)上的吗?
各位,Flink 的离线计算的数据是怎么存放的?是存在 HDFS(或Hive)上的吗?
HBase 是基于 HDFS 的存储计算分离架构的 WideColumn 模型数据库,它的优点是什么
HBase 是基于 HDFS 的存储计算分离架构的 WideColumn 模型数据库,它的优点是什么?

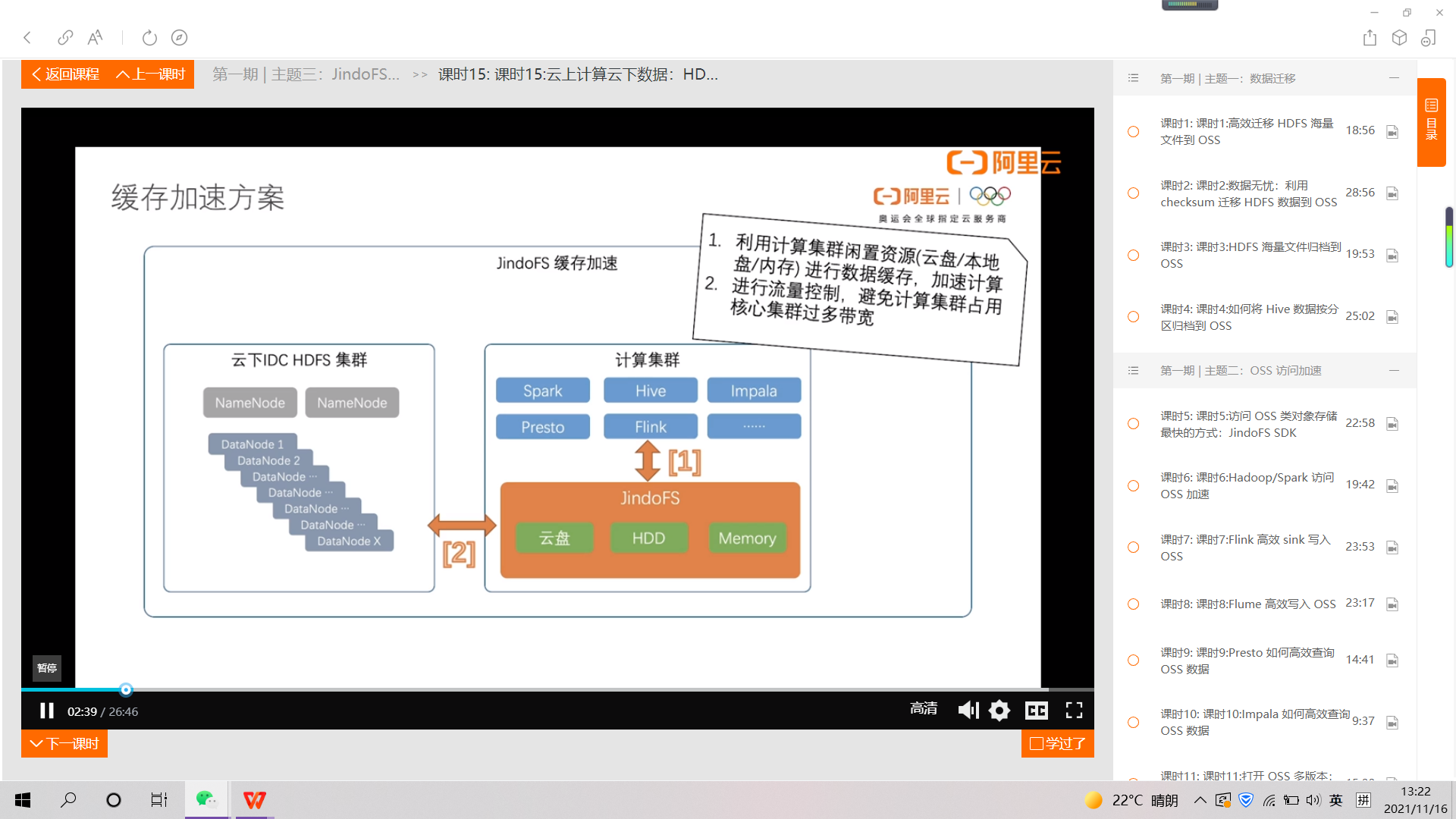
云上计算云下数据: HDFS 缓存加速 | 学习笔记
开发者学堂课程【数据湖 JindoFS + OSS 实操干货36讲:云上计算云下数据: HDFS 缓存加速】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learning/course/833/detail/13975云上计算云下数...
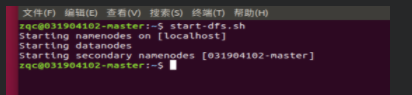
【大数据计算】(一) HDFS操作方法和基础编程
1. HDFS操作常用Shell命令1.1 查看命令使用方法启动Hadoopstart-dfs.sh查看各种命令hdfs dfs -help1.2 HDFS目录操作1.2.1 目录操作方法查看HDFS下所有的目录hdfs dfs -ls创建一个input_test的目录hdfs dfs -mkdir...

数据湖实操讲解【JindoFS 缓存加速】第十五讲:云上计算云下数据:HDFS 缓存加速
本期导读 :【JindoFS 缓存加速】第十五讲主题:云上计算云下数据:HDFS 缓存加速讲师:抚月,阿里巴巴计算平台事业部 开源大数据平台 技术专家内容框架:背景介绍功能介绍使用方法实操演示直播回放链接:(15讲)https://developer.aliyun.com...
CDH在云上利用文件存储HDFS实现存储计算分离
阿里云文件存储HDFS服务是阿里云专门针对先进的存储计算分离架构下的大数据分析场景定制推出的文件存储服务。文件存储HDFS采用全自研的底层架构,有效规避了开源HDFS系统的诸多短板,并提供标准的HDFS访问协议,用户无需对现有大数据分析应用做任何修改,即可使用具备无限容量及性能扩展、单一命名空间、高...
为数据计算提供强力引擎,阿里云文件存储HDFS v1.0公测发布
在2019年3月的北京云栖峰会上,阿里云正式推出全球首个云原生HDFS存储服务—文件存储HDFS,为数据分析业务在云上提供可线性扩展的吞吐能力和免运维的快速弹性伸缩能力,降低用户TCO。阿里云文件存储HDFS的发布真正解决了HDFS文件系统不适应云上场景的缺陷问题,用户无须花费精力维护和优化底层存储...
想了解Spark ShuffleMapTask计算的输出文件,是如何把大于内存的输入数据(HDFS数据源)进行合并相同key,并进行排序的
[问题]).ShuffleMapTask输出数据文件前,key合并,和排序是如何做到的,如果数据远大于内存?).SPARK 1.6.0-cdh5.15.0[复现]).scala worldcount: val distFile:org.apache.spark.rdd.RDD[String] = s...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子



文件存储HDFS版您可能感兴趣
- 文件存储HDFS版文件
- 文件存储HDFS版flink
- 文件存储HDFS版parquet
- 文件存储HDFS版设置
- 文件存储HDFS版格式
- 文件存储HDFS版hive
- 文件存储HDFS版映射
- 文件存储HDFS版cdc
- 文件存储HDFS版javaapi
- 文件存储HDFS版测试
- 文件存储HDFS版hadoop
- 文件存储HDFS版数据
- 文件存储HDFS版大数据
- 文件存储HDFS版操作
- 文件存储HDFS版api
- 文件存储HDFS版命令
- 文件存储HDFS版java
- 文件存储HDFS版集群
- 文件存储HDFS版存储
- 文件存储HDFS版文件存储
- 文件存储HDFS版配置
- 文件存储HDFS版分布式文件系统
- 文件存储HDFS版目录
- 文件存储HDFS版架构
- 文件存储HDFS版读取
- 文件存储HDFS版namenode
- 文件存储HDFS版mapreduce