Apache Hudi 0.9.0版本重磅发布!更强大的流式数据湖平台
1. 重点特性1.1 Spark SQL支持0.9.0 添加了对使用 Spark SQL 的 DDL/DML 的支持,朝着使所有角色(非工程师、分析师等)更容易访问和操作 Hudi 迈出了一大步。 用户现在可以使用 CREATE TABLE....USING HUDI 和 CREATE TABLE ...

基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化。虽然能够在海量批处理场景中取得不错的效果,但依然存在如下现状问题:问题一:不支持事务由于传统大数据方案不支持...


通过Apache Hudi和Alluxio建设高性能数据湖
1.T3出行数据湖总览T3出行当前还处于业务扩张期,在构建数据湖之前不同的业务线,会选择不同的存储系统、传输工具以及处理框架,从而出现了严重的数据孤岛使得挖掘数据价值的复杂度变得非常高。由于业务的迅速发展,这种低效率成为了我们的工程瓶颈。我们转向了基于阿里巴巴OSS(类似于AWS S3的对象存储)的...

使用Apache Hudi + Amazon S3 + Amazon EMR + AWS DMS构建数据湖
1. 引入数据湖使组织能够在更短的时间内利用多个源的数据,而不同角色用户可以以不同的方式协作和分析数据,从而实现更好、更快的决策。Amazon Simple Storage Service(amazon S3)是针对结构化和非结构化数据的高性能对象存储服务,可以用来作为数据湖底层的存储服务。然而许多...

Apache Hudi表自动同步至阿里云数据湖分析DLA
1. 引入Hudi 0.6.0版本之前只支持将Hudi表同步到Hive或者兼容Hive的MetaStore中,对于云上其他使用与Hive不同SQL语法MetaStore则无法支持,为解决这个问题,近期社区对原先的同步模块hudi-hive-sync进行了抽象改造,以支持将Hudi表同步到其他类型Me...
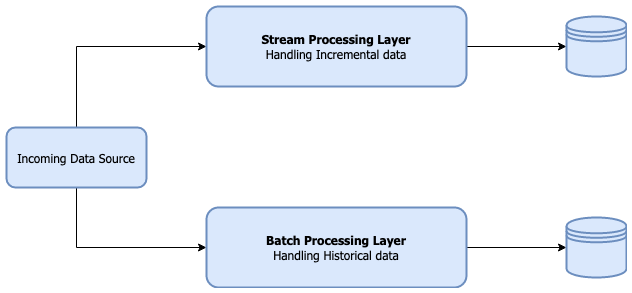
使用Apache Spark和Apache Hudi构建分析数据湖
1. 引入大多数现代数据湖都是基于某种分布式文件系统(DFS),如HDFS或基于云的存储,如AWS S3构建的。遵循的基本原则之一是文件的“一次写入多次读取”访问模型。这对于处理海量数据非常有用,如数百GB到TB的数据。但是在构建分析数据湖时,更新数据并不罕见。根据不同场景,这些更新频率可能是每小时...
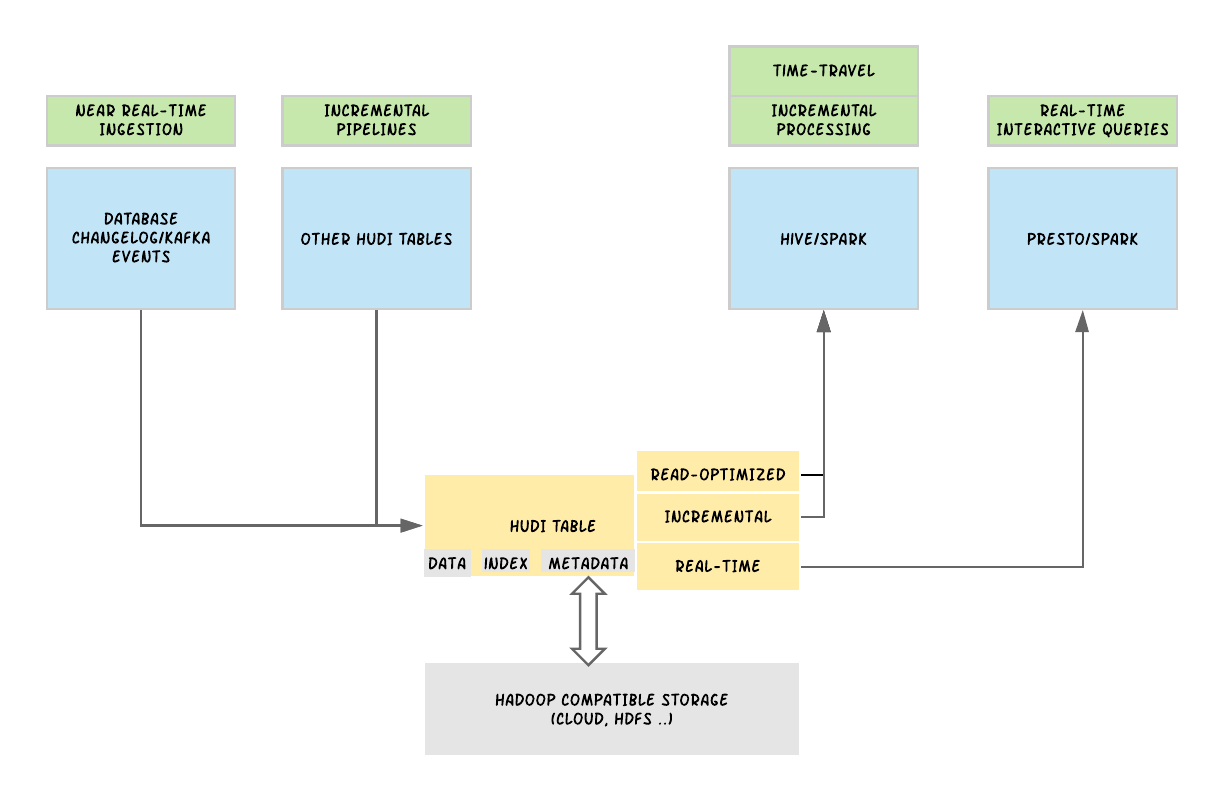
Uber基于Apache Hudi构建PB级数据湖实践
1. 引言从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全、无缝的运输和交付体验需要可靠、高性能的大规模数据存储和分析。2016年,Uber开发了增量处理框架Apache Hudi,以低延迟和高效率为关键业务数据管道赋能。一年后,我们开源了该解决方案,以使得其他有需要的组织也可以利...

使用 Flink Hudi 构建流式数据湖平台
摘要:本文整理自阿里巴巴技术专家陈玉兆 (玉兆)、阿里巴巴开发工程师刘大龙 (风离) 在 Flink Forward Asia 2021 的分享。主要内容包括:Apache Hudi 101Flink Hudi IntegrationFlink Hudi Use CaseApache Hudi Ro...
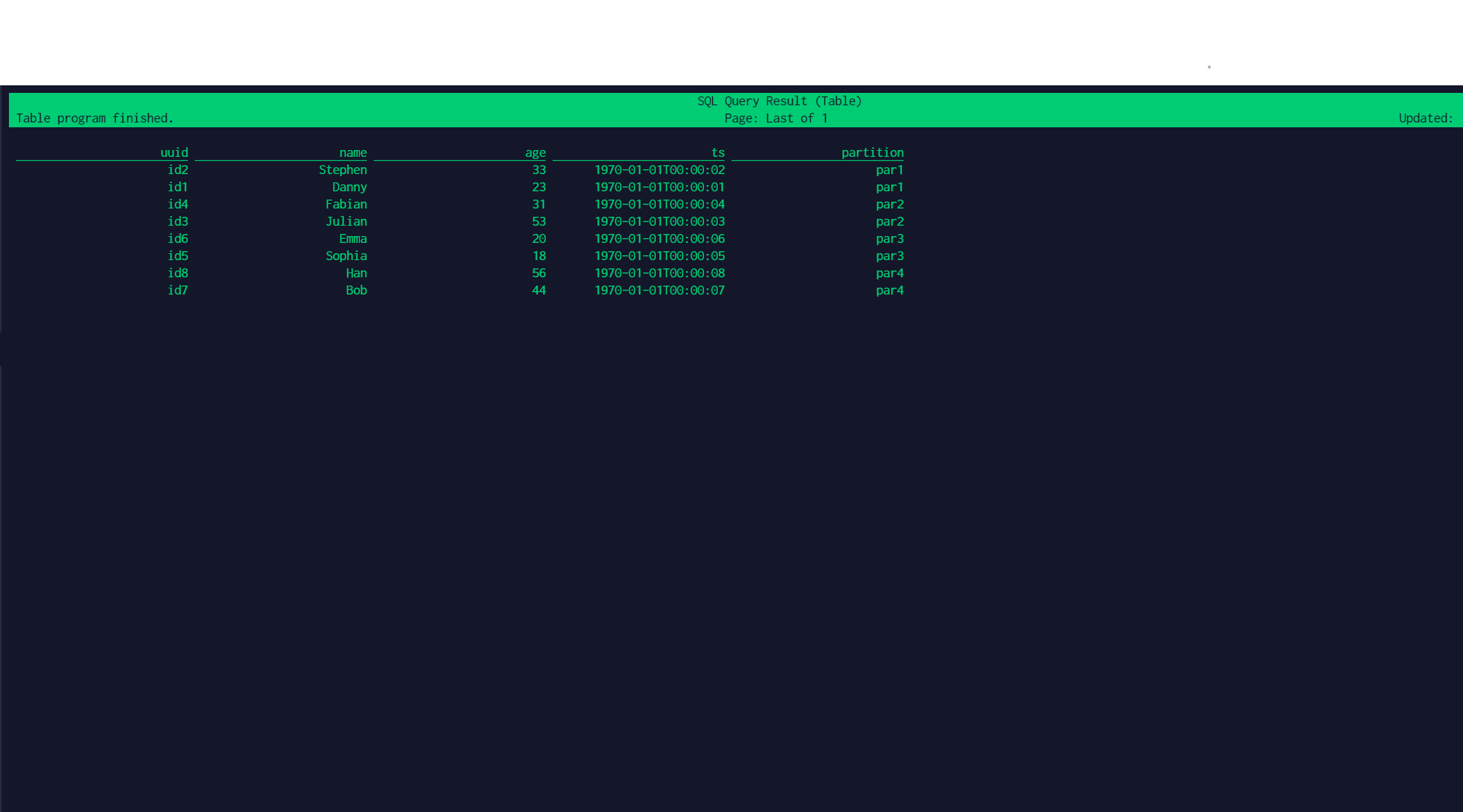
使用flink插入数据到hudi数据湖初探
环境:hadoop 3.2.0flink 1.11.4-bin-scala_2.11hudi 0.8.0本文基于上述组件版本使用flink插入数据到hudi数据湖中。为了确保以下各步骤能够成功完成,请确保hadoop集群正常启动。确保已经配置环境变量HADOOP_CLASSPATH对于开源版本had...

使用spark3操作hudi数据湖初探
环境:hadoop 3.2.0spark 3.0.3-bin-hadoop3.2hudi 0.8.0本文基于上述组件版本使用spark插入数据到hudi数据湖中。为了确保以下各步骤能够成功完成,请确保hadoop集群正常启动。确保已经配置环境变量HADOOP_CLASSPATH对于开源版本hadoo...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。